analysis of 6t finfet sram assist techniques and …djseo/classes/ee241/final...analysis of 6t...
TRANSCRIPT

Analysis of 6T FinFET SRAM Assist Techniques and Variability
Dongjin SeoFilip Maksimovic

2
Motivation
Sub-micron SRAM Scaling in CMOS is approaching a fundamental limit
Limitations include leakage, Ion/Ioff ratio, variability, etc.
One solution for further scaling is transition to non-bulk transistors: Multi-Gate Transistors
3
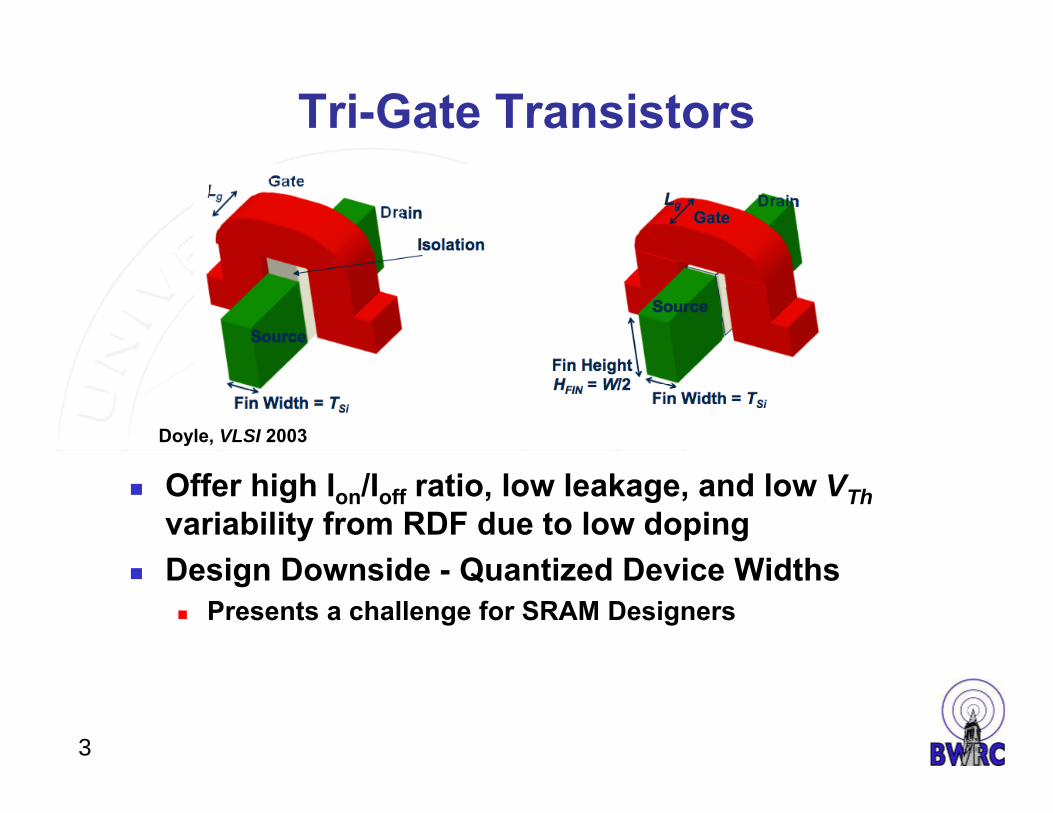
Tri-Gate Transistors
Offer high Ion/Ioff ratio, low leakage, and low VThvariability from RDF due to low doping
Design Downside - Quantized Device Widths Presents a challenge for SRAM Designers
Doyle, VLSI 2003

4
FinFET 6T SRAM
(a) (b) (c)
(a) High Density, high frequency, high power
(b) Low Density, low frequency, low power, more stable
Fundamental, Unavoidable Tradeoff
Karl, E. ISSCC 2012

5
Dynamic Margins
SNM is optimistic for write, pessimistic for read Dynamic Margin:
Dynamic Write Margin (DWM) Read Access Time (RAT)
DWM RAT

6
FinFET 6T SRAM Tradeoff
0100
200300
0100
200300
0
0.5
1
PU L
FinFET SRAM NFIN=1: Length Optimization (Read)
AX L
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
PU L
AX
L
50 100 150 200 250
50
100
150
200
2500.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1020
3040
1020
30400.7
0.8
0.9
1
PU TFIN
FinFET SRAM NFIN=1: TFIN Optimization (Read)
AX TFIN
0.75
0.8
0.85
0.9
0.95
1
PU TFIN
AX
TFI
N
15 20 25 30 35 40
15
20
25
30
35
40 0.75
0.8
0.85
0.9
0.95
1
50100
150200
50100
150200
0
0.5
1
PU L
FinFET SRAM NFIN=1: Length Optimization (Write)
AX L
0
0.2
0.4
0.6
0.8
1
PU L
AX
L
50 100 150 200 250
50
100
150
200
250 0
0.2
0.4
0.6
0.8
1
1020
3040
1020
3040
0.85
0.9
0.95
1
PU TFIN
FinFET SRAM NFIN=1: TFIN Optimization (Write)
AX TFIN
0.9
0.92
0.94
0.96
0.98
1
PU TFIN
AX
TFI
N
15 20 25 30 35 40
15
20
25
30
35
400.9
0.92
0.94
0.96
0.98
1
0100
200300
0100
2003000.2
0.4
0.6
0.8
1
PU L
FinFET SRAM NFIN=2: Length Optimization (Read)
AX L
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
PU L
AX
L
50 100 150 200 250
50
100
150
200
250 0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1020
3040
1020
3040
0.94
0.96
0.98
1
PU TFIN
FinFET SRAM NFIN=2: TFIN Optimization (Read)
AX TFIN
0.95
0.96
0.97
0.98
0.99
1
PU TFIN
AX
TFI
N
15 20 25 30 35 40
15
20
25
30
35
400.95
0.96
0.97
0.98
0.99
1
50100
150200
50100
150200
0
0.5
1
PU L
FinFET SRAM NFIN=2: Length Optimization (Write)
AX L
0
0.2
0.4
0.6
0.8
1
PU L
AX
L
50 100 150 200 250
50
100
150
200
2500
0.2
0.4
0.6
0.8
1
1020
3040
1020
3040
0.92
0.94
0.96
0.98
1
PU TFIN
FinFET SRAM NFIN=2: TFIN Optimization (Write)
AX TFIN
0.93
0.94
0.95
0.96
0.97
0.98
0.99
1
PU TFIN
AX
TFI
N
15 20 25 30 35 40
15
20
25
30
35
40 0.93
0.94
0.95
0.96
0.97
0.98
0.99
1
Write
Read

7
FinFET Variability
FinFET Vth less affected by Random Dopant Fluctuation (RDF) due to lightly-doped channel.
∆ ∆2
~ 0.5mV
∆ 0.5∙ 0
cosh 1∙∙ 0.5∙ 0
cosh ∙∙
Lu, D. IEEE DTC, 2010

8
Simulation Setup
BSIM: Common-gate Multi-Gate (CMG) Minimum Feature Size:
L=30nm, Tfin = 15nm, Hfin = 30nm 32x32 FinFET SRAM array
1FIN and 2FINs Pull-down NMOS 3σ variation: 14% change in L and Tfin.
Zhang. ISSCC, 2005
9
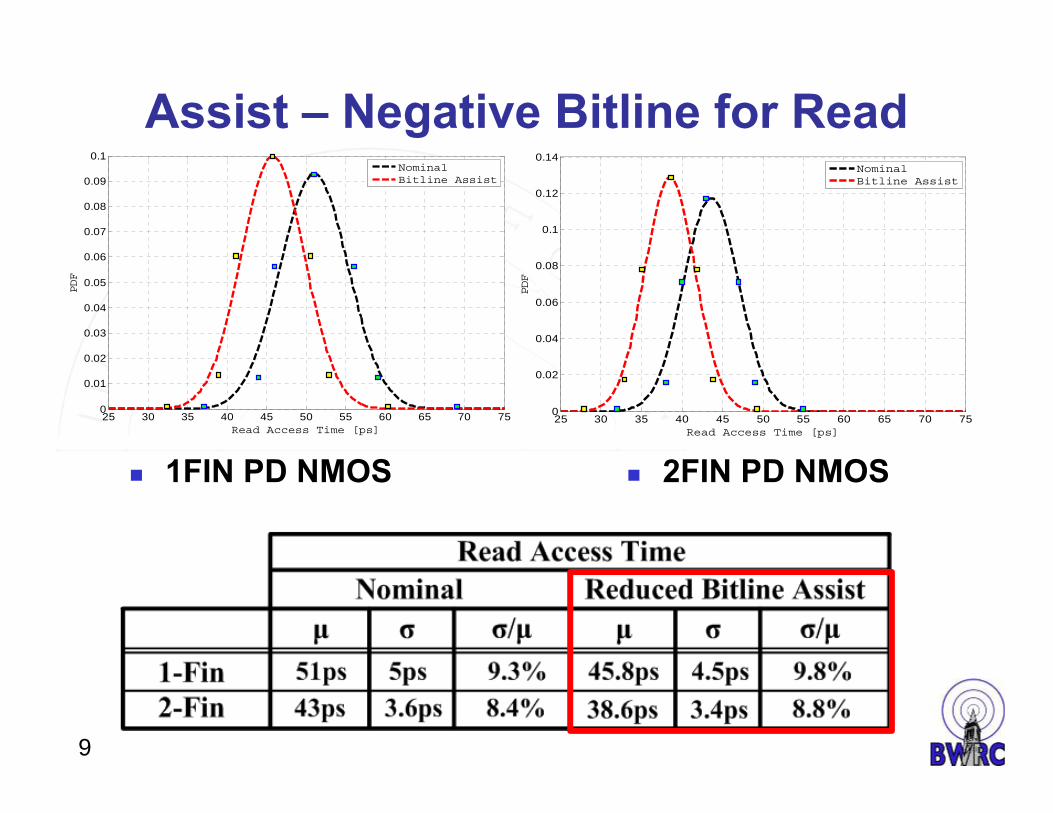
Assist – Negative Bitline for Read
25 30 35 40 45 50 55 60 65 70 750
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
Read Access Time [ps]
NominalBitline Assist
25 30 35 40 45 50 55 60 65 70 750
0.02
0.04
0.06
0.08
0.1
0.12
0.14
Read Access Time [ps]
NominalBitline Assist
1FIN PD NMOS 2FIN PD NMOS

10
Assist – Delayed Wordline Boost
50 60 70 80 90 100 110 1200
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Dynamic Write Margin [ps]
NominalDelayed WL BoostVDD Collpse
40 60 80 100 120 140 160 1800
0.005
0.01
0.015
0.02
0.025
0.03
0.035
0.04
Dynamic Write Margin [ps]
NominalDelayed WL BoostVDD Collpse
1FIN PD NMOS 2FIN PD NMOS

11
Assist – VDD Collapse
50 60 70 80 90 100 110 1200
0.01
0.02
0.03
0.04
0.05
0.06
0.07
Dynamic Write Margin [ps]
NominalDelayed WL BoostVDD Collpse
40 60 80 100 120 140 160 1800
0.005
0.01
0.015
0.02
0.025
0.03
0.035
0.04
Dynamic Write Margin [ps]
NominalDelayed WL BoostVDD Collpse
1FIN PD NMOS 2FIN PD NMOS

12
Conclusion
Examined variability of unassisted/assisted 1kbit FinFET SRAM.
The read time was reduced by 10% using suppressed bitline assist.
The write time was reduced by up to 39.3% using VDD collapse.

13
Acknowledgements
We would like to acknowledge SriramkumarVenugopalan and the BSIM group for providing us with preliminary FinFET models.

14
Questions?