強化学習勉強会・論文紹介(第30回)ensemble contextual bandits for personalized...
TRANSCRIPT

Ensemble Contextual Bandits for Personalized Recommendation
Tang, L., Jiang, Y., Li, L., & Li, T In Proceedings of the 8th ACM Conference on Recommender Systems (pp. 73-80). ACM.
強化学習勉強会 第 30 回
2016/08/10 西村 直樹

本論文を選んだ動機
• ウェブサービス事業ではユーザごとのコンテンツの出し分け、
ユーザごとの商品レコメンドなどが施策として多く行われている
• 新コンテンツ、新商品の配信・レコメンドを行う状況では一般に
コールドスタート問題と呼ばれる問題が生じる
• コールドスタート問題に対するアプローチとしてバンディット
アルゴリズムが近年注目されているが身の回りでうまく適用し
成果を上げている施策事例は多くない
• 本論文では複数のバンディットアルゴリズムの方策を統合すること
でロバストな性能を達成する方法を提案しており、様々な施策での
適用可能性が高いと感じたため紹介する
2

本論文の貢献
本論文の貢献として以下の 3 つことが挙げられている
1. 異なるバンディット方策の利点を統合することでウェブにおける
CTR推定安定化の可能性を示した
2. パーソナライズレコメンデーションにおけるコールドスタート
問題に対処する 2 つのアンサンブル戦略を提案した
3. 提案手法について実データを用いてロバストさの評価を行った
3

目次
• 背景
• 提案手法
• 基本となるバンディットアルゴリズム
• 数値実験
• まとめ
4

コールドスタート問題
• パーソナライズレコメンドシステムはユーザの嗜好に応じて商品など
を出し分けすることを目的としている
• しかし実践的には多くの商品やユーザはシステムにとって全く新しく
正しく対処できないコールドスタートと呼ばれる問題が生じる
• コールドスタート問題には高い報酬が得られる可能性を模索する
「探索」と既知の情報を利用する「活用」を組合せることで一般に
対処される
• 不明瞭なユーザの関心において、長期的な観点でユーザの満足度を
最大化するため、「探索」と「活用」のトレードオフを見つけること
が重要である
5

Contextual Bandit Problem
コールドスタート問題への対処は Contextual Bandit Problem
としてモデル化されることがある
• Contextual Bandit Problem
- 目的:累積報酬の最大化
- 変数:コンテクストによって決定される未知の分布のもとで
どの腕を引くか
• パーソナライズレコメンドの状況
- 腕を引く → 商品を推薦する
- コンテクスト → 訪れるユーザ
- 報酬 → ユーザの反応(クリックするか否かなど) 6

どのアルゴリズムを使うべきか?
• それぞれの Contextual Bandit アルゴリズムの性能は適用する
状況において性能が大きく異なる
• 適切な方策を選択する実践的な方法は、まず各方策を評価した後、
よいものをシステムに適用する、というものである
• しかしコールドスタートの状況下では過去データからバイアスの
かからないオフライン評価の方法を設計するのは難しい
7

A/B テストではだめか?
• オンラインで評価する方法としては A/B テストがある
• しかし多くの方策を並行にテストしてしまうと、その数だけ
対象も各方策に分割されてしまう
→ 分割し過ぎると最適な方策をとった場合の報酬から離れてしまう
8

問題の定式化:記号の定義
• :商品(バンディットの腕)の集合
• :バンディットの方策の集合
• :方策 がコンテクスト特徴ベクトル において
を引く
• :コンテクスト特徴ベクトルの空間
• :コンテクスト の確率密度
• :コンテクスト 商品 のとき報酬 となる確率分布
• :報酬(クリックするか否かの{0,1})
9

問題の定式化:評価指標
• 方策の評価指標:
10
• 本論文での目標:
になるべく近い方策を得ること
ユーザ に方策 が商品
を推薦し報酬 が得られる確率
→ は方策 の CTR を表す

目次
• 背景
• 提案手法
• 基本となるバンディットアルゴリズム
• 数値実験
• まとめ
11

バンディットアルゴリズムをアンサンブルする
• 提案手法では方策 とコンテクスト が
与えられたとき腕を選択する上で 2 つのことを決定する
1. から方策 を選択する
2. 引く腕 を選択する
• 本論文では 1. の方策を選択する部分に焦点を当てている
• 方策の選択にはnon-contextualなThompson Samplingを用いる
• は直接計算出来ないので各試行毎に の分布から
を確率的に選択し最大の方策を選ぶ
• を推定する 2 つの方法について提案する
12

提案手法 1:HyperTS Algorithm
• 各方策 についてモンテカルロ法を用いて を推定
• ある方策 において 、 、 が確率的に得られる
とするとモンテカルロ法による推定値は
• 報酬 が Bernoulli 分布 から得られる
と仮定すると はベータ分布に従い、以下のようになる
• 、 であり、初期状態では
とする
13

HyperTS のアルゴリズム
• 各試行において方策が 選ばれるたびに 、 を更新
• 1 回の試行ではひとつの方策の α、β しか更新されない14

提案手法 2:HyperTSFB Algorithm
• HyperTSのアルゴリズムでは各方策はその方策が選択されたとき
のみしか期待報酬の分布が更新されない
→ 方策集合の要素数が多い場合、多くの探索が必要となってしまい
累積報酬は下がってしまう
• HyperTSFBは各試行のフィードバックを全ての方策に対して反映さ
せることができる
→ ある腕 を引いた時に Importance Weight と呼ばれる指標に
基づき全ての方策について期待値を更新
15

Importance Weight:
• コンテクスト が与えられたとき腕 を引くというのが
方策 においてどの程度起こり得たかを表す指標
• コンテクスト が与えられた時に方策 が腕 を引く確率
を算出
• ランダム方策の場合は という
ように計算できるが、TSなどの場合は計算出来ないので何度か
の試行の平均値をとる16
=
が選択される確率

HyperTSFB による方策の期待報酬
17
Importance weight
• : を引く確率
• : を引いた時の の期待報酬
→ 方策の期待報酬は、各腕の期待報酬に分割することができる

• : のときの の期待値( のCTR)
→ に従うと仮定
• :もし の報酬が 1 のとき がその腕を引く程度
→ に従うと仮定
の分解
18
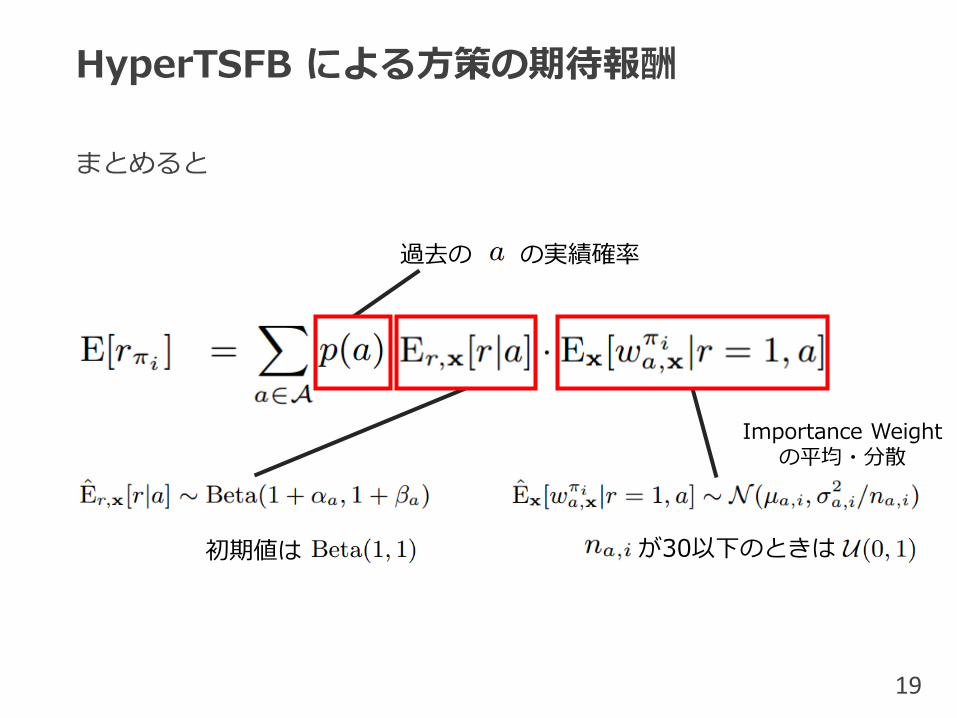
HyperTSFB による方策の期待報酬
まとめると
19
過去の の実績確率
初期値は が30以下のときは
Importance Weight の平均・分散

HyperTSFB のアルゴリズム
各方策の期待報酬に基づき、ある
試行で利用する方策、腕を決定
20
報酬に基づきImportance Weight
と各統計量を更新

目次
• 背景
• 提案手法
• 基本となるバンディットアルゴリズム
• 数値実験
• まとめ
21

基本となるバンディットアルゴリズム
本論文では以下の 7 つを基本のバンディットアルゴリズムとして用いる
1. Random
2. ε-greedy (ε)
3. LinUCB (α)
4. Softmax (τ)
5. Epoch-greedy(L)
6. TS (q0)
7. TSNR (q0)
22

基本となるバンディットアルゴリズム
1. Random
- ランダムに腕を引く
2. ε-greedy (ε)
- ε の確率でランダムに腕を引き、1-ε の確率で報酬の予測値が
最大の腕をひく
23

基本となるバンディットアルゴリズム
3. LinUCB (α)
- それぞれの試行で、予測報酬の平均と標準偏差の線形和で
表されるスコアが最大の腕を引く
- コンテクストを 、 と をそれぞれ事前分布の推定
平均、共分散とするとスコアは と
表される
- α は探索と活用のバランスを制御するパラメータである
24

基本となるバンディットアルゴリズム
4. Softmax (τ)
- 腕 を確率 で引く
- は腕 の予測報酬である
- τ は探索と活用のバランスを制御するパラメータである
5. Epoch-greedy (L)
- 長さ L の期間において、最初に 1 回探索を行い、残りの試行
では活用を行う
25

基本となるバンディットアルゴリズム
6. TS (q0)
- 事後分布からランダムに引いた係数を用いたロジスティック回帰に
よりThompon Samplingを行い、最大の予測報酬の腕を選択する
- 事前分布は とする
7. TSNR(q0)
- TS (q0) と似ているが確率的勾配上昇法において事前に正規化を
行わない
- 事前分布 はパラメータサンプリングのために事後分
布の計算において 1 回だけ用いてその後は利用しない
26

目次
• 背景
• 提案手法
• 基本となるバンディットアルゴリズム
• 数値実験
• まとめ
27

数値実験の設定
• データ
- Yahoo! Today News のアクセスログ
- KDD Cup 2012 Online Advertise での提供データ
• 評価方法
- Yahoo! Today News:Replayer Methodという指標
→ 過去にユーザ訪問ログを利用して評価(次ページ)
- KDD Cup 2012:訪問ログから各コンテクストに各腕を引いた
ときの確率をロジスティック回帰によりを学習し、
予測したCTRを用いてシミュレーション
→ 一様乱数なレコメンドでないためReplayer Methodが使えない28
O. Chapelle and L. Li. An empirical evaluation of thompson sampling. In NIPS, 2011.

Replayer Method
29
L. Li, W. Chu, J. Langford, and X. Wang. Unbiased offline evaluation of
contextual-bandit-based news article recommendation algorithms. In WSDM, 2011.
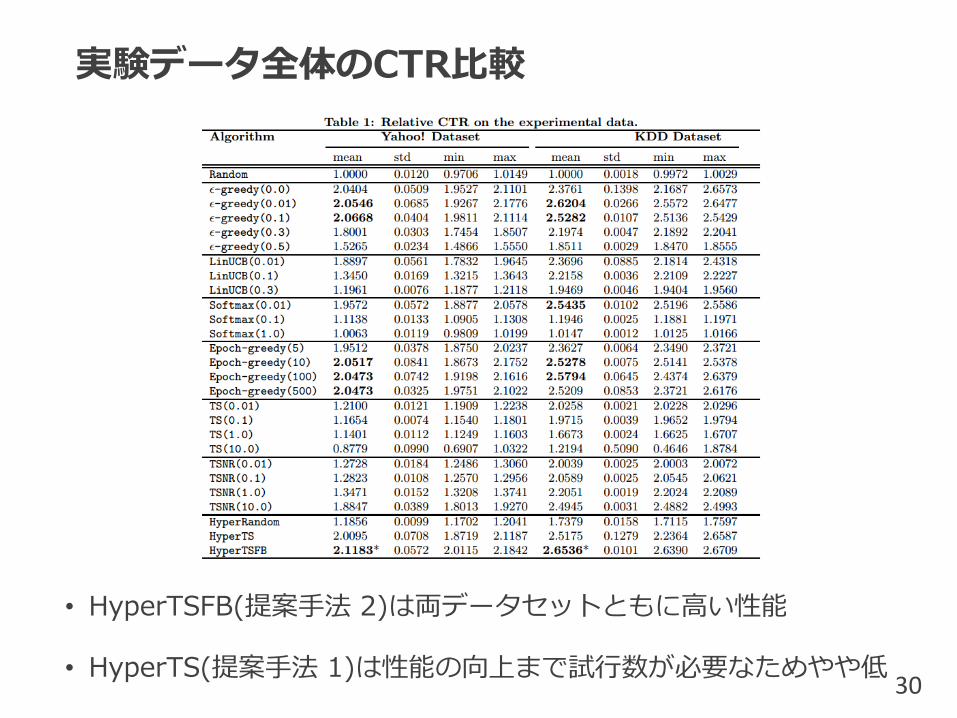
実験データ全体のCTR比較
• HyperTSFB(提案手法 2)は両データセットともに高い性能
• HyperTS(提案手法 1)は性能の向上まで試行数が必要なためやや低30
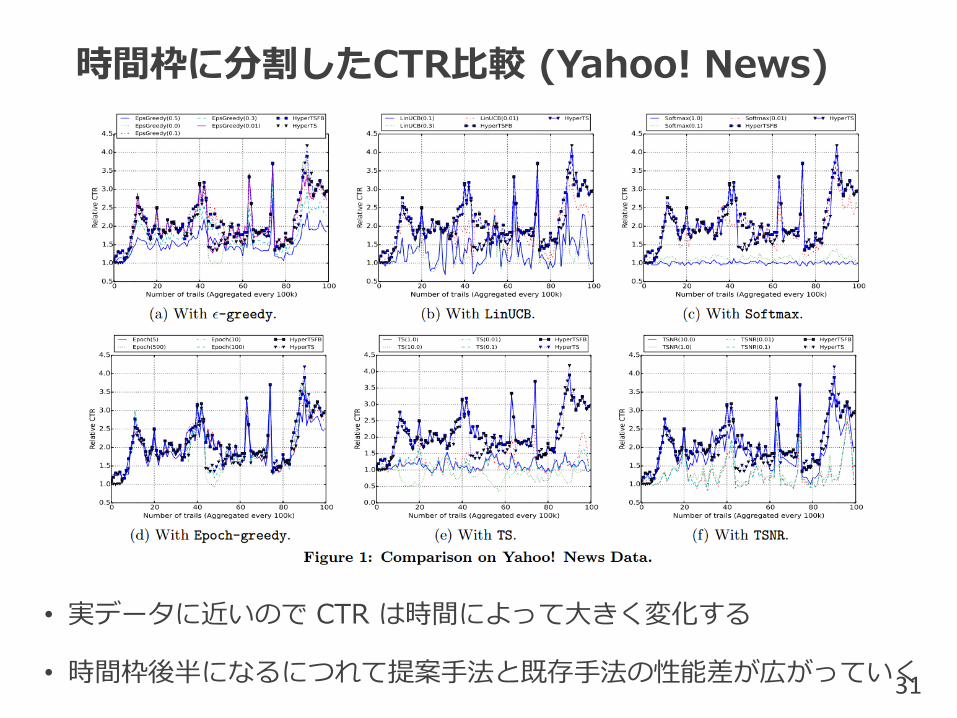
時間枠に分割したCTR比較 (Yahoo! News)
• 実データに近いので CTR は時間によって大きく変化する
• 時間枠後半になるにつれて提案手法と既存手法の性能差が広がっていく31
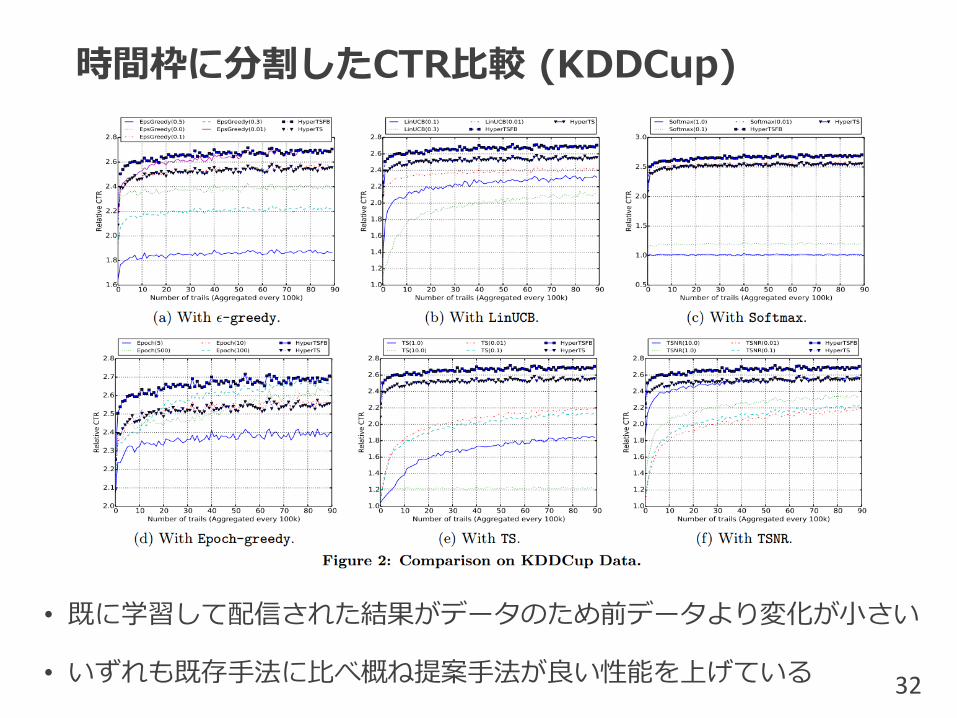
時間枠に分割したCTR比較 (KDDCup)
• 既に学習して配信された結果がデータのため前データより変化が小さい
• いずれも既存手法に比べ概ね提案手法が良い性能を上げている 32
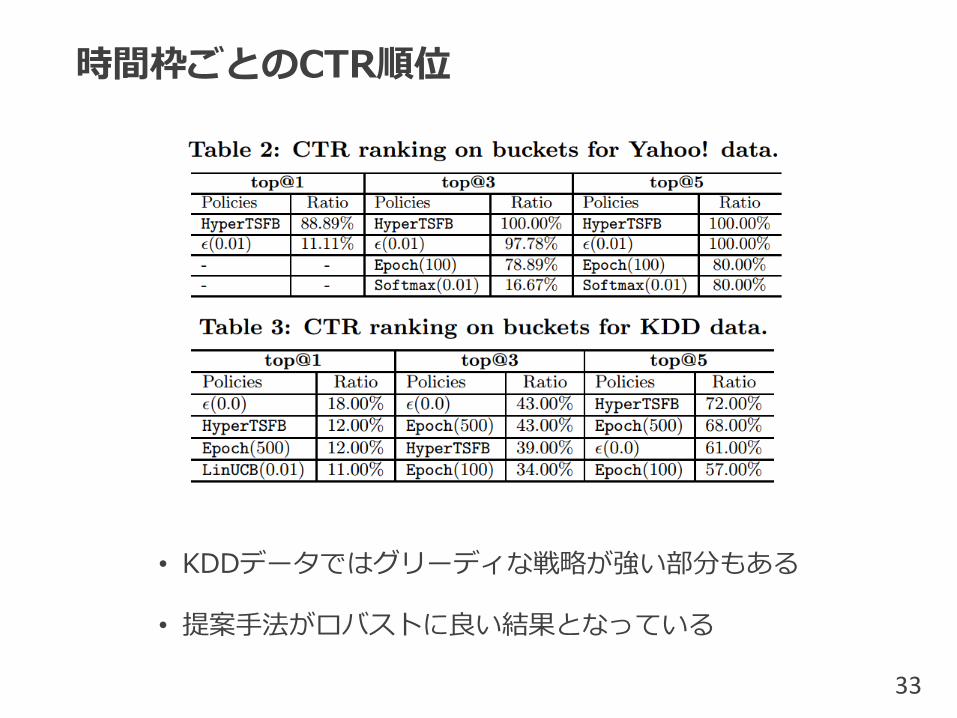
時間枠ごとのCTR順位
• KDDデータではグリーディな戦略が強い部分もある
• 提案手法がロバストに良い結果となっている
33

目次
• 背景
• 提案手法
• 基本となるバンディットアルゴリズム
• 数値実験
• まとめ
34

まとめ
• コールドスタートの状況において Contextual Bandit のどの方策を
用いるか、どのようにパラメータを設定するかを事前に決定するこ
とは難しい
• 提案手法は複数の Contextual Bandit の方策を探索、活用する
ことでロバストな予測性能を達成することを目指している
• 数値実験により、提案手法は既存の Contextual Bandit
アルゴリズムを単純に用いた場合と比較しロバストな予測性能を
達成できることが確認された
35