27. may 20141 topic models nam khanh tran ([email protected]) l3s research center
TRANSCRIPT


Nam Khanh Tran 2
Acknowledgements
The slides are in part based on the following slides “Probabilistic Topic Models”, David M. Blei 2012 “Topic Models”, Claudia Wagner, 2010
.....and the papers David M. Blei, Andrew Y. Ng, Michael I. Jordan: Latent Dirichlet Allocation.
Journal of Machine Learning Research 2003 Steyvers and Griffiths, Probabilistic Topic Models, (2006). David M. Blei, John D. Lafferty, Dynamic Topic Models. Proceedings of the
23rd international conference on Machine learning

Nam Khanh Tran 3
Outline
Introduction
Latent Dirichlet Allocation
Overview
The posterior distribution for LDA
Gibbs sampling
Beyond latent Dirichlet Allocation
Demo

Nam Khanh Tran 4
The problem with information
As more information becomes available, it becomes more difficult to find and discover what we need
We need new tools to help us organize, search, and understand these vast amounts of information

Nam Khanh Tran 5
Topic modeling
Topic modeling provides methods for automatically organizing, understanding, searching, and summarizing large electronic archives
1) Discover the hidden themes that pervade the collection
2) Annotate the documents according to those themes
3) Use annotations to organize, summarize, search, form predictions

Nam Khanh Tran 6
Discover topics from a corpus
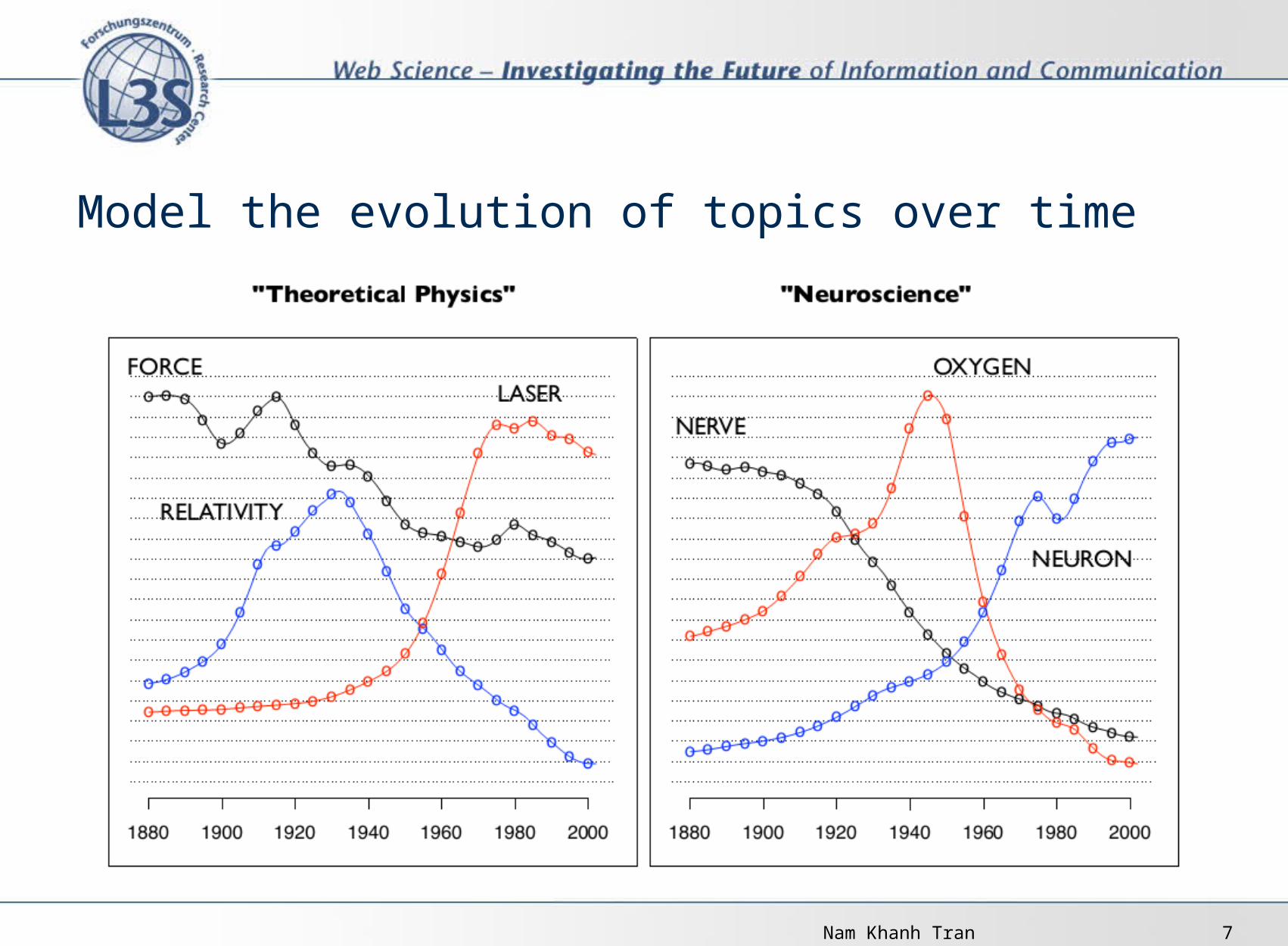
Nam Khanh Tran 7
Model the evolution of topics over time
Nam Khanh Tran 8
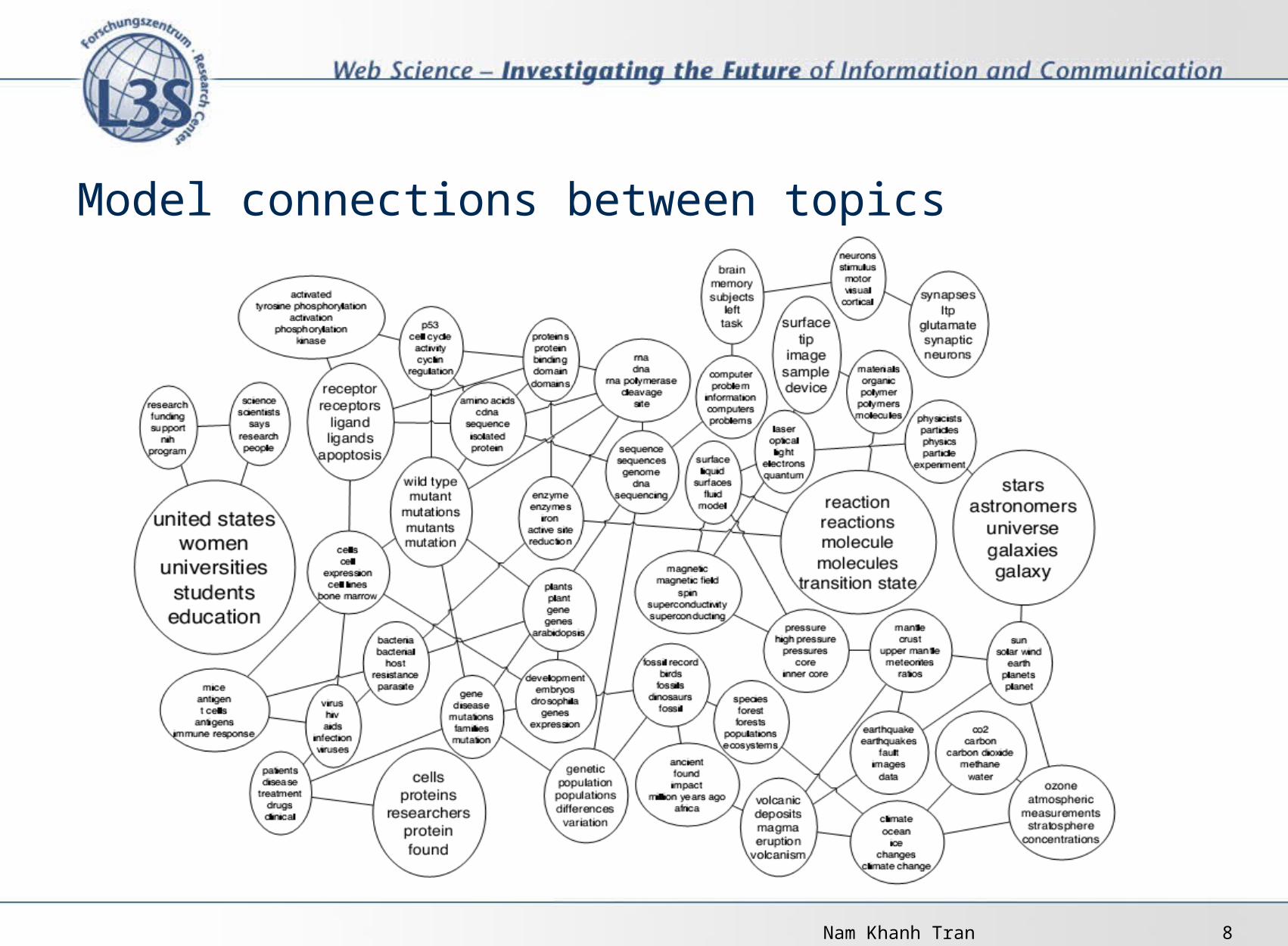
Model connections between topics

Nam Khanh Tran 9
Image annotation

Latent Dirichlet Allocation

Nam Khanh Tran 11
Latent Dirichlet Allocation
Introduction to LDA
The posterior distribution for LDA
Gibbs sampling

Nam Khanh Tran 12
Probabilistic modeling
Treat data as observations that arise from a generative probabilistic process that includes variables
For documents, the hidden variables reflect the thematic structure of the collection
Infer the hidden structure using posterior inference What are the topics that describe this collections?
Situate new data into the estimated model How does the query or new document fit into the estimated topic structure

Nam Khanh Tran 13
Intuition behind LDA
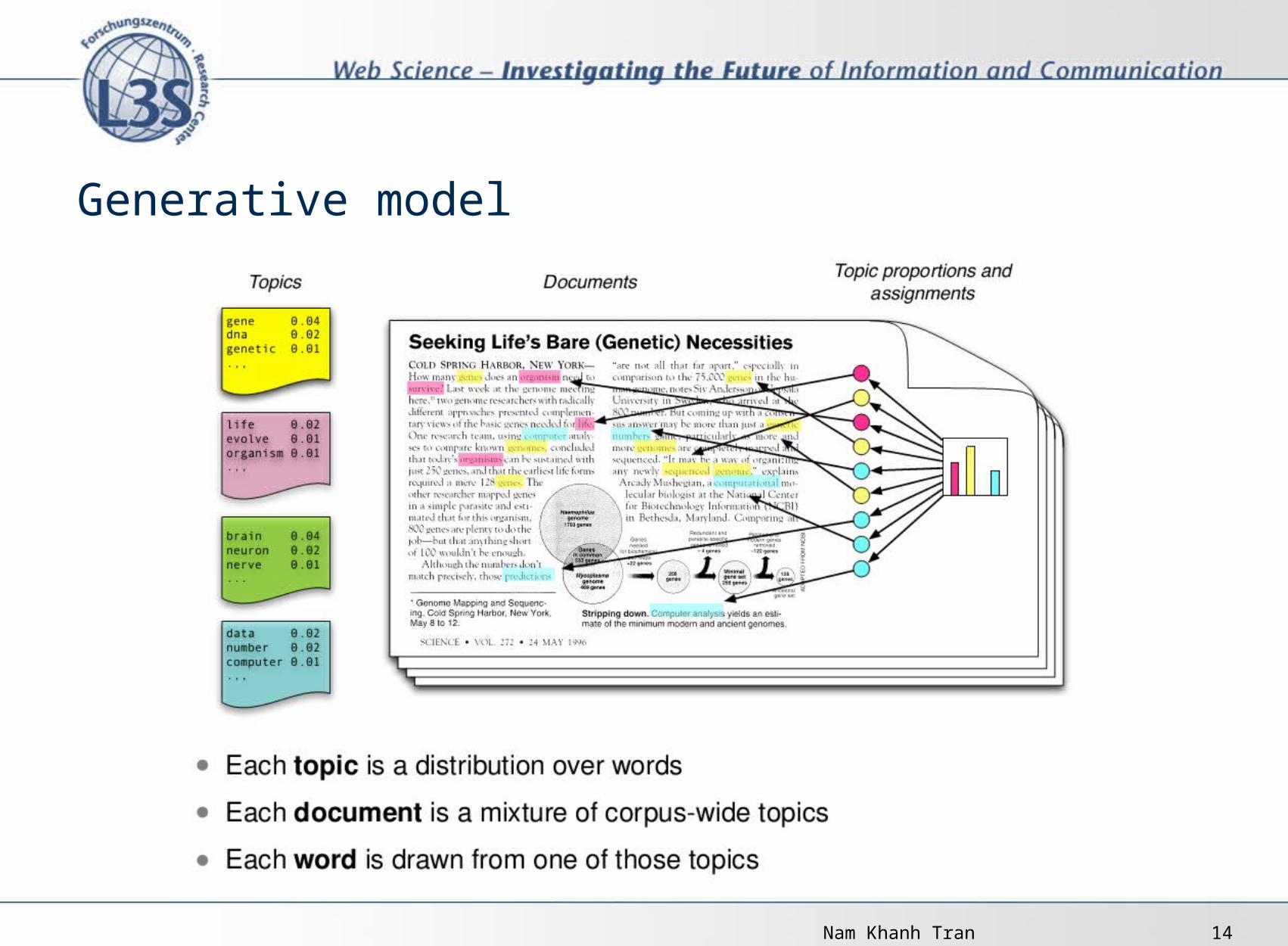
Nam Khanh Tran 14
Generative model

Nam Khanh Tran 15
The posterior distribution
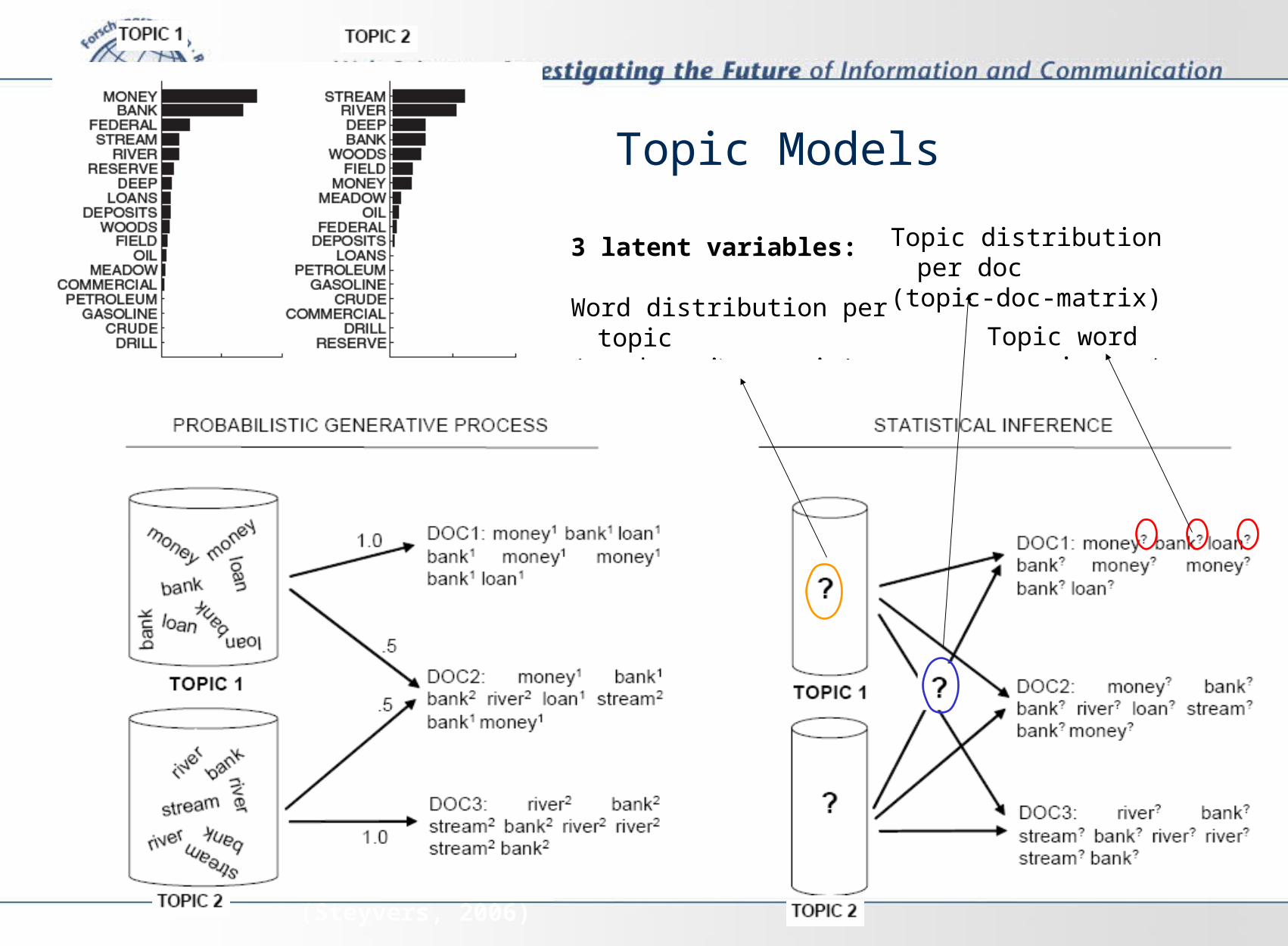
Topic Models
Topic 1 Topic 2
3 latent variables:
Word distribution per topic(word-topic-matrix)
Topic distribution per doc(topic-doc-matrix)
Topic word assignment
(Steyvers, 2006)

Topic models
Observed variables: Word-distribution per document
3 latent variables Topic distribution per document : P(z) = θ(d)
Word distribution per topic: P(w, z) = φ(z)
Word-Topic assignment: P(z|w)
Training: Learn latent variables on trainings-collection of documents
Test: Predict topic distribution θ(d) of an unseen document d

Latent Dirichlet Allocation (LDA)
Advantage: We learn topic distribution of a corpus we can predict topic distribution of an unseen document of this corpus by observing its words
Hyper-parameters α and β are corpus-level parameters are only sampled once
P( w | z, φ (z) )
P(φ(z) | β)
z
dzzd zPzwPPPdPwdP )|(*),|(*)|(*)|(*)(),( )()()()(
number of documentsnumber of words
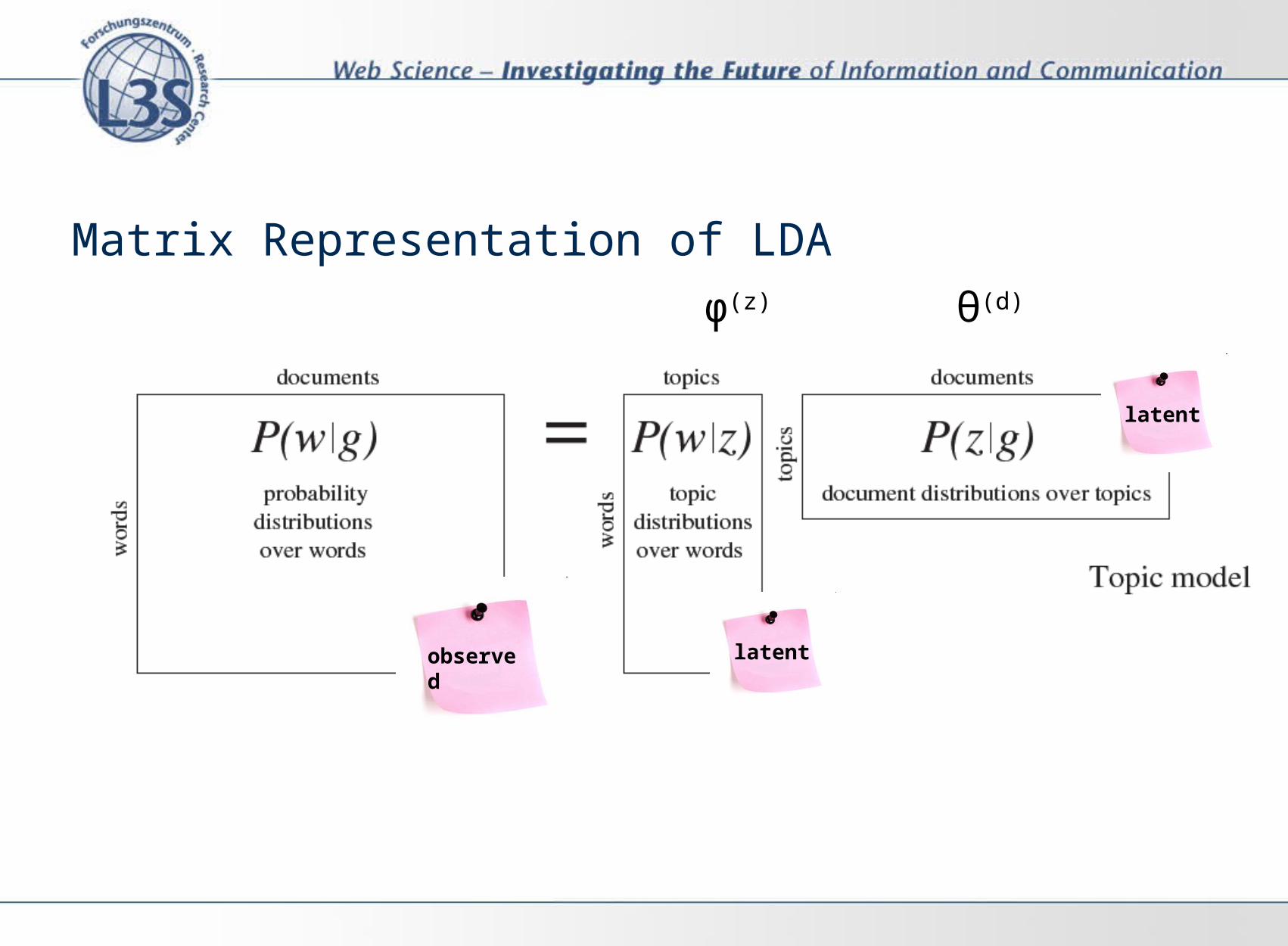
Matrix Representation of LDA
observed latent
latent
θ(d)φ(z)

Statistical Inference and Parameter Estimation
Key problem:Compute posterior distribution of the hidden variables given a document
Posterior distribution is intractable for exact inference
(Blei, 2003)
Latent Vars Observed VarsandPriors

Statistical Inference and Parameter Estimation
How can we estimate posterior distribution of hidden variables given a corpus of trainings-documents? Direct (e.g. via expectation maximization, variational inference or
expectation propagation algorithms)
Indirect i.e. estimate the posterior distribution over z (i.e. P(z)) Gibbs sampling, a form of Markov chain Monte Carlo, is often used
to estimate the posterior probability over a high-dimensional random variable z

Gibbs Sampling
Generates a sequence of samples from the joint probability distribution of two or more random variables.
Aim: compute posterior distribution over latent variable z Pre-request: we must know the conditional probability of z
P( zi = j | z-i , wi , di , . )

Gibbs Sampling for LDA
Random start
Iterative
For each word we compute
How dominant is a topic z in the doc d? How often was the topic z already used in doc d?
How likely is a word for a topic z? How often was the word w already assigned to topic z?
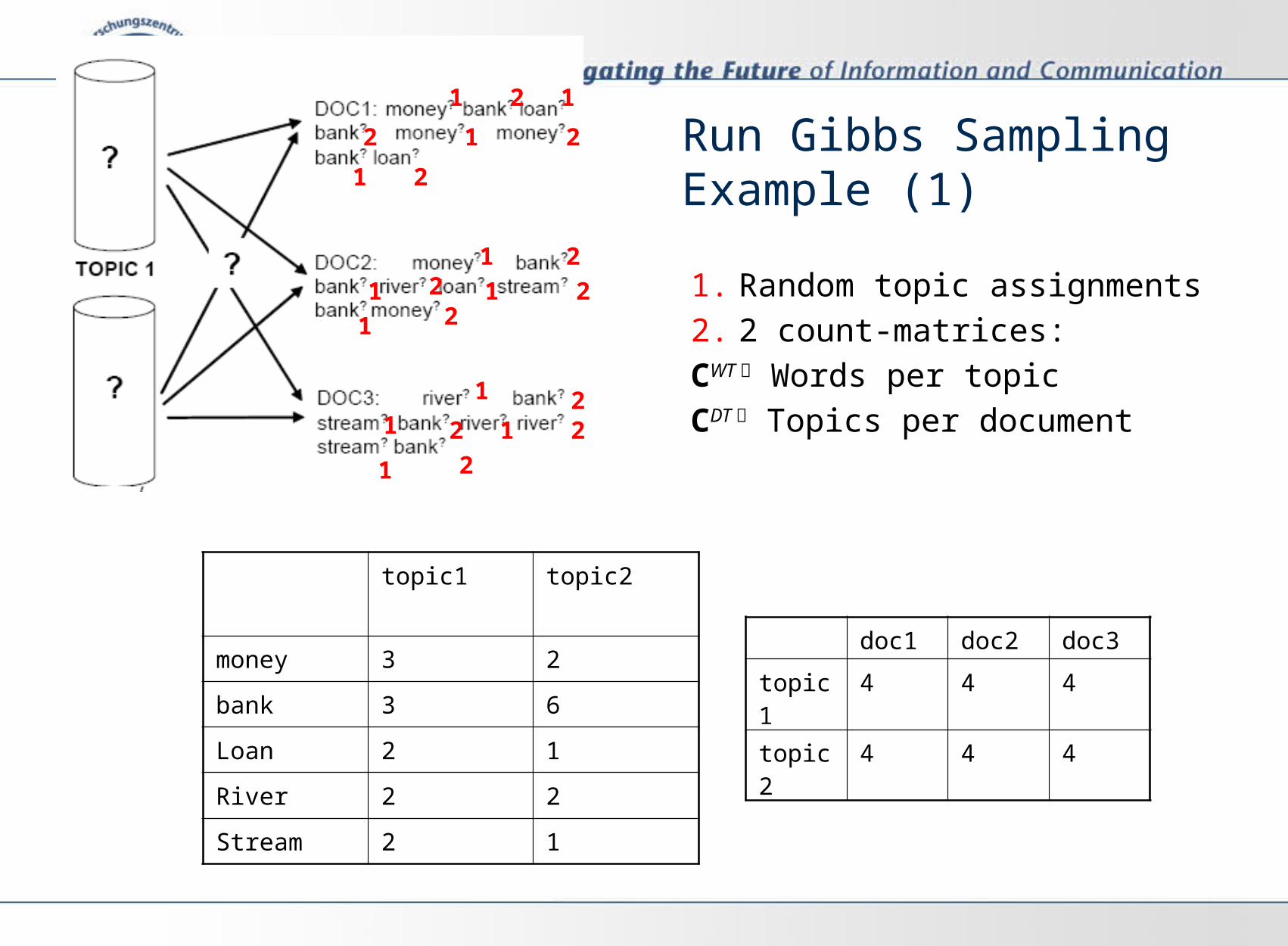
Run Gibbs Sampling Example (1)
topic1 topic2
money 3 2
bank 3 6
Loan 2 1
River 2 2
Stream 2 1
1 12
2 2
2
1
1
1 2
1 2 121
1 21 2 21
21
2
doc1 doc2 doc3
topic1 4 4 4
topic2 4 4 4
1. Random topic assignments
2. 2 count-matrices:
CWT Words per topic
CDT Topics per document

Gibbs Sampling for LDA
Probability that topic j is chosen for word wi, conditioned on all other assigned topics of words in this doc and all other observed vars.
Count number of times a word token wi was assigned to a topic j across all docs
Count number of times a topic j was already assigned to some word token in doc di
unnormalized!
=> divide the probability of assigning topic j to word wi by the sum over all topics T
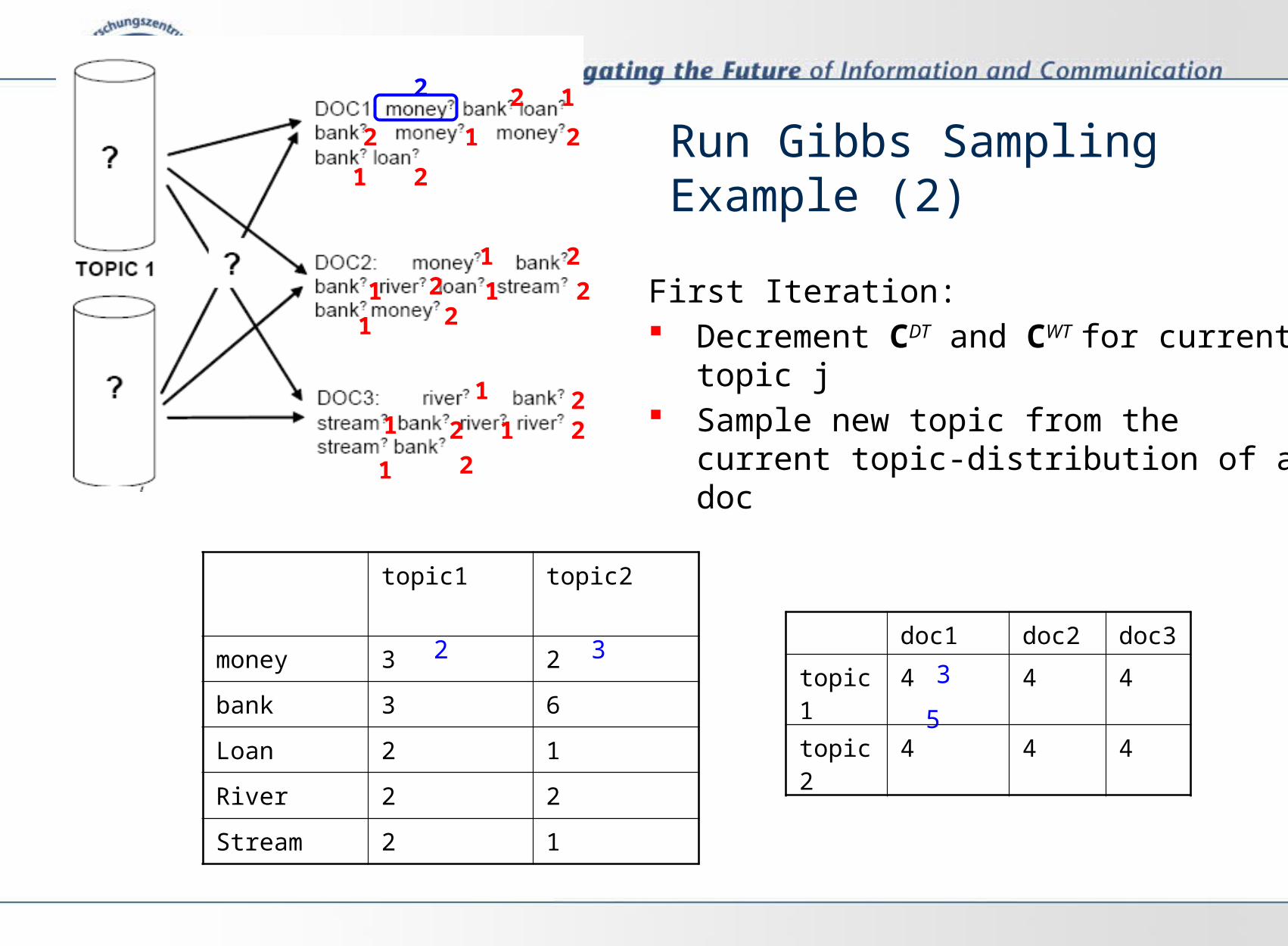
Run Gibbs Sampling Example (2)
topic1 topic2
money 3 2
bank 3 6
Loan 2 1
River 2 2
Stream 2 1
12
2 2
2
1
1
1 2
1 2 121
1 21 2 21
21
2
doc1 doc2 doc3
topic1 4 4 4
topic2 4 4 4
First Iteration: Decrement CDT and CWT for current topic j Sample new topic from the current topic-
distribution of a doc
32
2
5
3
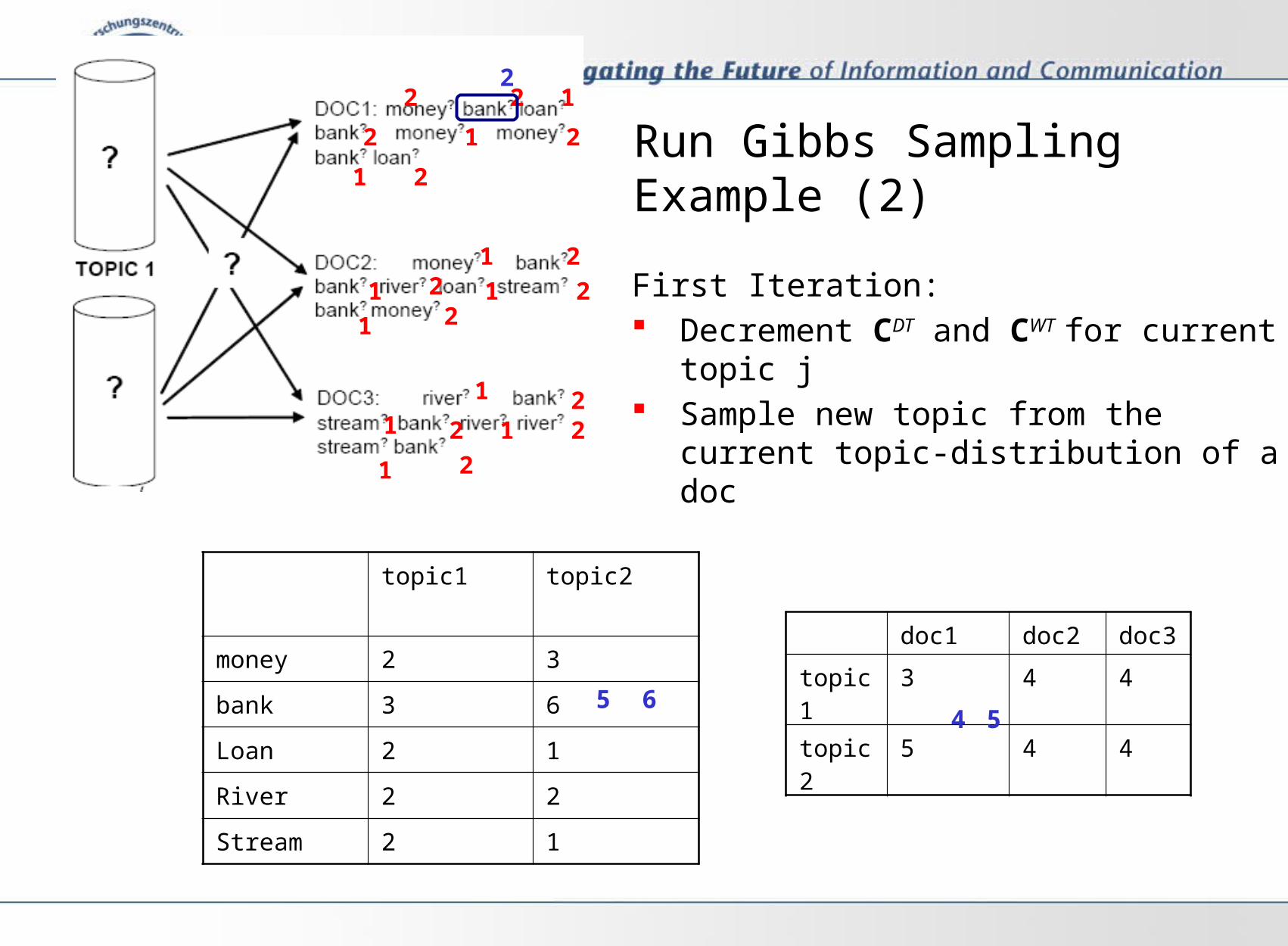
Run Gibbs Sampling Example (2)
topic1 topic2
money 2 3
bank 3 6
Loan 2 1
River 2 2
Stream 2 1
12
2 2
2
1
1
1 2
1 2 121
1 21 2 21
21
2
doc1 doc2 doc3
topic1 3 4 4
topic2 5 4 4
First Iteration: Decrement CDT and CWT for current topic j Sample new topic from the current topic-
distribution of a doc
2
4
2
55 6

Run Gibbs Sampling Example (3)
α = 50/T = 25 and β = 0.01
39.025*23
254*
01.0*57
01.05,.),,|2(
iii dbankztopiczP
“Bank” is assigned to Topic 2
19.025*24
253*
01.0*58
01.03,.),,|1(
iii dbankztopiczP
How often were all other topics used in doc di
How often was topic j used in doc di
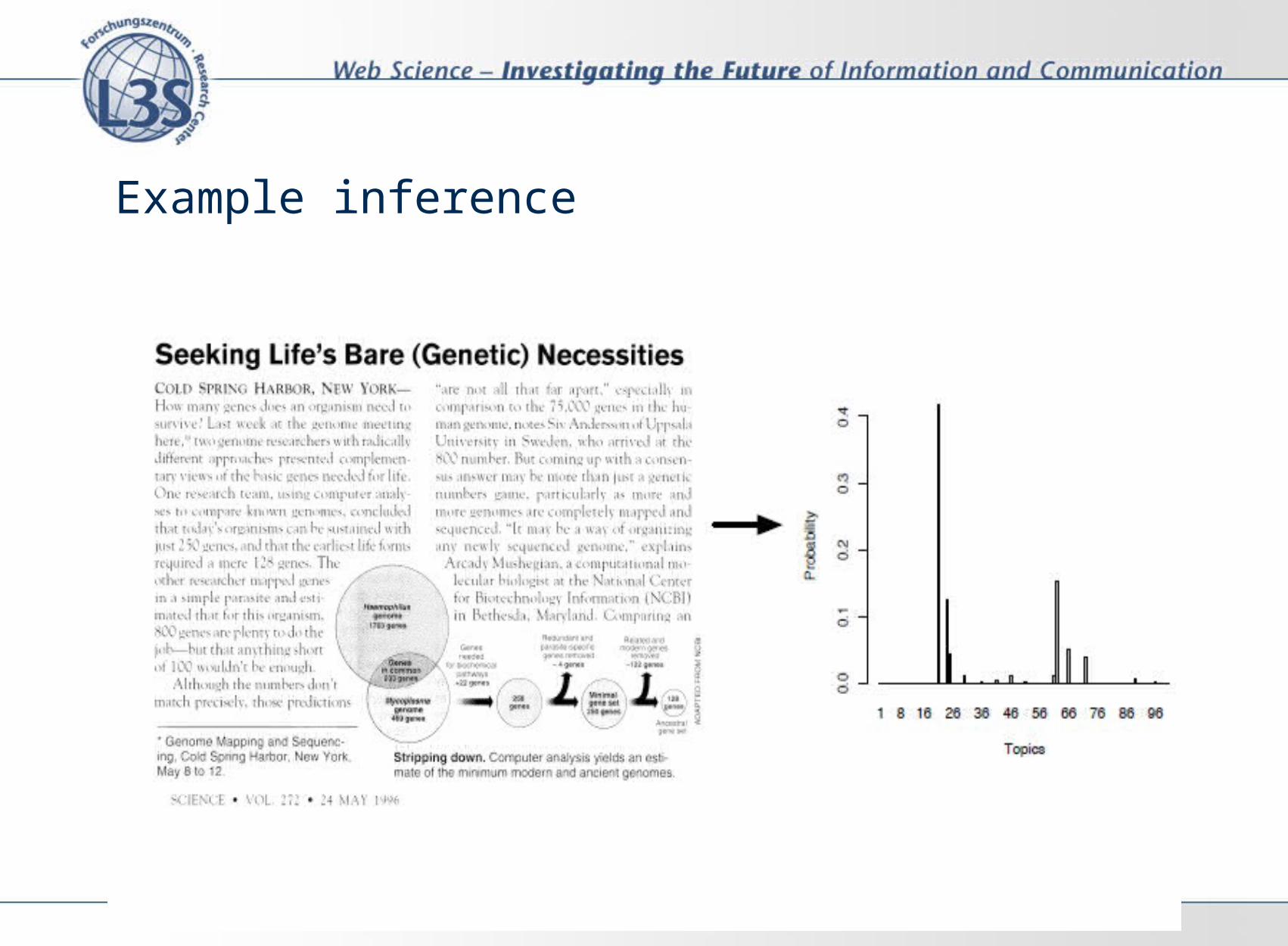
Example inference

Topics vs. words

Visualizing a document
Use the posterior topic probabilities of each document and the posterior topic assignments to each word

Document similarity
Two documents are similar if they assign similar probabilities to topics

Nam Khanh Tran 38
Beyond Latent Dirichlet Allocation

Nam Khanh Tran 39
Extending LDA
LDA is a simple topic model
It can be used to find topics that describe a corpus
Each document exhibits multiple topics
How can we build on this simple model of text?

Nam Khanh Tran 40
Extending LDA
LDA can be embedded in more complicated models, embodying further intuitions about the structure of the texts (e.g., account for syntax, authorship, dynamics, correlation, and other structure)
The data generating distribution can be changed. We can apply mixed-membership assumptions to many kinds of data (e.g., models of images, social networks, music, computer code and other types)
The posterior can be used in many ways (e.g., use inferences in IR, recommendation, similarity, visualization and other applications)

Nam Khanh Tran 41
Dynamic topic models
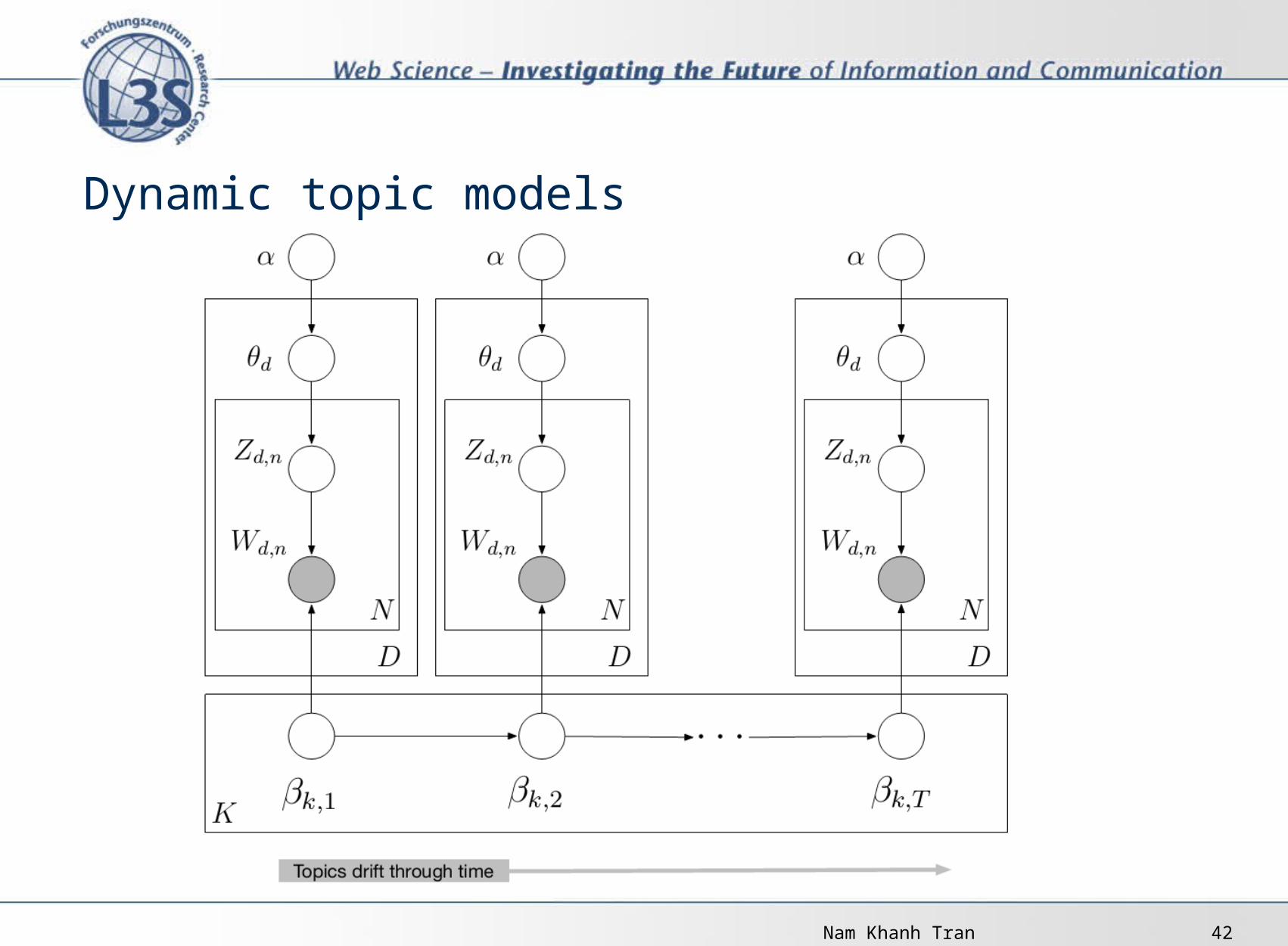
Nam Khanh Tran 42
Dynamic topic models

Nam Khanh Tran 43
Dynamic topic models
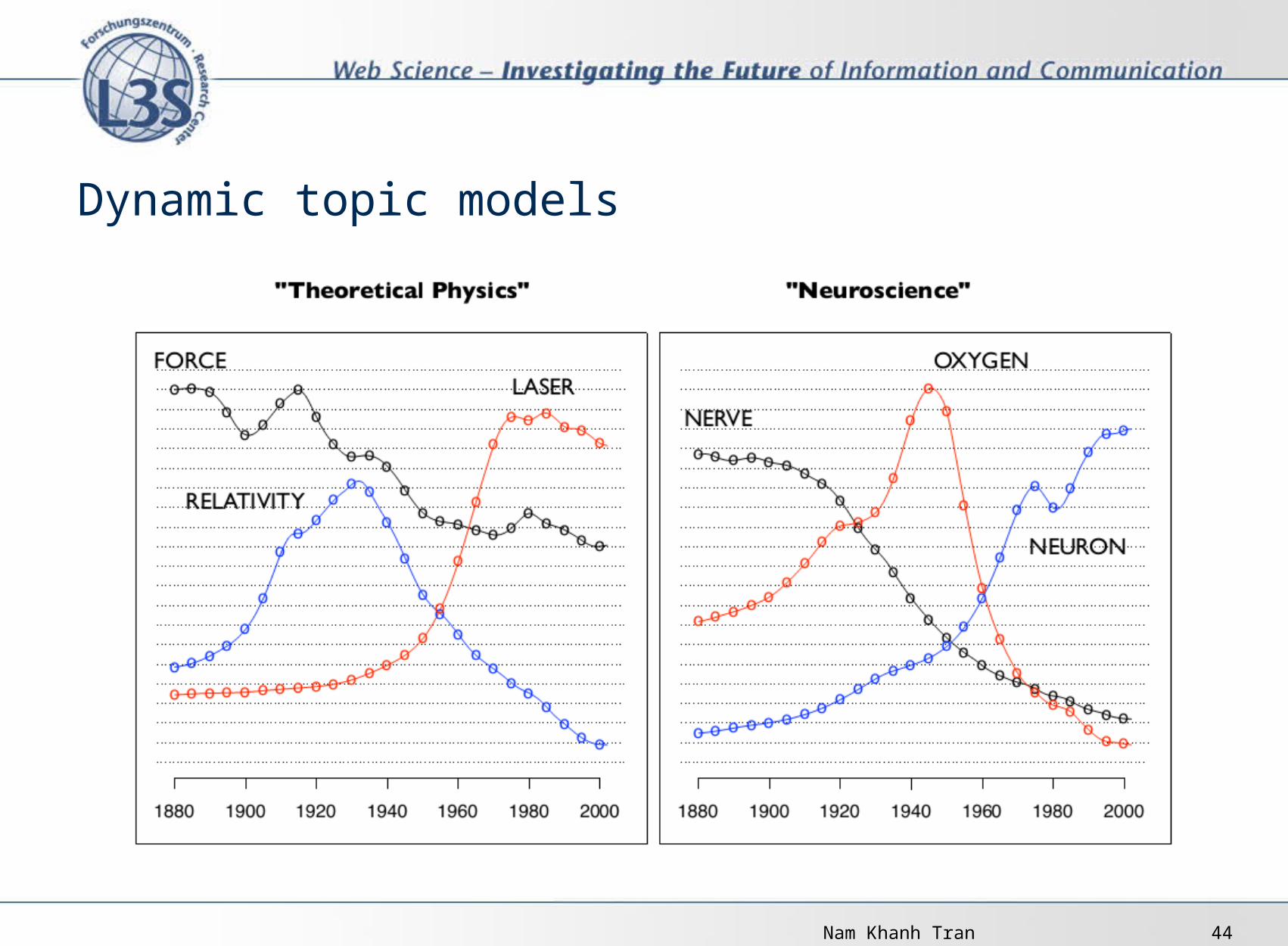
Nam Khanh Tran 44
Dynamic topic models
Nam Khanh Tran 45
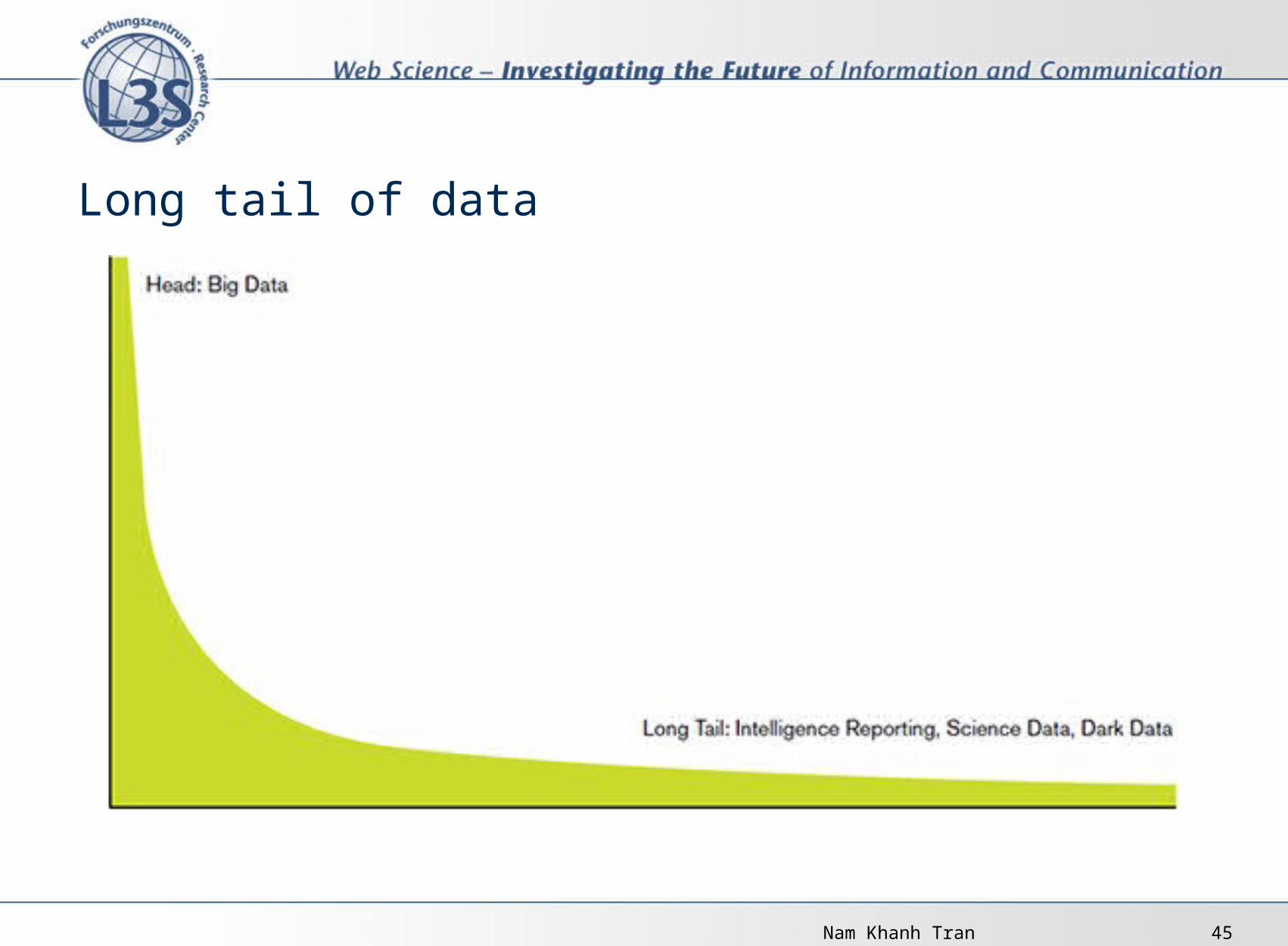
Long tail of data
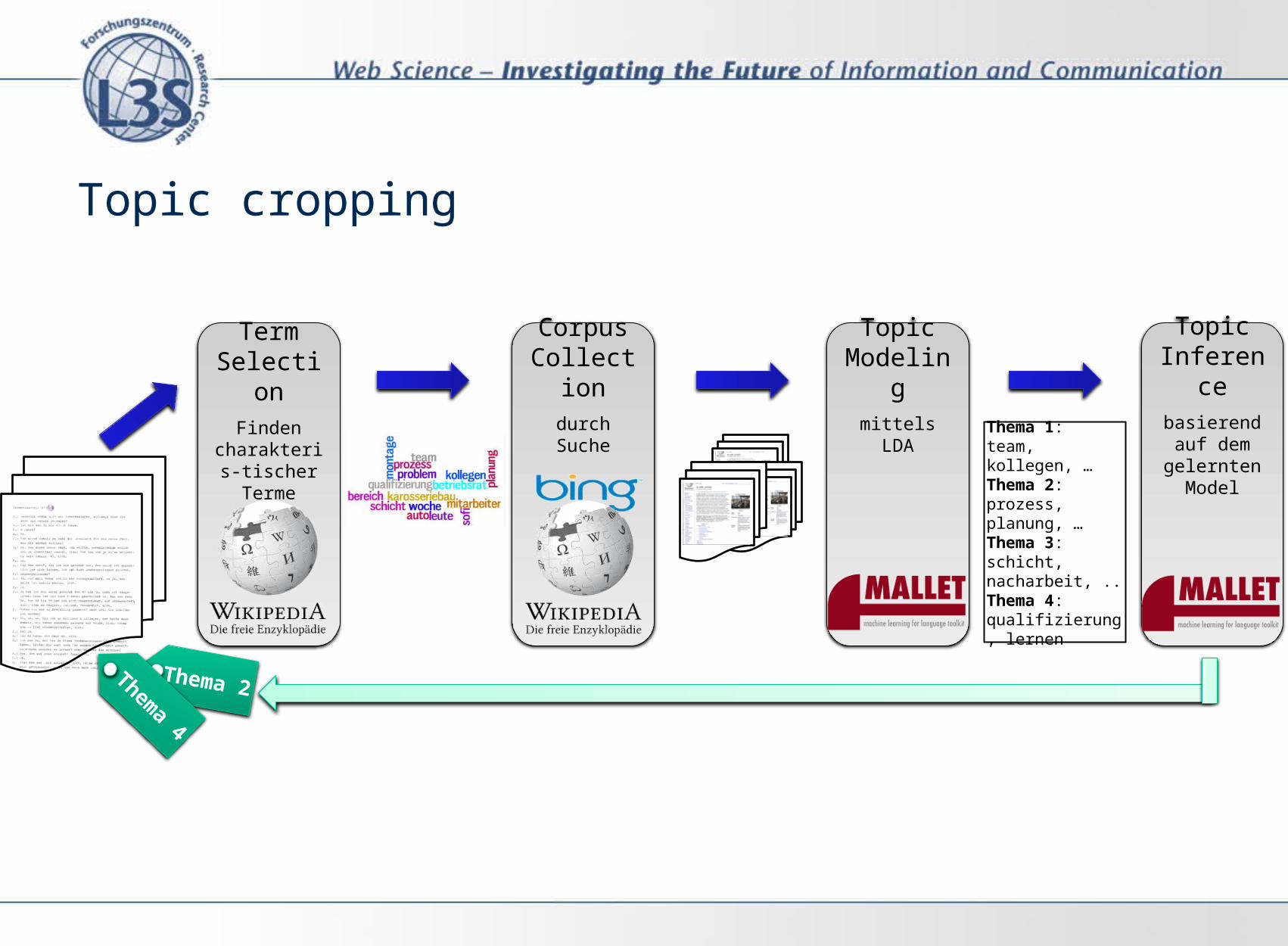
Topic Modelingmittels LDA
Corpus Collectio
ndurch Suche
Term Selection
Finden charakteris-
tischer Terme
Thema 1: team, kollegen, …Thema 2: prozess, planung, …Thema 3: schicht, nacharbeit, ..Thema 4: qualifizierung, lernen
Topic Inference
basierend auf dem
gelernten Model
Thema 2
Thema 4
Topic cropping

Nam Khanh Tran 47
Implementations of LDA
There are many available implementations of topic modeling
LDA-C : A C implementation of LDA
Online LDA: A python package for LDA on massive data
LDA in R: Package in R for many topic models
Mallet: Java toolkit for statistical NLP

Nam Khanh Tran 48
Demo

Nam Khanh Tran 49
Discussion