©2003 dror feitelson parallel computing systems part iii: job scheduling dror feitelson hebrew...
Post on 19-Dec-2015
218 views
TRANSCRIPT

©2003 Dror Feitelson
Parallel Computing SystemsPart III: Job Scheduling
Dror Feitelson
Hebrew University

©2003 Dror Feitelson
Types of Scheduling
• Task scheduling– Application is partitioned into tasks– Tasks have precedence constraints– Need to map tasks to processors– Need to consider communications too– Part of creating an application
• Job scheduling– Scheduling competing jobs belonging to
different users– Part of the operating system

©2003 Dror Feitelson
We’ll Focus on Job Scheduling

©2003 Dror Feitelson
Dimensions of Scheduling
• Space slicing– Partition the machine into disjoint parts– Jobs get exclusive use of a partition
• Time slicing– Multitasking on each processor– Similar to conventional systems
• Use both together
• Use none – batch scheduling on dedicated machine
Feitelson, RC 19790 1997

©2003 Dror Feitelson
Space Slicing
• Fixed: predefined partitions– Used on CM-5
• Variable: carve out number requested– Used on most systems: Paragon, SP, …– Some restrictions may apply, e.g. torus
• Adaptive: modify request size according to system considerations– Less nodes if more jobs are present
• Dynamic: modify size at runtime too

©2003 Dror Feitelson
Time Slicing
• Uncoordinated: each PE schedules on its ownLocal queue: processes allocated to PEs– Requires load balancing
Global queue– Provides automatic load sharing– Queue may become a bottleneck
• Coordinated across multiple Pes– Explicit gang scheduling– Implicit co-scheduling

©2003 Dror Feitelson
run to comp.
time slicing
local queue
global queue
gang sched.
full machine
Illiac IV
MPP GF11
StarOS Tera
NYU Ult. Dynix
2level/top
Alliant FX/8
space slicing
fixed or powers
of 2
hypercube CM-2
iPSC/2 nCUBE
CM-5 Cedar
flexibleIBM SP
2level/bottransput.
Chrysalis
Mach ParPar
LLNL

©2003 Dror Feitelson
Scheduling Framework
Arriving
jobs
Terminating
jobs
Allocation
Partitioning with run-to-completion– Order of taking jobs from the queue– Re-definition of job size

©2003 Dror Feitelson
Scheduling Framework
Arriving
jobs
Terminating
jobs
Preemption
Time slicing with preemption– Setting time quanta and priorities– May jobs migrate/change size when preempted?

©2003 Dror Feitelson
Memory Considerations
• The processes of a parallel application typically communicate
• To make good progress, they should all run simultaneously
• A process that suffers a page fault is unavailable for communication
• Paging should therefore be avoided

©2003 Dror Feitelson
Scheduling Framework
Dispatching
Memory allocation
Two stages of scheduling– Or three stages, with swapping

©2003 Dror Feitelson
Variable Partitioning

©2003 Dror Feitelson
Batch Systems
• Define system of queues with different combinations of resource bounds
• Schedule FCFS from these queues
• Different queues active at prime vs. non-prime time
• Sophisticated/complex services provided– Accounting and limits on users/groups– Staging of data in and out of machine– Political prioritization as needed

©2003 Dror Feitelson
Example – SDSC Paragonnodes
1 4 8 16 32 64 128 256 *15m q4t
1h q4s q8s
Q8s
q16s
Q16s
q32s
Q32s
q64s
4h q32m
Q32m
q64m
Q64m
q128m
Q128m
q256m
Q256m
12h q1l q32l
Q32l
q64l
Q64l
q128l
Q128l Q256l
* qstb
Qstb
tim
e
16MB
32MB
Low priority
Wan et al., JSSPP 1996

©2003 Dror Feitelson
The Problem
• Fragmentation– If the first queued job needs more processors
than are available, need to wait for more to be freed
– Available processors remain idle during the wait
• FCFS (first come first serve)– Short jobs may be stuck behind long jobs in the
queue

©2003 Dror Feitelson
The Solution
• Out of order scheduling– Allows for better packing of jobs– Allows for prioritization according to desired
considerations

©2003 Dror Feitelson
Backfilling
• Allow jobs from the back of the queue to jump over previous jobs
• Make reservations for jobs at the head of the queue to prevent starvation
• Requires estimates of job runtimes
Lifka, JSSPP 1995

©2003 Dror Feitelson
Example
job2
job1
time
proc
esso
rs
job3
job4
FCFS

©2003 Dror Feitelson
Example
job2
job1
time
proc
esso
rs
job3
job4
Backfilingreservation

©2003 Dror Feitelson
Parameters
• Order for going over the queue– FCFS– Some prioritized order (Maui)
• How many reservations to make– Only one (EASY)– For all skipped jobs (Conservative)– According to need
• Lookahead– Consider one job at a time– Look deeper into the queue

©2003 Dror Feitelson
EASY Backfilling
Extensible Argonne Scheduling System(first large IBM SP installation)
• Definitions:– Shadow time: time at which first queued job
can run– Extra processors: processors left over when
first job runs
• Backfill if– Job will terminate by shadow time– Job needs less than extra processors
Lifka, JSSPP 1995

©2003 Dror Feitelson
First Case
job2
time
proc
esso
rs
job3
job4
shadow time

©2003 Dror Feitelson
Second Case
job2
job1
time
proc
esso
rs
job3
job4
extra processors

©2003 Dror Feitelson
Properties
• Unbounded delay– Backfill jobs will not delay first queued job– But they may delay other queued jobs…
Mu’alem & Feitelson, IEEE TPDS 2001

©2003 Dror Feitelson
Delay
job1
job4
time
proc
esso
rs
job2job3

©2003 Dror Feitelson
Delay
job1
time
proc
esso
rs
job2job3
job4
delay

©2003 Dror Feitelson
Properties
• Unbounded delay– Backfill jobs will not delay first queued job– But they may delay other queued jobs…
• No starvation– Delay of first queued job is bounded by runtime
of current jobs– When it runs, the second queued job becomes
first– It is then immune of further delays
Mu’alem & Feitelson, IEEE TPDS 2001

©2003 Dror Feitelson
User Runtime Estimates
• Small estimates allow job to backfill and skip the queue
• Too short estimates risk the job being killed because it exceeded its time
• So estimates may be expected to be accurate

©2003 Dror Feitelson
They Aren’t
Mu’alem & Feitelson, IEEE TPDS 2001

©2003 Dror Feitelson
Surprising Consequence
Performance is actually better if runtime estimates are inaccurate!
Experiment: replace user estimates by up to f times the actual runtime(Data for KTH)
f resp. time slowdown
0 15001 67.6
1 14717 67.0
3 14645 62.7
10 14880 63.7
30 15028 64.7
100 15110 64.9
users 15568 84.0

©2003 Dror Feitelson
Exercise
Understand why this happens
• Run simulations of EASY backfilling with real workloads
• Insert instrumentation to record detailed behavior
• Try to find why f10 is better than f=1
• Try to find why user estimates are so bad

©2003 Dror Feitelson
Hint
• It may be beneficial to look at different job classes
• Example: EASY vs. Conservative– EASY favors small long jobs: can backfill
despite delaying non-first jobs– This comes at expense of larger short jobs– Happens more with user estimates than with
accurate estimates
Small Large
Short
Long
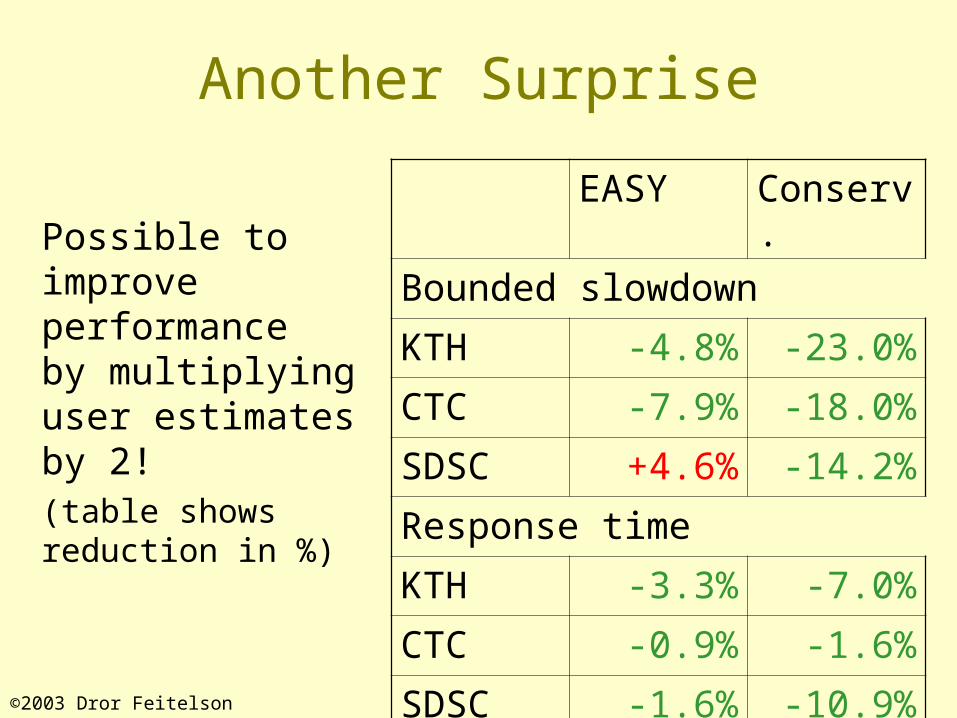
©2003 Dror Feitelson
Another Surprise
Possible to improve performance by multiplying user estimates by 2!(table shows reduction in %)
EASY Conserv.
Bounded slowdown
KTH -4.8% -23.0%
CTC -7.9% -18.0%
SDSC +4.6% -14.2%
Response time
KTH -3.3% -7.0%
CTC -0.9% -1.6%
SDSC -1.6% -10.9%

©2003 Dror Feitelson
The MAUI SchedulerQueue order depends on• Waiting time in queue
– Promote equitable service
• Fair share status• Political priority• Job parameters
– Favor small/large jobs etc.
• Number of times skipped by backfill– Prevent starvation
• Problem: conflicts are possible, hard to figure out what will happen
Jackson et al, JSSPP 2001

©2003 Dror Feitelson
Fair Share
• Actually unfair: strive for specific share
• Based on comparison with historical data
• Parameters:– How long to keep information– How to decay old information– Specifying shares for user or group– Shares are upper/lower bound or both
• Handling of multiple resources by maximal “PE equivalents” (usage out of total available)

©2003 Dror Feitelson
Lookahead
• EASY uses a greedy algorithm and considers jobs in one given order
• The alternative is to consider a set of jobs at once and try to derive an optimal packing

©2003 Dror Feitelson
Dynamic Programming
• Outer loop: number of jobs that are being considered
• Inner loop: number of processors that are available
Edi Shmueli, IBM Haifa
p=1 p=2 p=3 p=4
no job 0 0 0 0
Job 1
Job 2 u 2,3
Job 3
Achievable utilization on 3
processors using only first 2 jobs

©2003 Dror Feitelson
Cell Update
• If j.size > p job is too big to consider
uj,p = uj-1,p
j is not selected• Else consider adding job j
u’ = uj-1,p-j.size + j.size
if u’ > uj-1,p then uj,p = u’j is selected
else uj,p = uj-1,p
j is not selected

©2003 Dror Feitelson
Preventing Starvation
• Option I: only use jobs that will terminate by the shadow time
• Option II: make a reservation for the first queued job (as in EASY)
Requires a 3D data structure:1. Jobs being considered2. Processors being used now3. Extra processors used at the shadow time

©2003 Dror Feitelson
Dynamic Programming
• In the end the bottom-right cell contains the maximal achievable utilization
• The set of jobs to schedule is obtained by the path of selected jobs

©2003 Dror Feitelson
Performance
• Backfilling leads to significant performance gains relative to FCFS
• More reservations reduce performance somewhat (EASY better than conservative)
• Lookahead improves performance somewhat

©2003 Dror Feitelson
Dynamic Partitioning

©2003 Dror Feitelson
Two-Level Scheduling
• Bottom level – processor allocation– Done by the system– Balance requests with availability– Can change at runtime
• Top level – process scheduling– Done by the application– Use knowledge about priorities, holding locks,
etc.

©2003 Dror Feitelson
Programming Model
• Applications required to handle arbitrary changes in allocated processors
• Workpile model– Easy to change number of worker threads
• Scheduler activations– Any change causes an upcall into the
application, which can reconsider what to run

©2003 Dror Feitelson
Equipartitioning• Strive to give all applications equal numbers of
processors– When a job arrives take some processors from each
running job– When it terminates, give some to each other job
• Fair and similar to processor sharing• Caveats
– Applications may have a maximal number of processors they can use efficiently
– Applications may need a minimal number of processors due to memory constraints
– Reconfigurations require many process migrations
Not an issue for shared memory

©2003 Dror Feitelson
Folding
• Reduce processor preemptions by selecting a partition and dividing it in half
• All partition sizes are powers of 2
• Easier for applications: when halved, multitask two processes on each processor
McCann & Zahorjan, SIGMETRICS 1994

©2003 Dror Feitelson
The Bottom Line
• Places restrictions on programming model– OK for workpile, Cray autotasking– Not suitable for MPI
• Very efficient at the system level– No fragmentation– Load leads to smaller partitions and reduced
overheads for parallelism
• Of academic interest only, in shared memory architectures

©2003 Dror Feitelson
Gang Scheduling

©2003 Dror Feitelson
Definition
• Processes are mapped one-to-one on processors
• Time slicing is used for multiprogramming• Context switching is coordinated across
processors– All processes are switched at the same time – Either all run or none do
• This applies to gangs, typically all processes in a job

©2003 Dror Feitelson
CoScheduling
• Variant in which an attempt is made to schedule all the processes, but subsets may also be scheduled
• Assumes “process working set” that should run together to make progress
• Does this make sense?– All processes are active entities– Are some more important than others?
Ousterhout, ICDCS 1982

©2003 Dror Feitelson
Advantages
• Compensate for lack of knowledge– If runtimes are not known in advance, preemption
prevents short jobs from being stuck– Same as in conventional systems
• Retain dedicated machine model– Application doesn’t need to handle interference
by system (as in dynamic partitioning)– Allow use of hardware support for fine-grain
communication and synchronization
• Improve utilization

©2003 Dror Feitelson
Utilization
• Assume a 128-node machine
• A 64-node job is running
• A 32-node job and a 128-node job are queued
• Should the 32-node job be started?
Feitelson &Jette, JSSPP 1997

©2003 Dror Feitelson
Best Case
Start 32-node job leading to 75% utilization
left idle
time
32-node job
64-node job

©2003 Dror Feitelson
Worst Case
Start 32-node job, but then 64-node job terminates leading to 25% utilization
left idle
time
32
64

©2003 Dror Feitelson
With Gang Scheduling
Start 32-node job in slot with 64-node job, and 128-node job in another slot. Utilization is 87.5% (or 62.5% if 64-node job terminates)
time
32
64
128

©2003 Dror Feitelson
Disadvantages
• Overhead for context switching
• Overhead for coordinating context switching across many processors
• Reduced cache efficiency
• Memory pressure – more jobs need to be memory resident

©2003 Dror Feitelson
Implementation
• Pack jobs in processor-time space– Assign processes to processors– Is migration allowed?
• Perform coordinated context switching– Decide on time slices: are all equal?

©2003 Dror Feitelson
Packing
• Ousterhout matrix– Rows represent time slices– Columns represent processors
• Each job mapped to a single row with enough space
• Optimizations– Slot unification when occupancy is
complementary– Alternate scheduling

©2003 Dror Feitelson
Example
Ousterhout matrix
Ousterhout, ICDCS 1982

©2003 Dror Feitelson
Fragmentation
There can be unused space in each slot
(Unused slots are not a problem)

©2003 Dror Feitelson
Alternate Scheduling
Effect can be reduced by running jobs in additional slots
This depends on good packing
Ousterhout, ICDCS 1982

©2003 Dror Feitelson
Buddy System
• Allocate processors according to a buddy system– Successive partitioning into halves as needed
• Used and unused processors in different slots will tend to be aligned
• This facilitates alternate schedulingFeitelson &Rudolph, Computer 1990

©2003 Dror Feitelson
Results
Feitelson, JSSPP 1996

©2003 Dror Feitelson
Coordinated Context Switching
• Typically coordinated by a central manager
• Executed by local daemons
• Use SIGSTOP/SIGCONT to leave only one runnable process

©2003 Dror Feitelson
STORM
• Base job execution and scheduling of 3 primitives– xfer-&-signal (broadcast)– test-event (optional block)– comp-&-write (on global variables)
• Implemented efficiently using NIC and network support
Frachtenberg et al., SC 2002

©2003 Dror Feitelson
Flexible Co-Scheduling

©2003 Dror Feitelson
Flexibility
Idea: reduce constraints of strict gang scheduling
• DCS: demand-based coscheduling
• ICS: implicit coscheduling
• FCS: flexible coscheduling
• Paired gang scheduling
The common factor: involve local scheduling

©2003 Dror Feitelson
DCS
• Coscheduling is good for threads that communicate or synchronize
• Prioritizing threads that communicate will cause them to be coscheduled on different nodes
Sobalvarro & Weihl, JSSPP 1995

©2003 Dror Feitelson
Algorithmic Details
• Switch to a thread that receives a message• But only if that thread has received less than its
fair share of the CPU– To prevent jobs with more messages from
monopolizing the system
• And only if the arriving message does not belong to a previous epoch– A new epoch started when some node switches
spontaneously– Prevents thrashing and allows a job to gain control
of the full machine

©2003 Dror Feitelson
ICS
• Priority-based schedulers automatically give priority to threads waiting on communication
• But need to ensure that sending thread stays scheduled until a reply arrives
• Do this with two-phase blocking, and wait for about 5 context-switch durations
Dusseau & Culler, SIGMETRICS 1996

©2003 Dror Feitelson
FCS
• Retain coordinated context switching across the machine
• But allow local scheduler to override global scheduling instructions according to local data
• Use local classification of processes into those that require gang scheduling and those that don’t
Frachtenberg et al., IPDPS 2003

©2003 Dror Feitelson
Implementation Details
• Instrument MPI library to measure compute time between calls (granularity) and wait time for communication to complete
• Use this to classify processes
• Data is aged exponentially
• Upon a coordinated context switch, decide whether to abide or use local scheduler

©2003 Dror Feitelson
Process Classification
Computation time per iteration
Com
mun
icat
ion
wai
t tim
e pe
r it
erat
ion
CS
F DC
Fine-grain and low wait: coscheduling
is effective
Fine grain but long wait: process is frustrated.
Don’t coschedule, but give priority Other processes
don’t care;use as filler

©2003 Dror Feitelson
Paired Gang Scheduling
• Monitor CPU activity of processes as they run
• Low CPU implies heavy I/O or communication
• Schedule pairs of complementary gangs together
Wiseman & Feitelson, IEEE TPDS 2003

©2003 Dror Feitelson
Scheduling Memory

©2003 Dror Feitelson
Memory Pressure
• With partitioning: memory requirements may set minimal partition size– May lead to underutilization of processors
• With gang scheduling: memory requirements may lead to excessive paging– No local context switching: processors remain
idle waiting for pages– However, no thrashing

©2003 Dror Feitelson
Paging
• Paging is asynchronous
• If two nodes communicate, and one suffers a page fault, the other will have to wait
• The whole application makes progress at the rate of the slowest process at each instant
• Effect is worse for finer grained applications

©2003 Dror Feitelson
Solutions
• Admission control– Allow jobs into the system only as long as
memory suffices
(variant: allow only 3 jobs…)– Jobs that do not fit may wait a long time
• Swapping– Perform long-range scheduling to allow queued
jobs a chance to run

©2003 Dror Feitelson
Admission Control
Dispatching
Memory allocation

©2003 Dror Feitelson
Problems
• Assessing memory requirements– Data size as noted in executable
Good for static Fortran code– Historical data from previous runs– Problem of dynamic allocations
• Blocking of short jobs
Batat & Feitelson, IPPS/SPDP 1999

©2003 Dror Feitelson
PerformancePrevention of paging compensates for blocking of short jobs
Batat & Feitelson, IPPS/SPDP 1999
0
1000
2000
3000
4000
5000
6000
0.3 0.4 0.5 0.6 0.7 0.8 0.9
system load
aver
age
resp
onse
time
1.25
1.5
1.75
1.99
1.5+
Add memoryconsiderations
Higher locality

©2003 Dror Feitelson
Swapping
DispatchingMemory allocation
Swapping

©2003 Dror Feitelson
Swapping Overhead
• m memory
• r bandwidth
• Swapping time is then 2m/r
Alverson et al., JSSPP 1995
time
m
Thread Arunning
Thread Brunning
Swapping A out
Swapping B in2/r

©2003 Dror Feitelson
Swapping Overhead
When swapping multiple jobs, each needs all its memory in order to run
Best memory utilization if handling jobs one at a time
Alverson et al., JSSPP 1995
time
Job A Job B
Job C Job D Job E
unusedmemory