a real-time primary-backup replication service
TRANSCRIPT

A Real-Time Primary-BackupReplication Service
Hengming Zou, Student Member, IEEE, and Farnam Jahanian, Member, IEEE
AbstractÐThis paper presents a real-time primary-backup replication scheme to support fault-tolerant data access in a real-time
environment. The main features of the system are fast response to client requests, bounded inconsistency between primary and
backup, temporal consistency guarantee for replicated data, and quick recovery from failures. The paper defines external and
interobject temporal consistency, the notion of phase variance, and builds a computation model that ensures such consistencies for
replicated data deterministically where the underlying communication mechanism provides deterministic message delivery semantics
and probabilistically where no such support is available. It also presents an optimization of the system and an analysis of the failover
process which includes failover consistency and failure recovery time. An implementation of the proposed scheme is built within the x-
kernel architecture on the MK 7.2 microkernel from the Open Group. The results of a detailed performance evaluation of this
implementation are also discussed.
Index TermsÐReal-time systems, fault tolerance, replication protocols, temporal consistency, phase variance, probabilistic
consistency.
æ
1 INTRODUCTION
WITH ever-increasing reliance on digital computers inembedded real-time systems for diverse applications
such as avionics, automated manufacturing and processcontrol, air-traffic control, and patient life-support monitor-ing, the need for dependable systems that deliver services ina timely manner has become crucial. Embedded real-timesystems are in essence responsive: They interact with theenvironment by ªreacting to stimuli of external events andproducing results, within specified timing constraintsº [17].To guarantee this responsiveness, a system must be able totolerate failures. Thus, a fundamental requirement of fault-tolerant real-time systems is that they provide the expectedservice even in the presence of failures.
Most real-time computer systems are distributed andconsist of a set of nodes interconnected by a real-timecommunication subsystem. Conceptually, a real-time com-puter system provides a set of well-defined services to the
environment. These services must be made fault-tolerant tomeet the availability and reliability requirements on theentire system. Therefore, some form of redundancy must beemployed for failure detection and recovery. This redun-dancy can take many forms: It may be a set of replicated
hardware or software components that can mask the failureof a component (space redundancy) or it may be a backwarderror recovery scheme that allows a computation to berestarted from an earlier consistent state after an error isdetected (time redundancy).
Two common approaches for space redundancy areactive (state-machine) and passive (primary-backup) replica-tion. In active replication, a collection of identical servers
maintain copies of the system state. Client write operationsare applied atomically to all of the replicas so that afterdetecting a server failure the remaining servers cancontinue the service. Passive replication, on the other hand,distinguishes one replica as the primary server, whichhandles all client requests. A write operation at the primaryserver invokes the transmission of an update message to thebackup servers. If the primary fails, a failover occurs andone of the backups becomes the new primary. In general,schemes based on passive replication are simpler and tendto require longer recovery time since a backup must executean explicit recovery algorithm to take over the role of theprimary. Schemes based on active replication do not have tobudget for this failover time. However, the overheadassociated with managing replication tends to slow downthe response to a client request since an agreement protocolmust be performed to ensure atomic ordered delivery ofmessages to all replicas.
While each of the two approaches has its advantages,neither directly solves the problem of accessing data in areal-time environment. Many embedded real-time applica-tions, such as computer-aided manufacturing and processcontrol, require timely execution of tasks and their ownprocessing needs should not be compromised by fault-tolerant access to data repositories. Therefore, it is im-portant for replicas to provide timely access to the service.In such a real-time environment, the scheme employed inmost conventional replication systems may prove insuffi-cient for the needs of applications. Particularly, when timeis scarce and the overhead for managing redundancy is toohigh, an alternative solution is required to provide bothtiming predictability and fault tolerance.
An alternative solution exploits the data semantics in aprocess-control system by allowing the backup to maintaina less current copy of the data that resides on the primary.The application may have distinct tolerances for the
IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 10, NO. 6, JUNE 1999 533
. The authors are with the Department of Electrical Engineering andComputer Science, The University of Michigan, Ann Arbor, MI 48109.E-mail: {zou, farnam}@eecs.umich.edu.
For information on obtaining reprints of this article, please send e-mail to:[email protected], and reference IEEECS Log Number 109048.
1045-9219/99/$10.00 ß 1999 IEEE

staleness of different data objects. With sufficient recentdata, the backup can safely supplant a failed primary; thebackup can then reconstruct a consistent system state byextrapolating from previous values and new sensor read-ings. However, the less current data copies on the backupmust be within a bounded range of the freshest data copiestolerable by the application. Such kind of bounded temporaldistance is called weak consistency.
For example, consider the process-control system shownin Fig. 1. A digital controller supports monitoring, control,and actuation of a chemical reactor. The controller softwareexecutes a tight loop, sampling sensors, calculating newvalues, and sending signals to external devices under itscontrol. It also maintains an in-memory data repositorywhich is updated frequently during each iteration of thecontrol loop. The data repository must be replicated on abackup controller to meet the strict timing constraint onsystem recovery when the primary controller fails. In theevent of a primary failure, the system must switch to thebackup node within a few hundred milliseconds. Sincethere can be hundreds of updates to the data repositoryduring each iteration of the control loop, it is impracticaland perhaps impossible to update the backup synchro-nously each time the primary repository changes.
One class of weak consistency semantics that is particu-larly relevant in a real-time environment is temporalconsistency, which is the consistency view seen from theperspective of the time continuum. Two objects or eventsare said to be temporally consistent with each other if theircorresponding timestamps are within a prespecified �bound. Two common types of temporal consistency are:external temporal consistency, which deals with the relation-ship between an object of the external world and its imageon the servers, and interobject temporal consistency, whichconcerns the relationship between different objects orevents. Both consistencies stem from requirements by realworld tasks. For example, when tracking the position of aplane, the data in the computer system must change within
some time bound (external temporal consistency) after theplane changes its physical position. When two planesapproach the same airport, the traffic control system mustupdate the positions of the two planes (interobject temporalconsistency) within a bounded time window to ensure thatthe airplanes are at a safe distance from each other.
This paper presents a real-time primary-backup (RTPB)replication scheme that extends the traditional primary-backup scheme to the real-time environment. It enforces atemporal consistency among the replicated data copies tofacilitate fast response to client requests and reducedsystem overhead in maintaining the redundant compo-nents. The design and implementation of the RTPBcombines fault-tolerant protocols, real time task scheduling,(external and interobject) temporal data consistency, opti-mization in minimizing primary-backup temporal distanceor primary CPU time in maintaining a given bound on suchdistance, deterministic or probabilistic consistency guaran-tee, and flexible x-kernel architecture to accommodatevarious system requirements. This work extends theWindow Consistent Replication first introduced by Mehra etal. [25]. The implementation is built within the x-kernelarchitecture on MK7.2 microkernel from the Open Group.1
We chose passive replication because it provides fasterresponse to client requests since no agreement protocol isexecuted to ensure atomic ordered delivery. Furthermore, itis also simpler and we want to experiment with newconcepts on a simple platform before extending it to morecomplex architecture. In fact, the RTPB is part of ourongoing research on the application of weaker consistencymodels to replica management. In a recent tech report, wehave examined a real-time active replication scheme with asimilar consistency model as the RTPB.
The rest of the paper is organized as follows: Section 2describes the RTPB model. Sections 3 and 4 define theconcepts of external and interobject temporal consistency,respectively. Section 5 explores the optimization problem.Section 6 analyzes the failover process of the RTPB. Section 7addresses implementation issues in our experience ofbuilding a prototype RTPB replication system, followedby a detailed performance analysis in Section 8. Section 9summarizes the related work. Section 10 is the conclusion.
2 SYSTEM MODEL AND ASSUMPTIONS
The proposed RTPB system consists of one primary and oneor more backups. The primary interacts with clients and isresponsible for keeping the backup(s) in weak consistencyusing the temporal consistency model developed in thispaper. Unlike the traditional primary-backup protocols, theRTPB model decouples client write operations from com-munication within the service, i.e., the updates at backup(s).Furthermore, external and interobject temporal consistencysemantics are defined and guaranteed at both the primaryand backup sites by careful coordination of the operationsat the primary and updates to the backups. Fig. 2 depictsthe composition of the servers.
534 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 10, NO. 6, JUNE 1999
Fig. 1. A replicated process control system
1. Open Group is formerly known as the Open Software Foundation(OSF).

As shown in the figure, the primary's object managerhandles client data requests and determines its merit, theupdate scheduler handles writes of the objects in thesystem, and the communication manager sends messagesto the backups at the behest of the update scheduler. Theoptimization daemon in the primary handles the optimiza-tion of the RTPB while the probability calculation daemonin the backup module computes the probability of temporalconsistency of the backup and is used to ensure aprobabilistic consistent failover in case of primary failure.Since read and write operations do not trigger transmis-sions to the backup hosts, client response time depends onlyon local operations at the primary, which can be handledmuch more effectively. This allows the primary to handle ahigh rate of client requests while independently sendingupdate messages to the backup replicas.
A client task periodically updates objects on the primary.The update must satisfy the external and interobjecttemporal constraint imposed on all objects in the system.The primary balances the demands of the client applica-tion's processing and the maintenance of consistent backupreplicas by selectively transmitting messages to the back-up(s). The primary goal of the RTPB is to determine thefrequency at which updates are sent to the backup such thatthe balance is achieved. The primary executes an admissioncontrol algorithm as part of object creation to ensure that theupdate scheduler can schedule sufficient update transmis-sions for any new object admitted such that the requiredtemporal consistency is achieved. Unlike client reads andwrites, object creation and deletion requires completeagreement between the primary and all the backups.
The RTPB system is designed to run under varioussystem conditions and can tolerate a wide range of faults.We assume that processes can suffer crash or performancefailures. (We don't assume Byzantine or arbitrary failures.)Send omissions and receive omissions are also allowed, e.g.,due to transient link failures, or discard by the receiver dueto corruption or buffet overflow. Permanent link failures(resulting in network partitions) are not considered. Webelieve that the proper way to handle permanent failures infault-tolerant real-time systems is to employ hardwareredundancy such as in TTP [16] or as suggested in [6].
If the fault mode is deterministic, i.e., the pattern andprobability of a fault occurring is known or can be bounded
due to support by the underlying communication infra-structure, the RTPB can exploit this feature to providedeterministic consistency guarantee for replicated datacopies. If the fault mode is nondeterministic, i.e., theprobability of a fault occurring is unknown or impossibleto model, the RTPB can degrade its guarantee of temporaldata consistency to be probabilistic.
3 EXTERNAL TEMPORAL CONSISTENCY
External temporal consistency concerns the relationshipbetween an object of the external world and its image on aserver. The problem of enforcing a temporal bound on anobject/image pair is essentially equivalent to that ofenforcing such a bound between any two successiveupdates of the object on the server. If the maximum timegap between a version of an object on the server and theversion of the object in the external world must be boundedby some �, then the time gap between two successiveupdates of the object on the server must be bounded by �
too, and vice versa. Hence, the problem of guaranteeing anobject's external temporal consistency is transformed to thatof guaranteeing a � bound for the time gap between twosuccessive updates of the object on the server. If we definetimestamp TPi �t�; TBi �t� at time t to be the completion timeof the last update of object i before or at time t at theprimary and backup, respectively, then the temporalconsistency requirement stipulates that inequalities tÿTPi �t� � �i and tÿ TBi �t� � �0i hold at all t, where �i and �0iare the external temporal constraints for object i at primaryand backup, respectively. The values of �i and �0i arespecified by the target applications. Hence, our taskbecomes to find the conditions that make the above twoinequalities hold at all times.
3.1 Consistency at Primary
Consistency at primary requires that inequality tÿ TPi �t� ��i holds at all times. Letting pi and ei denote the period andthe execution time of the task that updates object i atprimary, we have:
Lemma 1. tÿ TPi �t� � �i if pi � ��i � ei�=2.
Proof. In the worst case, a version of object i at the primarycould stay current for as long as 2pi ÿ ei time units before
ZOU AND JAHANIAN: A REAL-TIME PRIMARY-BACKUP REPLICATION SERVICE 535
Fig. 2. RTPB server composition.

the completion of the next update; hence, at any time
instant t, we have:
tÿ TPi �t� � 2pi ÿ ei � 2��i � ei�=2ÿ ei � �iut
To derive a necessary and sufficient condition for
ensuring external temporal consistency, we introduce the
notion of phase variance.
Definition 1. The kth phase variance vki of a task is the absolute
difference between the time gap of its kth and (kÿ 1)th
completion time, and its period pi, i.e.,
vki � j�fki ÿ fkÿ1i � ÿ pij; k � 1; 2; . . . ;1:
Definition 2. The phase variance vi of a task is the maximum
of its kth phase variance, i.e., vi � max�v1i ; v
2i ; v
3i ; . . .�.
Since any two consecutive completion times of a periodic
task is bounded between ei and 2pi ÿ ei, it follows
immediately from the definition of phase variance that:
vi � max�j�fki ÿ fkÿ1i � ÿ pij� � pi ÿ ei �3:1�
With the introduction of phase variance, we derive a
necessary and sufficient condition for guaranteeing external
temporal consistency for object i at primary:
Theorem 1. tÿ TPi �t� � �i iff pi � �i ÿ vi.
Due to space limitation, we omit the proof here. Refer to
http://www.eecs.umich.edu/~zou/paper/tpds.ps for
proofs of all subsequent theorems in this paper.
3.1.1 Bound on Phase Variance
The result of Theorem 1 is of little use if phase variance can
not be bounded by a bound that is better than the one given
by (3.1). Fortunately, we are able to derive better bounds on
phase variance for various scheduling algorithms:
Theorem 2. Phase variance is bounded by inequalities vi �xpi ÿ ei under Earliest Deadline First (EDF) [23] scheduling,
by inequality vi � �x:pi�=�n�21=n ÿ 1�� ÿ ei under Rate-
Monotonic Scheduling (RMS) [23], and by inequality vi �Ri ÿ ei under Response Time Analysis [8], [33] scheduling.2
Here, n is the number of tasks on the processor, x is the
utilization rate, and Ri is the response time of the task that
updates object i.
The Response Time Analysis approach provides a tighter
bound on phase variance than RMS if the response time of
each task is shorter than its corresponding period. We
included RMS in our analysis because of its wide use in
practice. We also note that if a task runs less than its worst
case execution time, the bound on phase variance is looser,
which will affect the temporal consistency guarantees. But
such a problem can be addressed by using the best
execution time in the above formulae.
From Theorems 1 and 2, we conclude that the restriction
on an object can be significantly relaxed if the utilization
rate of a task set is known. It can also be shown that if the
number of objects whose external temporal consistency we
want to guarantee is less than the number of tasks in the
task set, the bound on phase variance can be further
tightened. The formula that takes into account the number
of objects for which we want to guarantee temporal
consistency is straightforward to derive.
3.1.2 Zero Bound on Phase Variance
Thus far, we have demonstrated that phase variance can
indeed be bounded by some known number. In fact, we can
ensure that the phase variance is exactly zero in most cases
through a direct application of the schedulability results
from Distant-Constrained Scheduling (DCS) [13]. The DCS
algorithm is used to schedule real-time tasks in which
consecutive executions of the same task must be bounded,
i.e., the finish time for one execution is no more than � time
units apart from the next execution. Consider a task set
T � T1; T2; . . . ; Tn. Suppose ei and ci denote the execution
time and distance constraint of task Ti, respectively, and
any two finish of task Ti is bounded by ci. Han and Lin [13]
have shown that the task set can be feasibly scheduled
under scheduler Sr ifPn
i�1 ei=ci � n�21=n ÿ 1�.If we substitute pi for ci, then each finish of task Ti
occurs at exactly the same interval pi after some number of
iterations (could be 0). This can be proven by contra-
diction: If the completion time of consecutive invocations
is not exactly pi apart, then the difference between two
consecutive completion times must become smaller and
smaller as time advances (because no two completion
times can be more than pi apart). Eventually, there will be
at least two consecutive completion times within a single
period, which is impossible. Thus, the phase variance of
task Ti in this case is j�fki ÿ fkÿ1i � ÿ pij � jpi ÿ pij � 0.
Combining with the result of Theorem 1, we conclude
that ifPn
i�1 ei=pi � n�21=n ÿ 1�, the condition to guarantee
external temporal consistency for an object is relaxed to
that of ensuring that the period of the task updating the
object is bounded by the external temporal constraint
placed on the object.
3.2 Consistency at Backup
The temporal consistency at the backup site is maintained
by the primary's timely sending of update messages to the
backup. Our interest here is to find out at what frequency
the primary should schedule update messages to the
backup such that inequality tÿ TBi �t� � �0i holds at all
times. Let p0i, e0i, and v0i denote the period, the execution
time, and the phase variance of the task that updates object i
at backup, respectively, and ` is the communication delay
from primary to backup. We have:
Theorem 3. A sufficient condition for guaranteeing external
temporal consistency for object i at backup is
p0i � ��0i � ei � e0i ÿ `�=2ÿ pi. A necessary and sufficient
condition for such guarantee is p0i � �0i ÿ v0i ÿ pi ÿ vi ÿ `.
536 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 10, NO. 6, JUNE 1999
2. An exposition of scheduling algorithms is beyond the scope of this paper;refer to the references for details.

If we choose pi to be the largest value that satisfies theexternal temporal constraint of object i at the primary, i.e.,pi � �i ÿ vi, we obtain:
p0i � �0i ÿ v0i ÿ ��i ÿ vi� ÿ vi ÿ ` � ��0i ÿ �i� ÿ v0i ÿ `:Moreover, if v0i � 0, the above formula is simplified to
p0i � ��0i ÿ �i� ÿ `. Let � denote �0i ÿ �i. We see that in order toguarantee external temporal consistency for object i at thebackup, an update message from the primary to the backupmust be sent within the next � ÿ ` time units after thecompletion of each update on the primary. This is identicalto the window-consistent protocol proposed by Mehra et.al. [25]. Here, � is the window of inconsistency (or windowconsistent bound) between the primary and backup.
4 INTEROBJECT TEMPORAL CONSISTENCY
Interobject temporal consistency concerns the relationshipbetween different objects or events. If one object is related toanother in a temporal sense, then a temporal constraintbetween the two objects must be maintained. For example,when two planes approach the same airport, the trafficcontrol system must update the positions of the two planeswithin a bounded time window to ensure that the airplanesare at a safe distance from each other. If �ij is the interobjecttemporal constraint between object i and j, the interobjecttemporal consistency requires that inequalities jTPj �t� ÿTPi �t�j � �ij and jTBj �t� ÿ TBi �t�j � �ij hold at all times.
Theorem 4. A necessary and sufficient condition to guaranteeinterobject temporal consistency between object i and j ispi � �ij ÿ vi, pj � �ij ÿ vj at primary, and p0i � �ij ÿ v0i, p0j ��ij ÿ v0j at backup.
The correctness of the theorem is intuitive. Since any twoconsecutive completion times of one task that meet thecondition are bound by the temporal constraint, any twoneighboring completion times of two tasks that meet thesame condition are bound by the temporal constraint, too.
If the phase variances in the above formulae are madezero by DCS scheduling, then the conditions stated inTheorem 4 are simplified to:
pi � �ij; and pj � �ij for the primary
p0i � �ij; and p0j � �ij for the backup
which means that the interobject temporal constraintbetween object i and j at both the primary and backupcan be maintained by scheduling the two updates (forobjects i and j, respectively) within a bound of �ij timeunits.
5 OPTIMIZATION
The previous two sections developed conditions that ensuretemporal consistency for any object in the system. Suchconsistency effectively bounds the temporal distance (time-stamp difference) between an object on the primary and thecorresponding copy on the backup. However, the discus-sion does not minimize such a distance nor the primary'sCPU overhead used in maintaining a given bound on it.
This section explores ways to optimize the system fromthese two perspectives.
5.1 Definitions
First, we define temporal distance. If we timestamp eachdata copy on both the primary and backup, then at anygiven time instant t, the difference between the timestampof object i at the primary and the timestamp of the sameobject at the backup is the temporal distance of object i in thesystem. We define the overall temporal distance of the systemto be the arithmetic average of the temporal distance of eachobject.
Definition 3. The temporal distance for object i at time t isjTPi �t� ÿ TBi �t�j. The overall temporal distance of the systemat time t is
Pni�1 jTPi �t� ÿ TBi �t�j=n, where n is the total
number of objects registered in the replication service.
From another perspective, temporal distance can be seenas the data inconsistency for object i between the primaryand the backup. The overall temporal distance can thereforebe seen as the overall data inconsistency of the system. If theoverall temporal distance is within some prespecified �, wecall the backup temporally consistent with respect to theprimary. The definition of temporal distance also suggests away to compute its value. To compute the temporaldistance for a single object i at any time, we need to findout the time instants at which object i was last updated onthe primary and backup and take the absolute difference ofthese two timestamps. To compute the overall temporaldistance of the system at any time, we compute thetemporal distance for each object and take their arithmeticaverage.
5.2 Minimizing Temporal Distance
Observe that the more frequently updates are sent tobackup, the smaller the temporal distance will be. Thus, ifthe period of the updates sent to backup for each object isminimized, the overall temporal distance between theprimary and backup is also minimized. Furthermore, theminimization of the update period at the backup for eachobject results in the minimization of the sum of the updateperiods for all objects and vice versa. Hence, our firstattempt is to use the sum of the update periods for allobjects as our objective function. Then the optimizationproblem can be stated as:
minimize:Pp0i
subject to:Pn
i�1�e0i=p0i � ei=pi� � 2n�21=2n ÿ 1�and pi � p0i � �0i; i � 1; 2; . . . ; n
The first constraint ensures task schedulability underboth RMS [23]and DCS [13]. But the optimization problemcan also be phased to use other scheduling algorithms. Forexample, if we use EDF, this constraint is changed toPn
i�1�e0i=p0i � ei=pi� � 1. If we use Response Time Analysis[8], [33], the constraint is changed to
8i; e0i �Xj2hp�i�
�dR0i=p0jee0j � dR0i=pjeej� � p0i;
where hp�i� denotes the set of tasks that have a higherpriority than the task updating object i. In our subsequent
ZOU AND JAHANIAN: A REAL-TIME PRIMARY-BACKUP REPLICATION SERVICE 537

discussions, we only use RMS and DCS scheduling for thereason that RMS is the most commonly used schedulingalgorithm in practice, while DCS can provide a tight boundon phase variance.
The inequality p0i � �0i ensures that the temporal con-straint imposed on object i at the backup is maintained,while inequality pi � p0i guarantees that no unnecessaryupdate is sent to the backup since more frequent updates atbackup would not make any difference when there is nomessage loss between servers. However, such formulationof the optimization problem is not very useful in practicebecause it is not in a normalized form and the solutions to itare skewed towards the boundaries. In other words, formost objects (actually all objects except one), the period iseither very high or very low, which means for certainobjects, the respective temporal distances between primaryand backup are not optimized at all. For example, if wehave four objects in the system with
ei � e0i � f1; 2; 3; 4g;pi � f10; 20; 30; 40g;�0i � f50; 50; 60; 70g;
respectively, then the minimization ofPp0i is achieved
if p0i � f50; 20; 30; 40g. All values in the p0i vector are onthe boundaries (skewed solution) in the constraintinginequalities.
In fact, we can show that if an optimal solution exists forthe above optimization problem, there is exactly one objectthat has its period strictly bounded between the boundariesgiven in the constraining inequalities. Indeed, we cangeneralize this observation to the following theorem:
Theorem 5. The optimal solution in minimizingPn
i�1 cixisubject to
Pni�1 aixi � b, li � xi � ui i � 1; . . . ; n has at most
one of the variables bounded strictly between its lower andupper boundaries.
This analysis necessitates a need to find a normalizedobjective function whose solutions are not skewed towardany extreme. One suitable alternative is the maximizationof min�p1=p
01; p2=p
02; . . . ; pn=p
0n�. This objective function is
simple and its solution can be easily found by a polynomialtime algorithm. Furthermore, all the periods are propor-tionally made as small as possible without skew. Now theoptimization problem can be formulated as:
maximize: min�p1=p01; p2=p
02; . . . ; pn=p
0n�
subject to:Pn
i�1�e0i=p0i � ei=pi� � 2n�21=2n ÿ 1�and pi � p0i � �0i; i � 1; 2; . . . ; n
The proof that the above function indeed minimizestemporal distance is beyond the scope of this paper.However, its correctness can be explained intuitively asfollows: Since the maximization of the minimum of �pi=p0i�minimizes the update transmission period p0i proportionallyto its corresponding update period at the primary, theoverall update frequency at the backup is thereforeproportionally maximized, which results in the minimiza-tion of temporal distance.
The above formulation states that to minimize temporaldistance, one needs to minimize the maximum period of the
update tasks for the object set subject to both schedulability
and temporal constraint tests. We distinguish between static
and dynamic allocation in designing a polynomial time
algorithm that achieves this objective. Static allocation deals
with the case where the set of objects to be registered are
known ahead of time. The goal is to assign the update
scheduling period for each object such that the value of the
object function is maximized. Dynamic allocation deals with
the case where a new object is waiting to be registered in a
running system in which a set of objects have already been
registered.
5.2.1 Static Allocation
Since all objects are know a priori, the algorithm for
scheduling updates from primary to backup is relatively
straightforward:
1. Assign p0i � �0i initially2. Perform schedulability test using RMS [23] or DCS [13]. Ifit fails, then it is impossible to schedule the task set withoutviolating the given temporal constraint.3. Otherwise, sort terms pi=p
0i into ascending order.
4. Shorten period p0i of the first term in the ordered list untilit either becomes the second smallest term, or reaches thelower bound pi, or the utilization rate of the whole task setis saturated.5. Repeat steps 3-4 until the utilization becomes saturated orall ratios become 1.
Note that steps 3-4 can be implemented efficiently by
binary insertion which is bounded by logn, and the running
time of the algorithm is dominated by the number of
iterations of steps 3-4, which is bounded by
�max�pi=p0i� ÿmin�pi=p0i��2;the total running time of the algorithm is
O��max�pi=p0i� ÿmin�pi=p0i��2 � logn�:
5.2.2 Dynamic Allocation
A new object is being registered with a system in which
other objects have already been checked in. We want to find
out if the new object can be admitted and at what frequency
we can optimally schedule its update task. We can pursue
either a local optimum or global optimum with the
difference being that local optimum algorithm does not
adjust the periods of tasks that are already admitted and
global optimum algorithm considers all tasks in devising an
optimal scheduling.
Local optimal
1. Assign the smallest value that is � pi but � �0i to the newtask such that the total utilization of the task set is stillunder 2n�21=2n ÿ 1� (this ensures that the whole task set isschedulable under RMS and DCS).2. If step 1 fails, then reject the new object.
Global optimal
1. Insert term pi=p0i into the ordered list that we obtained in
static or previous allocations.
538 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 10, NO. 6, JUNE 1999

2. Rerun the static allocation algorithm.3. If step 2 fails, then reject the new object.
The running time for local optimum algorithm is linear(with respect to the number of objects). The time complexityfor the global optimum algorithm is the same as that of thestatic allocation algorithm which is polynomial.
5.3 Minimizing Primary CPU Overhead
This section discusses the optimization problem of mini-mizing primary CPU time used in scheduling updates tothe backup. The observation is that the less frequentlyupdates are sent to backup, the less primary CPU overheadwill be. Hence, the minimization of primary CPU overheadcan be achieved by minimizing the number of updates sentto the backup, which is equivalent to the maximization ofthe periods of the update tasks (under the given temporaldistance bound). We assume that the transmission of anupdate message of any object takes the same amount ofprimary CPU time.
Note that the bound on temporal distance can beconverted to a bound on the periods of the updating tasks.If we normalize the period of each update task with thedenominator �i ÿ pi, the given bound on temporal distancecan be transformed to inequality
Pp0i=��i ÿ pi� � B, where
B is some positive constant derived from the givenconstraint on temporal distance. Observe that we do notneed to know the actual value of B. The important thinghere is that B can be derived from the bound on temporaldistance. Thus, our optimization can be formulated as:
maximize:Pn
i�1 p0i
subject to:Pn
i�1 p0i=��i ÿ pi� � B
and pi � p0i � �0iThe following is a polynomial time algorithm for theproblem:
1. For each object, assign period: p0i � �0i.2. Perform schedulability test. If the test fails, then wecannot guarantee the temporal consistency of the object set.Reject the object set.3. Otherwise, compute X �P p0i=��i ÿ pi�.4. If X � B, then we are successful. So we stop here.5. Shorten the p0is proportionally such that the value of thesummation is reduced by the amount of X ÿB.6. Perform schedulability test again. If it fails, then reject theobject set. Otherwise, we have succeeded in devising anoptimal scheduling.
The rationale behind the algorithm is that to minimizeprimary CPU overhead in maintaining the given temporalbound on temporal distance, we simply schedule as fewupdates to the backup as possible for each object subject tothe individual temporal constraint and the overall temporaldistance bound. The running time of the above algorithm islinear.
If we relax the value �0i such that it can be unbounded, i.e.we take out the constraint p0i � �0i, the problem becomesintractable. If fact, we have:
Theorem 6. maximizingPn
i�1 p0i under constraintPn
i�1 p0i=��i ÿ pi� � B is NP-complete.
5.4 Optimization under Message Loss
The discussion on RTPB optimization so far does not takeinto consideration message loss. Update messages fromprimary to backup can be lost due to sender omission,receiver omission, or link failure. This section devises amodified scheduling protocol that takes into accountmessage loss. We define the probability of a message lossfrom primary to the backup to be �, and the probability ofthe temporal consistency guarantee we want to achieve tobe P . Then for an update to reach backup with probabilityP , the number of transmissions needed is log�1ÿ P �= log���.Hence, the problem of minimizing temporal distance of thesystem can be formulated as:
maximize: min��pi log����=�p0i log�1ÿ P ���subject to:
Pni�1�e0i=p0i � ei=pi� � 2n�21=2n ÿ 1�
and �pi log����= log�1ÿ P � � p0i � �0iThe goal is to send updates to the backup more
frequently in case of a message loss. The frequency ofupdate transmissions can be increased up to the frequencyat which any update will reach the backup with probabilityP . The maximization of the minimum term in the objectivefunction results in the overall minimization of periods of theupdate tasks, which consequently results in the minimiza-tion of temporal distance with probability P . The con-straints in the formulation ensure schedulability whilemaintaining temporal consistency for each individual objectand avoiding unnecessary updates to the backup. Withproper substitution of terms, the same algorithm introducedbefore can be applied here. Due to space limitations, weomit it.
Similarly, the minimization of primary CPU overhead inmaintaining a given bound on temporal distance whenmessage loss occurs becomes:
maximize:Pn
i�1 p0i
subject to:Pn
i�1 p0i log�1ÿ P �=�log ���i ÿ pi�� � B
and p0i � �0i log���= log�1ÿ P �Again, the algorithm in the previous section can be used
here with proper parameter substitution.
6 FAILOVER IN RTPB
A failover occurs when the backup detects a primaryfailure. In such a case, the backup initiates a failoverprotocol and takes over the role of the primary with thenecessary state updates and notification of clients. There aretwo aspects concerning a failover: the qualitative aspect andthe quantitative aspect. The former deals with the questionof ªhowº to detect a failure and ªrecoverº from it. The latterdeals with the two quantitative aspects of a failover: failoverconsistency and failure recovery time.
The approach to failure detection and recovery is to letthe replicas exchange periodic ping messages. Each serveracknowledges the ping message from the other one. If aserver receives no acknowledgment over some time, it willtimeout and resend a ping message. If there is no responsebeyond a certain amount of time, the server will declare theother end dead. When the primary detects a failure on the
ZOU AND JAHANIAN: A REAL-TIME PRIMARY-BACKUP REPLICATION SERVICE 539

backup, nothing happens to the clients since the primaryonly cancels the update transmissions to the backup whileits service to clients continues uninterrupted. If the backupdetects a crash in the primary, it initiates a failover protocolin which it notifies the clients of such an event, modifies thenecessary system parameters to reflect this change, andstarts to serve clients.
The quantitative aspect of a failover concerns twoquestions. The first question is: Is the new primary after afailover procedure temporally consistent with respect to theold primary immediately before its crash? If we can'tanswer this question for certain, can we compute theprobability that once the failover is complete, the newprimary is temporally consistent? Such a question islegitimate because it is important for us to know the stateof the new primary after a failover so that we can assess thequality level of its service and take proper measures ifnecessary. The second question is: How long does it take fora failover procedure to complete? A timing measurementfor the recovery is important because we want to minimizethe impact of a failure on the clients. We address the twoaspects separately below.
6.1 Probability of Failover Consistency
The probability of failover consistency concerns the like-lihood that upon the completion of a failover, the newprimary (old backup) is temporally consistent with respectto all the objects of the old primary at the time of its crash. Itis straightforward to see that the probability of a consistentfailover is equivalent to the probability of backup consis-tency at the time when the failover starts. Suppose thebackup detects a primary failure at time t, then theprobability that the backup is temporally consistent withrespect to the old primary at time t is what we are lookingfor.
If everything works properly, then RTPB ensures that thebackup is temporally consistent with respect to the primaryat all times. So the probability of failover consistency is 1.However, in case of random faults where messages can belost with unknown probability, the calculation of temporalconsistency of the backup at any point in time t becomesimportant. If tiu is the timestamp of the last update for objecti on the backup before time t, then the probability that thebackup's copy of object i falls out of temporal consistencywith its counterpart on the primary at time t is theprobability that an update occurred at the primary duringtime interval �tiu; tÿ ��, where � is the temporal constraintbetween primary and backup.
We should note that if tiu � tÿ �, then there could nothave been any update occurring at the primary for object iduring the time interval in question. Hence, the probabilityof temporal consistency of the backup with respect to objecti is 1. If tiu � pi � tÿ �, then it is certain that an updateoccurred at the primary because the update at the primaryis periodic with period pi. Hence, the probability oftemporal consistency of the backup with respect to objecti is 0.
Otherwise, since the primary updates its object periodi-cally and the update is random and uniformly distributedwithin each period, the probability of an update for object ioccurring at the primary during time interval �tiu; tÿ �� is
�tÿ � ÿ tiu�=pi. Thus, the probability that the backup istemporally consistent with respect to object i at time t is1ÿ �tÿ � ÿ tiu�=pi. Letting Pi�t� denote such probability, wehave:
Pi�t� �1 tÿ � � tiu0 tÿ � � tiu � pi1ÿ �tÿ � ÿ tiu�=pi otherwise:
8<: �6:1�
If there are n objects in the system and P �t� denotes theprobability that the backup is temporally consistent withrespect to every object in the primary at time t, then wehave: P �t� �Qn
i�1 Pi.Now that we have derived the probability of temporal
consistency of the backup at any given time instant t, wecan determine the probability of a consistent failover. If thebackup discovers that the primary is crashed at time t, itimmediately takes over the role of the primary and starts toserve the clients. Assume the time it takes for the backup todeclare its substitution as the new primary is negligible,then the probability of a consistent failover is the same asthat of temporal consistency of the backup with respect tothe old primary at time t, which can be computed accordingto (6.1).
6.2 Failure Recovery Time
The detection and recovery time from a primary crash is animportant factor in determining the quality of a primary-backup replication system. The detection time is the timeinterval between the instant a server is crashed and theinstant that the crash is detected. The recovery time is thetime interval between the instant that a crash is detectedand the instant that service is resumed.
The shortest time interval between a primary crash andthe detection of this event by the backup is the number ofmaximum tries of sending the ping message by the backupsminus 1, multiplied by round-trip latency 2`. If the numberof tries is n, then the shortest time of detection is 2�nÿ 1�`and the longest time interval of detection is 2n`. Hence, thefailure detection time td is bounded between 2�nÿ 1�` and2n`. The recovery time is a little trickier to compute. In ourdesign, after the detection of primary failure, the backupsimply starts a backup version of the applications and up-loads the state information, and then starts to serve again.The major component of the recovery time is the time that ittakes to upload the state information, which is dependenton the size of the state information. In general, the totaldetection and recovery time is dominated by the detectiontime. Therefore, we can use the upper bound of thedetection time to approximate the failure detection andrecovery time, which is 2n`.
6.3 Probabilistic RTPB
We can use the probability computation described in theprevious sections to build a modified RTPB that provides aprobabilistic data consistency guarantee when the primaryfails. Since the computation of the probability of backupconsistency is independent of the fault patterns of thecommunication substructure, such a consistency guaranteeholds regardless of the service provided by the lower layers.To achieve such a guarantee, the backup needs to perform
540 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 10, NO. 6, JUNE 1999

an additional task when primary failure is detected. Beforeinitiating the failover process, the backup computes theprobability of its temporal consistency with respect to theprimary immediately before crash and takes one of thefollowing two actions depending on the requirementimposed by the applications.
If a probability threshold is specified by the application,the backup, after becoming the new primary, automaticallydenies service to clients if the probability of consistencycomputed is less than the given threshold and resumesservices only after new updates are received. Hence, if theclient receives a service, it can be assured that the service istemporally consistent with the probability of at least thegiven threshold. If no probability threshold is given, thenthe backup simply notifies the clients of the probability oftemporal consistency and lets the clients determine thegoodness of the service.
7 PROTOTYPE IMPLEMENTATION
7.1 Environment and Configuration
Our system is implemented as a user-level x-kernel-basedserver on the MK 7.2 microkernel from the Open Group.The x-kernel is a protocol development environment whichexplicitly implements the protocol graph [14]. The protocolobjects communicate with each other through a set of x-kernel uniform protocol interfaces. A given instance of thex-kernel can be configured by specifying a protocol graphin the configuration file. A protocol graph declares theprotocol objects to be included in a given instance of the x-kernel and their relationships.
We chose the x-kernel as the implementation environ-ment because of its several unique features. First, itprovides an architecture for building and composingnetwork protocols. Its object-oriented framework promotesreuse by allowing construction of a large network softwaresystem from smaller building blocks. Second, it has thecapability of dynamically configuring the network software,which allows application programmers to configure theright combination of protocols for their applications. Third,its dynamic architecture can adapt more quickly to changesin the underlying network technology [27].
Our system includes a primary server and a backupserver which are hosted on different machines that areconnected by a 100MB fast ethernet. Both machinesmaintain an identical copy of the client application.3
Normally, only the client on the primary is active, whilethe client copy on the backup host is dormant. The clientcontinuously senses the environment and periodicallysends updates to the primary. The client accesses the serverusing Mach IPC-based interface (cross-domain remoteprocedure call). The primary is responsible for backing upthe data on the backup site and limiting the inconsistency ofthe data between the two sites within some specified
window. Fig. 3 shows the RTPB system architecture and x-kernel protocol stack.
At the top level is the RTPB application programminginterface, which is used to connect the outside clients to theMach server on one end and Mach server to the x-kernel onthe other end. Our real-time primary-backup (RTPB)protocol sits right below the RTPB API layer. It serves asan anchor protocol in the x-kernel protocol stack. Fromabove, it provides an interface between the x-kernel and theoutside host operating system, OSF Mach in our case. Frombelow, it connects with the rest of the protocol stackthrough the x-kernel uniform protocol interface. Theunderlying transport protocol is UDP. Since UDP does notprovide reliable delivery of messages, we need to useexplicit acknowledgments when necessary.
The primary host interacts with the backup host throughthe underlying RTPB protocol that is implemented insidethe x-kernel protocol stack (on top of UDP, as shown inFig. 3). There are two identical versions of the clientapplication residing on the primary and backup hostsrespectively. Normally, only the primary client applicationis running. But, when the backup takes over in case ofprimary failure, it also activates the backup client applica-tion and brings it up to the most recent state. The clientapplication interacts with the RTPB system through theMach API interface we developed for the system.
7.2 Admission Control
Before a client starts to send updates of a data object to theprimary periodically, it first registers the object with theservice so that the primary can perform admission controlto decide whether to admit the object into the service.During registration, the client reserves the necessary spacefor the object on the primary server and on the backupserver. In addition, the client specifies the period it willupdate the object pi as well as the temporal constraintallowed for the object on both the primary site and thebackup site, where the temporal constraint specified by theclient is relative to the external world. The consistencywindow between the external data object i and its copy onthe primary is �i. Because primary's copy of object i changesonly when the client sends a new update, the inconsistencybetween the external data and its image on the primary isdependent on the frequency of client updates. Hence, it isthe responsibility of the client to send updates frequentlyenough to make sure the primary has a fresh copy of thedata.
The primary compares the value of �i and pi. If pi � �i,then the inconsistency between the external data and theprimary copy will always fall into the specified consistencywindow. If the condition does not hold, the primary will notadmit the object. The primary can provide feedback so thatthe client can negotiate for an alternative quality of service.
Given the temporal constraint for object i on the primary�i and the constraint on the backup �0i, the consistencywindow for object i between the primary and the backupcan be calculated as �0i ÿ �i. Let ` be the average commu-nication delay between the primary and the backup. If theconsistency window is less than `, then it is impossible tomaintain consistency between the primary and backupservers. Therefore, during the registration of object i, the
ZOU AND JAHANIAN: A REAL-TIME PRIMARY-BACKUP REPLICATION SERVICE 541
3. The RTPB model allows stand alone clients as well as clients that runon the same machine as the server replicas. What we mean by client here isthe code that reads/modifies the data objects. One can view the latter modeas replicating the application that accesses the data objects. The currentimplementation supports this mode of operation, i.e., the client applicationruns on the RTPB servers. The implementation can be easily modified tohandle requests from remote clients.

primary will check if relation �0i ÿ �i > ` holds for object i. If
the relation does not hold, the primary rejects the object.After testing that the temporal consistency constraints
hold for object i, the primary needs to further check if it can
schedule a periodic update event (to the backup) for object i
that will meet the consistency constraint of the object on the
backup without violating the consistency constraints of all
existing objects. For example, the primary will perform a
schedulability test based on the rate-monotonic scheduling
algorithm [23]. If all existing update tasks as well as the
newly added update task for object i are schedulable, the
test is successful. Otherwise, the object is rejected.Each interobject temporal constraint is converted into
two external temporal constraints according to the results
derived in Section 4. Specifically, given objects i and j and
their interobject temporal constraint �ij, their interobject
temporal bound can be met at the primary if pi � �ij,pj � �ij, and the schedulability test are successful. This same
constraint can be met at the backup as long as the constraint
�ij is sufficiently large such that the primary can schedule
two new update tasks that periodically send update
messages to the backup without violating the temporal
constraints of any existing object that is registered with the
replication service.After both the schedulability and temporal constraint
tests, the primary also needs to perform a network
bandwidth requirement test. The primary computes the
system's bandwidth requirement B, using a number of
parameters including the number of objects, their sizes, and
the frequency at which updates for these objects are sent to
the backup. Then it compares the value of B with the
available network bandwidth to the system. If B is
satisfiable, the object is admitted; otherwise it is rejected.
7.3 Update Scheduling
In our model, client updates are decoupled from theupdates to the backup. The primary needs to send updatesto the backup periodically for all objects admitted in theservice. It is important to schedule sufficient updatetransmissions to the backup for each object in order tocontrol the inconsistency between the primary and thebackup. In the absence of link failures, ` is the averagecommunication delay between the primary and the backup.
For external temporal constraint, if a client modifies anobject i, the primary must send an update for the object tothe backup within the next �0i ÿ �i ÿ ` time units; otherwise,the object on the backup may fall out of the consistencywindow. In order to maintain the given bound of the datainconsistency for object i, it is sufficient that the primarysend an update for object i to the backup at least once every�0i ÿ �i ÿ ` time units. Because UDP, the underlying trans-port protocol we use, does not provide reliability ofmessage delivery, we build enough slack such that theprimary can retransmit updates to the backup to compen-sate for potential message loss. For example, we set theperiod for the update task of object i as ��0i ÿ �i ÿ `�=2 in ourexperiments. For interobject temporal constraint, the pri-mary simply schedules the two updates for object i and jwithin �ij time units (see Section 4).
The optimization techniques can be easily embedded inour implementation. If the minimization of temporaldistance is desired, then the algorithm described in thesection concerning temporal distance is used to scheduleupdates from the primary to the backup in which case thefrequency of updates being sent to backup for each object isincreased proportionally until the primary CPU is fullyutilized. If the minimization of primary CPU overhead usedin maintaining the given bound on temporal distance issought, then the algorithm discussed in the sectionconcerning CPU usage is applied. But in either of thesecases, if a client modifies an object i, the primary must sendat least one update for the object to the backup within thenext �0i ÿ �i ÿ ` time units; otherwise, the object on thebackup may fall out of the consistency window. If theprobability of message loss from the primary to the backupand the probability to achieve guarantees of the temporalconsistency in the system are given, then we apply theoptimization technique that deals with message loss.
8 SYSTEM PERFORMANCE
This section summarizes the results of a detailed perfor-mance evaluation of the RTPB replication system intro-duced in this paper. The prototype evaluation considersseveral performance metrics:
. Response time with/without admission control.
. Temporal distance between primary and backup.
. Average duration of backup inconsistency.
. Probability of failover consistency.
. Failure recovery time.
These metrics are influenced by several parametersincluding client write rate, number of objects being accepted,window size (temporal constraint between primary andbackup), communication failure, and optimization. All
542 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 10, NO. 6, JUNE 1999
Fig. 3. System architecture and protocol stack.
graphs in this section illustrate both the external and inter-object temporal consistency. Each interobject temporalconstraint is converted into two external temporal con-straints with the external temporal constraint beingreplaced by the interobject temporal constraint.
8.1 Client Response Time within RTPB
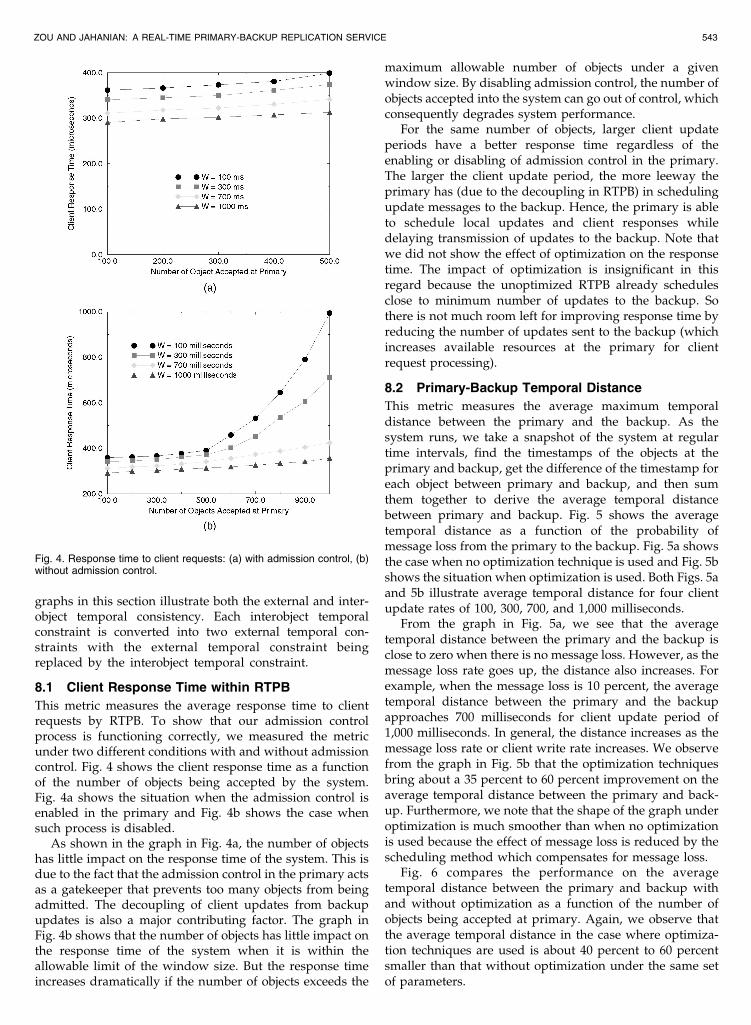
This metric measures the average response time to clientrequests by RTPB. To show that our admission controlprocess is functioning correctly, we measured the metricunder two different conditions with and without admissioncontrol. Fig. 4 shows the client response time as a functionof the number of objects being accepted by the system.Fig. 4a shows the situation when the admission control isenabled in the primary and Fig. 4b shows the case whensuch process is disabled.
As shown in the graph in Fig. 4a, the number of objectshas little impact on the response time of the system. This isdue to the fact that the admission control in the primary actsas a gatekeeper that prevents too many objects from beingadmitted. The decoupling of client updates from backupupdates is also a major contributing factor. The graph inFig. 4b shows that the number of objects has little impact onthe response time of the system when it is within theallowable limit of the window size. But the response timeincreases dramatically if the number of objects exceeds the
maximum allowable number of objects under a givenwindow size. By disabling admission control, the number ofobjects accepted into the system can go out of control, whichconsequently degrades system performance.
For the same number of objects, larger client updateperiods have a better response time regardless of theenabling or disabling of admission control in the primary.The larger the client update period, the more leeway theprimary has (due to the decoupling in RTPB) in schedulingupdate messages to the backup. Hence, the primary is ableto schedule local updates and client responses whiledelaying transmission of updates to the backup. Note thatwe did not show the effect of optimization on the responsetime. The impact of optimization is insignificant in thisregard because the unoptimized RTPB already schedulesclose to minimum number of updates to the backup. Sothere is not much room left for improving response time byreducing the number of updates sent to the backup (whichincreases available resources at the primary for clientrequest processing).
8.2 Primary-Backup Temporal Distance
This metric measures the average maximum temporaldistance between the primary and the backup. As thesystem runs, we take a snapshot of the system at regulartime intervals, find the timestamps of the objects at theprimary and backup, get the difference of the timestamp foreach object between primary and backup, and then sumthem together to derive the average temporal distancebetween primary and backup. Fig. 5 shows the averagetemporal distance as a function of the probability ofmessage loss from the primary to the backup. Fig. 5a showsthe case when no optimization technique is used and Fig. 5bshows the situation when optimization is used. Both Figs. 5aand 5b illustrate average temporal distance for four clientupdate rates of 100, 300, 700, and 1,000 milliseconds.
From the graph in Fig. 5a, we see that the averagetemporal distance between the primary and the backup isclose to zero when there is no message loss. However, as themessage loss rate goes up, the distance also increases. Forexample, when the message loss is 10 percent, the averagetemporal distance between the primary and the backupapproaches 700 milliseconds for client update period of1,000 milliseconds. In general, the distance increases as themessage loss rate or client write rate increases. We observefrom the graph in Fig. 5b that the optimization techniquesbring about a 35 percent to 60 percent improvement on theaverage temporal distance between the primary and back-up. Furthermore, we note that the shape of the graph underoptimization is much smoother than when no optimizationis used because the effect of message loss is reduced by thescheduling method which compensates for message loss.
Fig. 6 compares the performance on the averagetemporal distance between the primary and backup withand without optimization as a function of the number ofobjects being accepted at primary. Again, we observe thatthe average temporal distance in the case where optimiza-tion techniques are used is about 40 percent to 60 percentsmaller than that without optimization under the same setof parameters.
ZOU AND JAHANIAN: A REAL-TIME PRIMARY-BACKUP REPLICATION SERVICE 543
Fig. 4. Response time to client requests: (a) with admission control, (b)without admission control.
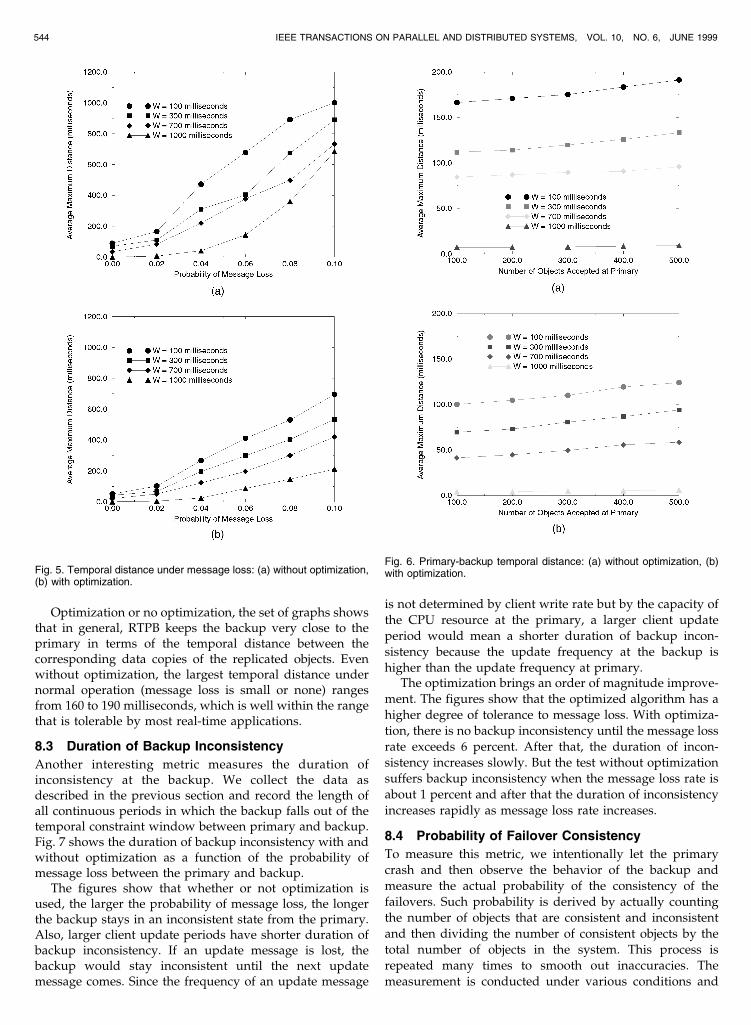
Optimization or no optimization, the set of graphs showsthat in general, RTPB keeps the backup very close to theprimary in terms of the temporal distance between thecorresponding data copies of the replicated objects. Evenwithout optimization, the largest temporal distance undernormal operation (message loss is small or none) rangesfrom 160 to 190 milliseconds, which is well within the rangethat is tolerable by most real-time applications.
8.3 Duration of Backup Inconsistency
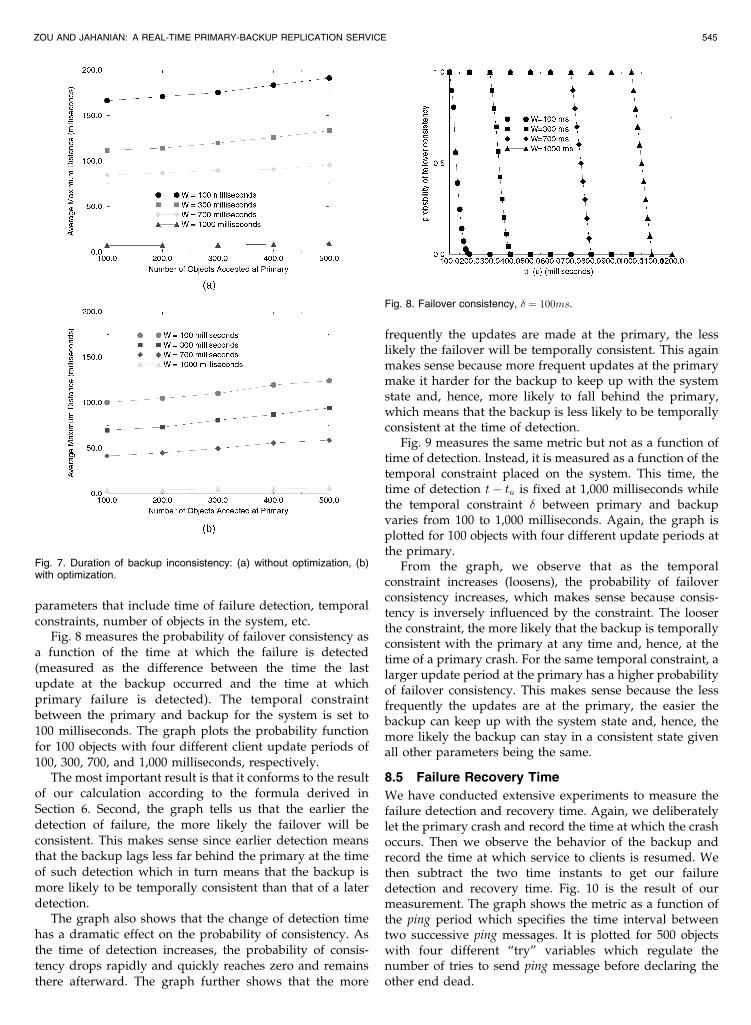
Another interesting metric measures the duration ofinconsistency at the backup. We collect the data asdescribed in the previous section and record the length ofall continuous periods in which the backup falls out of thetemporal constraint window between primary and backup.Fig. 7 shows the duration of backup inconsistency with andwithout optimization as a function of the probability ofmessage loss between the primary and backup.
The figures show that whether or not optimization isused, the larger the probability of message loss, the longerthe backup stays in an inconsistent state from the primary.Also, larger client update periods have shorter duration ofbackup inconsistency. If an update message is lost, thebackup would stay inconsistent until the next updatemessage comes. Since the frequency of an update message
is not determined by client write rate but by the capacity ofthe CPU resource at the primary, a larger client updateperiod would mean a shorter duration of backup incon-sistency because the update frequency at the backup ishigher than the update frequency at primary.
The optimization brings an order of magnitude improve-ment. The figures show that the optimized algorithm has ahigher degree of tolerance to message loss. With optimiza-tion, there is no backup inconsistency until the message lossrate exceeds 6 percent. After that, the duration of incon-sistency increases slowly. But the test without optimizationsuffers backup inconsistency when the message loss rate isabout 1 percent and after that the duration of inconsistency
increases rapidly as message loss rate increases.
8.4 Probability of Failover Consistency
To measure this metric, we intentionally let the primarycrash and then observe the behavior of the backup andmeasure the actual probability of the consistency of thefailovers. Such probability is derived by actually countingthe number of objects that are consistent and inconsistent
and then dividing the number of consistent objects by thetotal number of objects in the system. This process isrepeated many times to smooth out inaccuracies. Themeasurement is conducted under various conditions and
544 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 10, NO. 6, JUNE 1999
Fig. 5. Temporal distance under message loss: (a) without optimization,(b) with optimization.
Fig. 6. Primary-backup temporal distance: (a) without optimization, (b)with optimization.
parameters that include time of failure detection, temporalconstraints, number of objects in the system, etc.
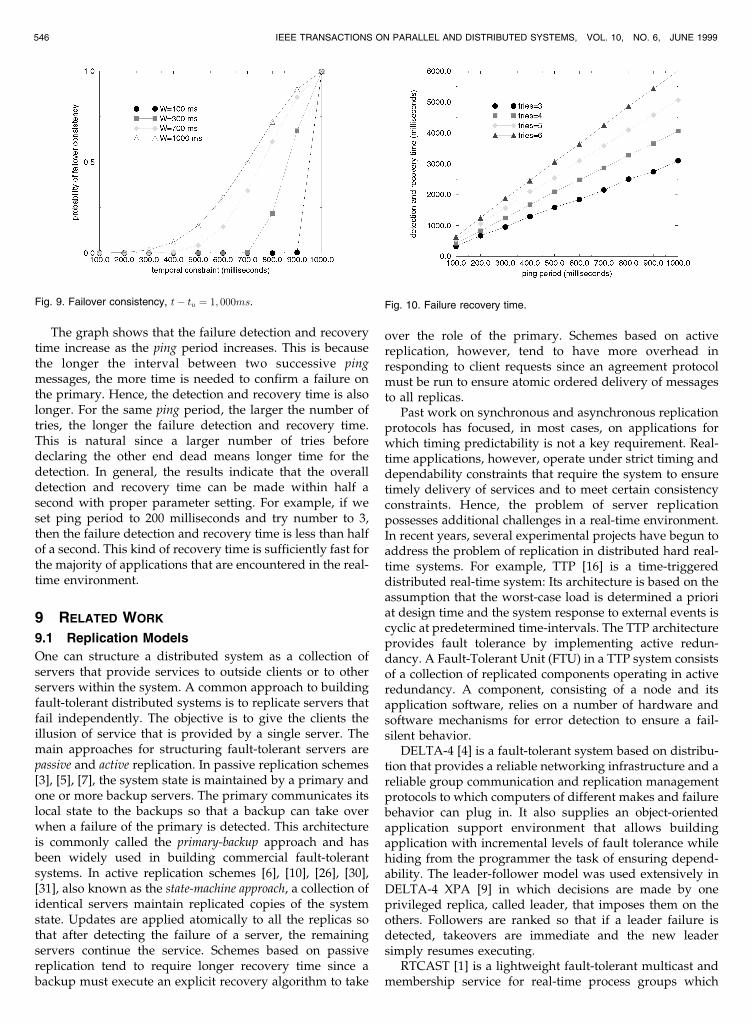
Fig. 8 measures the probability of failover consistency asa function of the time at which the failure is detected(measured as the difference between the time the lastupdate at the backup occurred and the time at whichprimary failure is detected). The temporal constraintbetween the primary and backup for the system is set to100 milliseconds. The graph plots the probability functionfor 100 objects with four different client update periods of100, 300, 700, and 1,000 milliseconds, respectively.
The most important result is that it conforms to the resultof our calculation according to the formula derived inSection 6. Second, the graph tells us that the earlier thedetection of failure, the more likely the failover will beconsistent. This makes sense since earlier detection meansthat the backup lags less far behind the primary at the timeof such detection which in turn means that the backup ismore likely to be temporally consistent than that of a laterdetection.
The graph also shows that the change of detection timehas a dramatic effect on the probability of consistency. Asthe time of detection increases, the probability of consis-tency drops rapidly and quickly reaches zero and remainsthere afterward. The graph further shows that the more
frequently the updates are made at the primary, the lesslikely the failover will be temporally consistent. This againmakes sense because more frequent updates at the primarymake it harder for the backup to keep up with the systemstate and, hence, more likely to fall behind the primary,which means that the backup is less likely to be temporallyconsistent at the time of detection.
Fig. 9 measures the same metric but not as a function oftime of detection. Instead, it is measured as a function of thetemporal constraint placed on the system. This time, thetime of detection tÿ tu is fixed at 1,000 milliseconds whilethe temporal constraint � between primary and backupvaries from 100 to 1,000 milliseconds. Again, the graph isplotted for 100 objects with four different update periods atthe primary.
From the graph, we observe that as the temporalconstraint increases (loosens), the probability of failoverconsistency increases, which makes sense because consis-tency is inversely influenced by the constraint. The looserthe constraint, the more likely that the backup is temporallyconsistent with the primary at any time and, hence, at thetime of a primary crash. For the same temporal constraint, alarger update period at the primary has a higher probabilityof failover consistency. This makes sense because the lessfrequently the updates are at the primary, the easier thebackup can keep up with the system state and, hence, themore likely the backup can stay in a consistent state givenall other parameters being the same.
8.5 Failure Recovery Time
We have conducted extensive experiments to measure thefailure detection and recovery time. Again, we deliberatelylet the primary crash and record the time at which the crashoccurs. Then we observe the behavior of the backup andrecord the time at which service to clients is resumed. Wethen subtract the two time instants to get our failuredetection and recovery time. Fig. 10 is the result of ourmeasurement. The graph shows the metric as a function ofthe ping period which specifies the time interval betweentwo successive ping messages. It is plotted for 500 objectswith four different ªtryº variables which regulate thenumber of tries to send ping message before declaring theother end dead.
ZOU AND JAHANIAN: A REAL-TIME PRIMARY-BACKUP REPLICATION SERVICE 545
Fig. 7. Duration of backup inconsistency: (a) without optimization, (b)with optimization.
Fig. 8. Failover consistency, � � 100ms.
The graph shows that the failure detection and recoverytime increase as the ping period increases. This is becausethe longer the interval between two successive pingmessages, the more time is needed to confirm a failure onthe primary. Hence, the detection and recovery time is alsolonger. For the same ping period, the larger the number oftries, the longer the failure detection and recovery time.This is natural since a larger number of tries beforedeclaring the other end dead means longer time for thedetection. In general, the results indicate that the overalldetection and recovery time can be made within half asecond with proper parameter setting. For example, if weset ping period to 200 milliseconds and try number to 3,then the failure detection and recovery time is less than halfof a second. This kind of recovery time is sufficiently fast forthe majority of applications that are encountered in the real-time environment.
9 RELATED WORK
9.1 Replication Models
One can structure a distributed system as a collection ofservers that provide services to outside clients or to otherservers within the system. A common approach to buildingfault-tolerant distributed systems is to replicate servers thatfail independently. The objective is to give the clients theillusion of service that is provided by a single server. Themain approaches for structuring fault-tolerant servers arepassive and active replication. In passive replication schemes[3], [5], [7], the system state is maintained by a primary andone or more backup servers. The primary communicates itslocal state to the backups so that a backup can take overwhen a failure of the primary is detected. This architectureis commonly called the primary-backup approach and hasbeen widely used in building commercial fault-tolerantsystems. In active replication schemes [6], [10], [26], [30],[31], also known as the state-machine approach, a collection ofidentical servers maintain replicated copies of the systemstate. Updates are applied atomically to all the replicas sothat after detecting the failure of a server, the remainingservers continue the service. Schemes based on passivereplication tend to require longer recovery time since abackup must execute an explicit recovery algorithm to take
over the role of the primary. Schemes based on activereplication, however, tend to have more overhead inresponding to client requests since an agreement protocolmust be run to ensure atomic ordered delivery of messagesto all replicas.
Past work on synchronous and asynchronous replicationprotocols has focused, in most cases, on applications forwhich timing predictability is not a key requirement. Real-time applications, however, operate under strict timing anddependability constraints that require the system to ensuretimely delivery of services and to meet certain consistencyconstraints. Hence, the problem of server replicationpossesses additional challenges in a real-time environment.In recent years, several experimental projects have begun toaddress the problem of replication in distributed hard real-time systems. For example, TTP [16] is a time-triggereddistributed real-time system: Its architecture is based on theassumption that the worst-case load is determined a prioriat design time and the system response to external events iscyclic at predetermined time-intervals. The TTP architectureprovides fault tolerance by implementing active redun-dancy. A Fault-Tolerant Unit (FTU) in a TTP system consistsof a collection of replicated components operating in activeredundancy. A component, consisting of a node and itsapplication software, relies on a number of hardware andsoftware mechanisms for error detection to ensure a fail-silent behavior.
DELTA-4 [4] is a fault-tolerant system based on distribu-tion that provides a reliable networking infrastructure and areliable group communication and replication managementprotocols to which computers of different makes and failurebehavior can plug in. It also supplies an object-orientedapplication support environment that allows buildingapplication with incremental levels of fault tolerance whilehiding from the programmer the task of ensuring depend-ability. The leader-follower model was used extensively inDELTA-4 XPA [9] in which decisions are made by oneprivileged replica, called leader, that imposes them on theothers. Followers are ranked so that if a leader failure isdetected, takeovers are immediate and the new leadersimply resumes executing.
RTCAST [1] is a lightweight fault-tolerant multicast andmembership service for real-time process groups which
546 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 10, NO. 6, JUNE 1999
Fig. 9. Failover consistency, tÿ tu � 1; 000ms. Fig. 10. Failure recovery time.

exchange periodic and aperiodic messages. The servicesupports bounded-time message transport, atomicity, andorder for multicasts within a group of communicatingprocesses in the presence of processor crashes and commu-nication failures. It guarantees agreement on membershipamong the communicating processors and ensures thatmembership changes resulting from processor joins ordepartures are atomic and ordered with respect to multicastmessages. Both TTP and RTCAST are based on activereplication, whereas RTPB is a passive scheme. A compar-ison between RTCAST and RTPB on identical platformsshows that RTPB provides better response time whileRTCAST is faster in failover time. This is because RTPBdecouples the updates at the primary from that at thebackup, which speeds up the update process at the primary,while RTCAST is an active scheme which consequently hasa shorter recovery time. However, Koptez's TTP imple-mentation performs significantly better than RTPB andother active replication implementations including Totemand RTCAST, to a large extent because of the hardwaresupport available in TTP.
Gagliardi et al. [12] present a publisher/subscribermodel for distributed real-time systems. It provides asimple user interface for publishing messages on a logicalªchannelº and for subscribing to selected channels asneeded by each application. In the absence of faults, eachmessage sent by a publisher on a channel should bereceived by all subscribers. The abstraction hides a portable,analyzable, scalable, and efficient mechanism for groupcommunication. It does not, however, attempt to guaranteeatomicity and order in the presence of failures, which maycompromise consistency.
9.2 Consistency Semantics
The approach proposed in this paper bounds the overheadby relaxing the requirements on the consistency of thereplicated data. For a large class of real-time applications,the system can recover from a server failure even thoughthe servers may not have maintained identical copies of thereplicated state. This facilitates alternative approaches thattrade atomic or causal consistency amongst the replicas forless expensive replication protocols. Enforcing a weakercorrectness criterion has been studied extensively fordifferent purposes and application domains. In particular,a number of researchers have observed that serializability istoo strict as a correctness criterion for real-time databases.Relaxed correctness criteria facilitate higher concurrency bypermitting a limited amount of inconsistency in how atransaction views the database state [11], [15], [18], [19], [20],[21], [22], [28], [29], [34].
For example, a recent work [19] proposed a class of real-time data access protocols called SSP (Similarity StackProtocol) applicable to distributed real-time systems. Thecorrectness of the SSP protocol is justified by the concept ofsimilarity, which allows different but sufficiently timely datato be used in a computation without adversely affecting theoutcome. Data items that are similar would produce thesame result if used as input. SSP schedules are deadlock-free, subject to limited blocking, and do not use locks.Furthermore, a schedulability bound can be given for theSSP scheduler. Simulation results show that SSP is
especially useful for scheduling real-time data access onmultiprocessor systems. Song and Liu [32] defined tempor-al consistency in database transaction by the differencebetween a data item's age and its dispersion and experi-mented the effect of pessimistic and optimistic concurrencycontrol has on such temporal consistency.
Similarly, the notion of imprecise computation [24]explores weaker application semantics and guaranteestimely completion of tasks by relaxing the accuracyrequirements of the computation. This is particularly usefulin applications that use discrete samples of continuous timevariables since these values can be approximated whenthere is not sufficient time to compute an exact value. Weakconsistency can also improve performance in non-real-timeapplications. For instance, the quasi-copy model permitssome inconsistency between the central data and its cachedcopies at remote sites [2]. This gives the scheduler moreflexibility in propagating updates to the cached copies. Inthe same spirit, the RTPB replication service allowscomputation that may otherwise be disallowed by existingactive or passive protocols that support atomic updates to acollection of replicas.
10 CONCLUDING REMARKS
This paper presented a real-time primary-backup replica-tion scheme to support fault-tolerant data access in a real-time environment. The paper defines external and interobjecttemporal consistency and builds a computation model thatensures such consistencies for replicated data determinis-tically where the underlying communication mechanismprovides deterministic message delivery semantics, andprobabilistically where no such support is available. It alsopresents an optimization of the system and an analysis ofthe failover process. The evaluation of a prototypeimplementation of the proposed scheme shows that theRTPB model performs significantly better than the tradi-tional passive scheme while ensuring temporal consistencyof replicated data objects and meeting the timing require-ment of the target applications.
Avenues for future study include: extension of externaland interobject temporal consistency to active replication,probabilistic real-time active replication, and dynamichybrid active-passive replication.
ACKNOWLEDGMENTS
We wish to thank the ARMADA team members for theirhelpful comments and insights. We also thank the anon-ymous referees of IEEE Transactions on Parallel and DistributedSystems for their feedback and constructive criticism. Thework reported in this paper was supported in part by theAdvanced Research Projects Agency, monitored by the U.S.Air Force Rome Laboratory under Grant F30602-95-1-0044.This paper is an extended and combined version of the earlierwork reported in [36] and [35].
REFERENCES
[1] T. Abdelzaher, A. Shaikh, S. Johnson, F. Jahanian, and K.G. Shin,ªRtcast: Lightweight Multicast for Real-Time Process Groups,ºIEEE Real-Time Technology and Applications Symp., 1996.
ZOU AND JAHANIAN: A REAL-TIME PRIMARY-BACKUP REPLICATION SERVICE 547

[2] R. Alonso, D. Barbara, and H. Garcia-Molina, ªData CachingIssues in an Information Retrieval Sysmem,º ACM Trans. DatabaseSystems, vol. 15, no. 3, pp. 359-384, Sept. 1990.
[3] P. Alsberg and J. Day, ªA Principle for Resilient Sharing ofDistributed Resources,º Proc. IEEE Int'l Conf. Software Eng., 1976.
[4] P.A. Barrett, A.M. Hilborne, P. Verissimo, L. Rodrigues, D.T.Seaton, and N.A. Spears, ªThe Delta-4 Extra PerformanceArchitecture (xpa),º Digest of Papers 20th Int'l Symp. Fault-TolerantComputing, pp. 481-488, 1990.
[5] J.F. Bartlett, ªTandem: A Non-Stop Kernel,º ACM OperatingSystem Review, vol. 15, 1991.
[6] K.P. Birman, ªThe Process Group Approach to Reliable Distrib-uted Computing,º Comm. ACM, vol. 39, no. 12, pp. 37-53, Dec.1993.
[7] N. Budhiraja and K. Marzullo, ªTradeoffs in ImplementingPrimary-Backup Protocols,º Proc. IEEE Symp. Parallel and Dis-tributed Processing, pp. 280-288, Oct. 1995.
[8] A. Burns and A. Wellings, ªResponse Time Analysis,º Real-TimeSystems and Programming Languages, second ed., chapter 13,pp. 407-411. Addison-Wesley, 1997.
[9] M. Chereque, D. Powell, P. Reynier, J.-L. Richier, and J. Voiron,ªActive Replication in Delta-4,º Digest of Papers 22nd Int'l Symp.Fault-Tolerant Computing, 1992.
[10] F. Cristian, B. Dancy, and J. Dehn, ªFault-Tolerance in theAdvanced Automation System,º Proc. Int'l Symp. Fault-TolerantComputing, pp. 160-170, June 1990.
[11] S.B. Davidson and A. Watters, ªPartial Computation in Real-TimeDatabase Systems,º Proc. Workshop Real-Time Operating Systemsand Software, pp. 117-121, May 1998.
[12] M. Gagliardi, R. Rajkumar, and L. Sha, ªDesigning for Evolva-bility: Building Blocks for Evolvable Real-Time Systems,º Proc.Real-Time Technology and Applications Symp., June 1996.
[13] C.-C. Han and K.-J. Lin, ªScheduling Distance-Constrained Real-Time Tasks,º Proc. Real-Time Systems Symp., Dec. 1992.
[14] N.C. Hutchinson and L.L. Peterson, ªThe x-Kernel: An Architec-ture for Implementing Network Protocols,º IEEE Trans. SoftwareEng., vol. 17, no. 1, pp. 64-76, Jan. 1991.
[15] B. Kao and H. Garcia-Molina, ªAn Overview of Real-TimeDatabase Systems,º Advances in Real-Time Systems, S.H. Son, ed.,pp. 463-486. Prentice Hall, 1995.
[16] H. Kopetz and G. Grunsteidl, ªTTP-A Protocol for Fault-TolerantReal-Time Systems,º Computer, vol. 27, no. 1, pp. 14-23, Jan. 1994.
[17] H. Kopetz and P. Verissimo, ªReal-Time and DependabilityConcepts,º Distributed Systems, S. Mullender, ed., second ed.,chapter 16, pp. 411-446. Addison-Wesley, 1993.
[18] H.F. Korth, N. Soparkar, and A. Silberschatz, ªTriggered Real-Time Databases with Consistency Constraints,º Proc. Int'l Conf.Very Large Data Bases, Aug. 1990.
[19] T.-W. Kuo and A.K. Mok, ªSSP: A Semantics-Based Protocol forReal-Time Data Access,º Proc. 14th IEEE Real-Time Systems Symp.,Dec. 1993.
[20] T.-W. Kuo and A.K. Mok, ªReal-Time DatabaseÐSimilarity,Semantics, and Resource Scheduling,º ACM SIGMOD Record,Mar. 1997.
[21] K.-J. Lin, ªConsistency Issues in Real-Time Database Systems,ºProc. 22nd Hawaiin Int'l Conf. System Sciences, pp. 654-661, Jan.1989.
[22] K.-J. Lin and F. Jahanian, ªIssues and Application,º Real-TimeDatabase Systems, S. Son, ed. Kluwer Academic, 1997.
[23] C.L. Liu and J.W. Layland, ªScheduling Algorithms for Multi-programming in a Hard Real-Time Environment,º J. ACM, vol. 20,no. 1, pp. 46-61, Jan. 1973.
[24] J.W.S. Liu, W.-K. Shih, and K.-J. Lin, ªImprecise Computation,ºProc. IEEE, vol. 82, pp. 83-94, Jan. 1994.
[25] A. Mehra, J. Rexford, and F. Jahanian, ªDesign and Evaluation of aWindow-Consistent Replication Service,º IEEE Trans. Computers,vol. 46, no. 9, pp. 986-996, Sept. 1997.
[26] L.E. Moser, P.M. Melliar-Smith, D.A. Agarwal, R.K. Budhia, andC.A. Lingley-Papadopoulos, ªTotem: A Fault-Tolerant MulticastGroup Communication System,º Comm. ACM, vol. 39, no. 4,pp. 54-63, Apr. 1996.
[27] S.W. O'Malley and L.L. Peterson, ªA Dynamic Network Archi-tecture,º ACM Trans. Computer Systems, vol. 10, no. 2, pp. 110-143,May 1992.
[28] C. Pu and A. Leff, ªReplica Control in Distributed Systems: AnAsynchronous Approach,º Proc. ACM SIGMOD, pp. 377-386, May1991.
[29] B. Purimetla, R.M. Sivasankaran, K. Ramamritham, and J.A.Stankovic, ªReal-Time Databases: Issues and Applications,ºAdvances in Real-Time Systems, S.H. Son, ed., first ed., chapter 20.Prentice Hall, 1995.
[30] R.V. Renesse, K.P. Birman, and S. Maffeis, ªHorus: A FlexibleGroup Communication System,º Comm. ACM, vol. 39, no. 4,pp. 76-83, Apr. 1996.
[31] F.B. Schneider, ªImplementing Fault-Tolerant Services Using theState-Machine Approach: a Tutorial,º ACM Trans. ComputingSurveys, vol. 22, no. 4, pp. 299-319, Dec. 1990.
[32] X. Song and J.W.S. Liu, ªMaintaining Temporal Consistency:Pessimistic vs. Optimistic Concurrency Control,º IEEE Trans.Knowledge and Data Eng., pp. 786-796, Oct. 1992
[33] K. Tindell, A. Burns, and A.J. Wellings, ªAn Extendible Approachfor Analysing Fixed Priority Hard Real-Time Tasks,º The Real-Time Systems J., vol. 6, no. 2, pp. 133-151, 1994.
[34] M. Xiong, R. Sivasankaran, J. Stankovic, K. Ramamritham, and D.Towsley, ªScheduling Transaction with Temporal Constraints:Exploiting Data Semantics,º Proc. IEEE Real-Time Systems Symp.,Dec. 1996.
[35] H. Zou and F. Jahanian, ªOptimization of a Real-Time Primary-Backup Replication Service,º Proc. IEEE Symp. Reliable DistributedSystems, pp. 177-185, Oct. 1998.
[36] H. Zou and F. Jahanian, ªReal-Time Primary-Backup Replicationswith Temporal Consistency Guarantees,º Proc. IEEE ICDCS,pp. 48-56, May 1998.
Hengming Zou received his BSCS from Huaz-hong University of Science and Technology,Wuhan, China, in 1985, and the MSCS from theInstitute of Computing Technology, ChineseAcademy of Sciences, Beijing, China, in 1988.He is currently a PhD candidate in computerscience and engineering at the University ofMichigan at Ann Arbor, where he works as aresearch assistant in the Real-Time ComputingLaboratory. Prior to joining the University of
Michigan in 1996, he worked at Huazhong University of Science andTechnology, IBM, NDC/CIS Technologies, and Lucent Technologies.His research interests include fault-tolerant distributed systems, real-time computing, algorithms, and networking. He is a student member ofthe IEEE.
Farnam Jahanian received the MS and PhDdegrees in computer science from the Universityof Texas at Austin in 1987 and 1989, respec-tively. He is currently an associate professor ofelectrical engineering and computer science atthe University of Michigan. Prior to joining thefaculty at the University of Michigan in 1993, hewas a research staff member at the IBM T.J.Watson Research Center, where he led severalexperimental projects in distributed and fault-
tolerant systems. His current research interests include real-time andfault-tolerant computing, and network protocols and architectures.
548 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 10, NO. 6, JUNE 1999