170216 jts agbt_final
TRANSCRIPT

Nanopore sequencing of a human genome
AGBTFebruary 2017
Jared Simpson Ontario Institute for Cancer Research
& Department of Computer Science
University of Toronto

Overview
• Brief intro to nanopore sequencing and signal-level analysis• Initial results from sequencing a human genome at high coverage• Direct detection of cytosine methylation
2

Overview
• Brief intro to nanopore sequencing and signal-level analysis• Initial results from sequencing a human genome at high coverage• Direct detection of cytosine methylation
3
Disclosure: ONT provides research funding to my lab
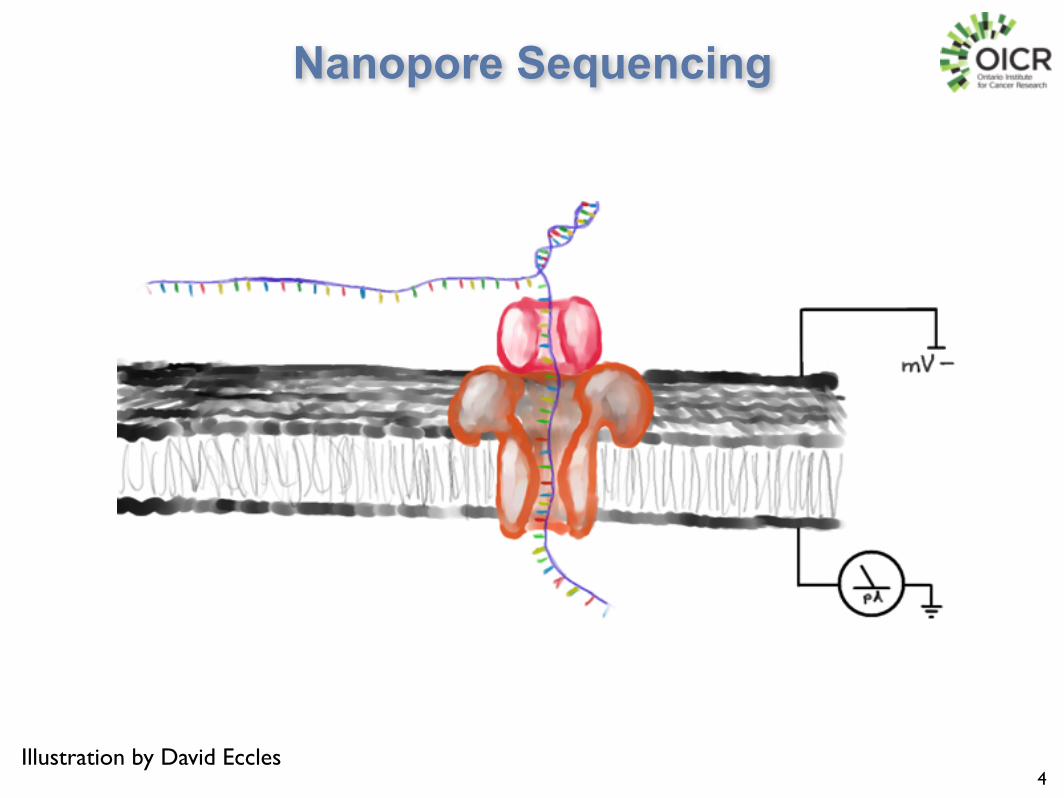
Nanopore Sequencing
4Illustration by David Eccles

Nanopore Sequencing
5
GCTACGATTSample Current
●●●
●
●
●●
●●●
●
●●●
●
●●●
●●●
●●●
●
●
●●
●
●
●
●●
●
●●●●●●●●●
●
●●
●●●
●●●●●●
●
●
●●●
●●
●●●●
●●●
●●
●●
●●●●●●●●
●●
●
●
●
●
●
●●●●
●
●●●●●●●●●●
●
●
●●
●
●●●
●●●
●
●
●●
●
●●●●●●●●
●●●●●●●●●●
●
●●●
●
●●●
●
●●
●●●
●
●●●●
●
●●
●
●
●●●
●
●●
●●●●
●
●●
●
●
●●●
●
●
●●●●●
●●●●●●●
●●●●●●●●●●●●●
●●
●●●●●●●●●●●●●
●
●●●●
●
●●●●●●
●●
●
●
●●●
●
●●
●●●●
●
●●●
●
●
●
●●●●●
●●
●
●●●
●●●●●●●●●●●●●●●●●
●
●●
●●●●●●
●
●●
●●●
●●
●
●●●
●
●
●●●
●
●●●●●
●
●●●●●●
●●
●
●●●●●●●
●
●
●
●●
●●
●
●
●●
●●●●
●●
●●●
●●
●
●●●
●
●●
●
●
●
●
●
●
●●
●●●●●●●●●
●●
●●●●●●●●
●●●●
●●●●●
●●●●●●
●●●●
●
●
●
●
●●
●●
●●●●●
●●●
●
●●●●
●
●
●
●
●●●
●●
●●●
●●●●
●
●
●●●●●●●●●
●
●
●
●
●●●●●●●●●●
●
●
●●
●
●●
●●
●●●●
●
●
●
●●●
●
●●●
●●●●●●
●●●
●
●●●●
●
●●●●●
●
●
●●
●●●
●
●
30
40
50
60
70
0.0 0.5 1.0time (s)
Cur
rent
(pA)
* illustrative simulation - not real data

Nanopore Sequencing
6
GCTACGATTSample Current
●●●
●
●
●●
●●●
●
●●●
●
●●●
●●●
●●●
●
●
●●
●
●
●
●●
●
●●●●●●●●●
●
●●
●●●
●●●●●●
●
●
●●●
●●
●●●●
●●●
●●
●●
●●●●●●●●
●●
●
●
●
●
●
●●●●
●
●●●●●●●●●●
●
●
●●
●
●●●
●●●
●
●
●●
●
●●●●●●●●
●●●●●●●●●●
●
●●●
●
●●●
●
●●
●●●
●
●●●●
●
●●
●
●
●●●
●
●●
●●●●
●
●●
●
●
●●●
●
●
●●●●●
●●●●●●●
●●●●●●●●●●●●●
●●
●●●●●●●●●●●●●
●
●●●●
●
●●●●●●
●●
●
●
●●●
●
●●
●●●●
●
●●●
●
●
●
●●●●●
●●
●
●●●
●●●●●●●●●●●●●●●●●
●
●●
●●●●●●
●
●●
●●●
●●
●
●●●
●
●
●●●
●
●●●●●
●
●●●●●●
●●
●
●●●●●●●
●
●
●
●●
●●
●
●
●●
●●●●
●●
●●●
●●
●
●●●
●
●●
●
●
●
●
●
●
●●
●●●●●●●●●
●●
●●●●●●●●
●●●●
●●●●●
●●●●●●
●●●●
●
●
●
●
●●
●●
●●●●●
●●●
●
●●●●
●
●
●
●
●●●
●●
●●●
●●●●
●
●
●●●●●●●●●
●
●
●
●
●●●●●●●●●●
●
●
●●
●
●●
●●
●●●●
●
●
●
●●●
●
●●●
●●●●●●
●●●
●
●●●●
●
●●●●●
●
●
●●
●●●
●
●●
●●
●●●●●●●●
●●●●
●●
●●●●
●
●●
●
●
●●●●
●●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●●
●●
●●●●●●●
●
●
●●
●●●●●
●●
●
●
●●
●
●●
●
●●
●
●
●
●●●●●●●
●●
●
●
●
●
●
●
●
●●
●
●●●
●
●●●●
30
40
50
60
70
0.0 0.5 1.0time (s)
Cur
rent
(pA)
* illustrative simulation - not real data

Nanopore Sequencing
7
GCTACGATTSample Current
●●●
●
●
●●
●●●
●
●●●
●
●●●
●●●
●●●
●
●
●●
●
●
●
●●
●
●●●●●●●●●
●
●●
●●●
●●●●●●
●
●
●●●
●●
●●●●
●●●
●●
●●
●●●●●●●●
●●
●
●
●
●
●
●●●●
●
●●●●●●●●●●
●
●
●●
●
●●●
●●●
●
●
●●
●
●●●●●●●●
●●●●●●●●●●
●
●●●
●
●●●
●
●●
●●●
●
●●●●
●
●●
●
●
●●●
●
●●
●●●●
●
●●
●
●
●●●
●
●
●●●●●
●●●●●●●
●●●●●●●●●●●●●
●●
●●●●●●●●●●●●●
●
●●●●
●
●●●●●●
●●
●
●
●●●
●
●●
●●●●
●
●●●
●
●
●
●●●●●
●●
●
●●●
●●●●●●●●●●●●●●●●●
●
●●
●●●●●●
●
●●
●●●
●●
●
●●●
●
●
●●●
●
●●●●●
●
●●●●●●
●●
●
●●●●●●●
●
●
●
●●
●●
●
●
●●
●●●●
●●
●●●
●●
●
●●●
●
●●
●
●
●
●
●
●
●●
●●●●●●●●●
●●
●●●●●●●●
●●●●
●●●●●
●●●●●●
●●●●
●
●
●
●
●●
●●
●●●●●
●●●
●
●●●●
●
●
●
●
●●●
●●
●●●
●●●●
●
●
●●●●●●●●●
●
●
●
●
●●●●●●●●●●
●
●
●●
●
●●
●●
●●●●
●
●
●
●●●
●
●●●
●●●●●●
●●●
●
●●●●
●
●●●●●
●
●
●●
●●●
●
●●
●●
●●●●●●●●
●●●●
●●
●●●●
●
●●
●
●
●●●●
●●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●●
●●
●●●●●●●
●
●
●●
●●●●●
●●
●
●
●●
●
●●
●
●●
●
●
●
●●●●●●●
●●
●
●
●
●
●
●
●
●●
●
●●●
●
●●●●
●
●●
●
●
●●
●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●●
●
●●●●●●
●
●
●●
●●
●●●
●
●
●●
●
●
●
●●●
●
●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●●
●●●
●●
●
●●
●
●●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●●●
●
●
●●
●●
●●
●
●
●
●
●●●
●
●
●●
●●
●●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●●●
●
●●
●
●
●
●●
●●
●
●
●●
●
●●
●●
●●
●
●
●
●
30
40
50
60
70
0.0 0.5 1.0time (s)
Cur
rent
(pA)
* illustrative simulation - not real data

Nanopore Sequencing
8
GCTACGATTSample Current
●●●
●
●
●●
●●●
●
●●●
●
●●●
●●●
●●●
●
●
●●
●
●
●
●●
●
●●●●●●●●●
●
●●
●●●
●●●●●●
●
●
●●●
●●
●●●●
●●●
●●
●●
●●●●●●●●
●●
●
●
●
●
●
●●●●
●
●●●●●●●●●●
●
●
●●
●
●●●
●●●
●
●
●●
●
●●●●●●●●
●●●●●●●●●●
●
●●●
●
●●●
●
●●
●●●
●
●●●●
●
●●
●
●
●●●
●
●●
●●●●
●
●●
●
●
●●●
●
●
●●●●●
●●●●●●●
●●●●●●●●●●●●●
●●
●●●●●●●●●●●●●
●
●●●●
●
●●●●●●
●●
●
●
●●●
●
●●
●●●●
●
●●●
●
●
●
●●●●●
●●
●
●●●
●●●●●●●●●●●●●●●●●
●
●●
●●●●●●
●
●●
●●●
●●
●
●●●
●
●
●●●
●
●●●●●
●
●●●●●●
●●
●
●●●●●●●
●
●
●
●●
●●
●
●
●●
●●●●
●●
●●●
●●
●
●●●
●
●●
●
●
●
●
●
●
●●
●●●●●●●●●
●●
●●●●●●●●
●●●●
●●●●●
●●●●●●
●●●●
●
●
●
●
●●
●●
●●●●●
●●●
●
●●●●
●
●
●
●
●●●
●●
●●●
●●●●
●
●
●●●●●●●●●
●
●
●
●
●●●●●●●●●●
●
●
●●
●
●●
●●
●●●●
●
●
●
●●●
●
●●●
●●●●●●
●●●
●
●●●●
●
●●●●●
●
●
●●
●●●
●
●●
●●
●●●●●●●●
●●●●
●●
●●●●
●
●●
●
●
●●●●
●●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●●
●●
●●●●●●●
●
●
●●
●●●●●
●●
●
●
●●
●
●●
●
●●
●
●
●
●●●●●●●
●●
●
●
●
●
●
●
●
●●
●
●●●
●
●●●●
●
●●
●
●
●●
●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●●
●
●●●●●●
●
●
●●
●●
●●●
●
●
●●
●
●
●
●●●
●
●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●●
●●●
●●
●
●●
●
●●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●●●
●
●
●●
●●
●●
●
●
●
●
●●●
●
●
●●
●●
●●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●●●
●
●●
●
●
●
●●
●●
●
●
●●
●
●●
●●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●●●
●●
●
●●
●●
●
●●●
●
●●
●●●
●●
●
●●●●●●
●
●●
●
30
40
50
60
70
0.0 0.5 1.0time (s)
Cur
rent
(pA)
* illustrative simulation - not real data

Nanopore Sequencing
9
CTACGATTSample Current
●●●
●
●
●●
●●●
●
●●●
●
●●●
●●●
●●●
●
●
●●
●
●
●
●●
●
●●●●●●●●●
●
●●
●●●
●●●●●●
●
●
●●●
●●
●●●●
●●●
●●
●●
●●●●●●●●
●●
●
●
●
●
●
●●●●
●
●●●●●●●●●●
●
●
●●
●
●●●
●●●
●
●
●●
●
●●●●●●●●
●●●●●●●●●●
●
●●●
●
●●●
●
●●
●●●
●
●●●●
●
●●
●
●
●●●
●
●●
●●●●
●
●●
●
●
●●●
●
●
●●●●●
●●●●●●●
●●●●●●●●●●●●●
●●
●●●●●●●●●●●●●
●
●●●●
●
●●●●●●
●●
●
●
●●●
●
●●
●●●●
●
●●●
●
●
●
●●●●●
●●
●
●●●
●●●●●●●●●●●●●●●●●
●
●●
●●●●●●
●
●●
●●●
●●
●
●●●
●
●
●●●
●
●●●●●
●
●●●●●●
●●
●
●●●●●●●
●
●
●
●●
●●
●
●
●●
●●●●
●●
●●●
●●
●
●●●
●
●●
●
●
●
●
●
●
●●
●●●●●●●●●
●●
●●●●●●●●
●●●●
●●●●●
●●●●●●
●●●●
●
●
●
●
●●
●●
●●●●●
●●●
●
●●●●
●
●
●
●
●●●
●●
●●●
●●●●
●
●
●●●●●●●●●
●
●
●
●
●●●●●●●●●●
●
●
●●
●
●●
●●
●●●●
●
●
●
●●●
●
●●●
●●●●●●
●●●
●
●●●●
●
●●●●●
●
●
●●
●●●
●
●●
●●
●●●●●●●●
●●●●
●●
●●●●
●
●●
●
●
●●●●
●●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●●
●●
●●●●●●●
●
●
●●
●●●●●
●●
●
●
●●
●
●●
●
●●
●
●
●
●●●●●●●
●●
●
●
●
●
●
●
●
●●
●
●●●
●
●●●●
●
●●
●
●
●●
●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●●
●
●●●●●●
●
●
●●
●●
●●●
●
●
●●
●
●
●
●●●
●
●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●●
●●●
●●
●
●●
●
●●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●●●
●
●
●●
●●
●●
●
●
●
●
●●●
●
●
●●
●●
●●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●●●
●
●●
●
●
●
●●
●●
●
●
●●
●
●●
●●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●●●
●●
●
●●
●●
●
●●●
●
●●
●●●
●●
●
●●●●●●
●
●●
●●
●
●●●●●
●
●●●●●●●
●
●
●
●
●●●
●
●●
●
●●●
●●●
●
●●●●●●●
●
●
●
●●●●
●●●●●●
●
●
●
●●●
●
●
●●●
●●●
●●
●●
●●●●
●
●
●●
●
●●
●●
●
●
●
●
●
●●●●●
●●
●●
●●●●●●
●
●●●
●●
●●●
●
●●
●
●●
●
●
●●●●
●●●●●●
●
●
●●
●
●●
●
●●
●
●●●●●
●
●
●●●
●
●
●
●
●●●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●●●●●●
●
●
●●●
●
●●
●
●
●●
●●●●
●●
●●
●●●●●
●●
●
●
●
●
●●
●
●
●●●●
●
●
●●
●●
●●
●●●
●
●
●●●●●●●●
●
●
●●
●
●
●
●●
●
●●●●●●●●
●
●
●●●●●●
●
●
●●●
●
●
●●●
●
●●●
●●●
●●
●
●
●
●
●●
30
40
50
60
70
0.0 0.5 1.0time (s)
Cur
rent
(pA)
* illustrative simulation - not real data

Signal-level Analysis
10
●●●
●
●
●●
●●●
●
●●●
●
●●●
●●●
●●●
●
●
●●
●
●
●
●●
●
●●●●●●●●●
●
●●
●●●
●●●●●●
●
●
●●●
●●
●●●●
●●●
●●
●●
●●●●●●●●
●●
●
●
●
●
●
●●●●
●
●●●●●●●●●●
●
●
●●
●
●●●
●●●
●
●
●●
●
●●●●●●●●
●●●●●●●●●●
●
●●●
●
●●●
●
●●
●●●
●
●●●●
●
●●
●
●
●●●
●
●●
●●●●
●
●●
●
●
●●●
●
●
●●●●●
●●●●●●●
●●●●●●●●●●●●●
●●
●●●●●●●●●●●●●
●
●●●●
●
●●●●●●
●●
●
●
●●●
●
●●
●●●●
●
●●●
●
●
●
●●●●●
●●
●
●●●
●●●●●●●●●●●●●●●●●
●
●●
●●●●●●
●
●●
●●●
●●
●
●●●
●
●
●●●
●
●●●●●
●
●●●●●●
●●
●
●●●●●●●
●
●
●
●●
●●
●
●
●●
●●●●
●●
●●●
●●
●
●●●
●
●●
●
●
●
●
●
●
●●
●●●●●●●●●
●●
●●●●●●●●
●●●●
●●●●●
●●●●●●
●●●●
●
●
●
●
●●
●●
●●●●●
●●●
●
●●●●
●
●
●
●
●●●
●●
●●●
●●●●
●
●
●●●●●●●●●
●
●
●
●
●●●●●●●●●●
●
●
●●
●
●●
●●
●●●●
●
●
●
●●●
●
●●●
●●●●●●
●●●
●
●●●●
●
●●●●●
●
●
●●
●●●
●
●●
●●
●●●●●●●●
●●●●
●●
●●●●
●
●●
●
●
●●●●
●●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●●
●●
●●●●●●●
●
●
●●
●●●●●
●●
●
●
●●
●
●●
●
●●
●
●
●
●●●●●●●
●●
●
●
●
●
●
●
●
●●
●
●●●
●
●●●●
●
●●
●
●
●●
●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●●
●
●●●●●●
●
●
●●
●●
●●●
●
●
●●
●
●
●
●●●
●
●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●●
●●●
●●
●
●●
●
●●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●●●
●
●
●●
●●
●●
●
●
●
●
●●●
●
●
●●
●●
●●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●●●
●
●●
●
●
●
●●
●●
●
●
●●
●
●●
●●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●●●
●●
●
●●
●●
●
●●●
●
●●
●●●
●●
●
●●●●●●
●
●●
●●
●
●●●●●
●
●●●●●●●
●
●
●
●
●●●
●
●●
●
●●●
●●●
●
●●●●●●●
●
●
●
●●●●
●●●●●●
●
●
●
●●●
●
●
●●●
●●●
●●
●●
●●●●
●
●
●●
●
●●
●●
●
●
●
●
●
●●●●●
●●
●●
●●●●●●
●
●●●
●●
●●●
●
●●
●
●●
●
●
●●●●
●●●●●●
●
●
●●
●
●●
●
●●
●
●●●●●
●
●
●●●
●
●
●
●
●●●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●●●●●●
●
●
●●●
●
●●
●
●
●●
●●●●
●●
●●
●●●●●
●●
●
●
●
●
●●
●
●
●●●●
●
●
●●
●●
●●
●●●
●
●
●●●●●●●●
●
●
●●
●
●
●
●●
●
●●●●●●●●
●
●
●●●●●●
●
●
●●●
●
●
●●●
●
●●●
●●●
●●
●
●
●
●
●●
●
30
40
50
60
70
0.0 0.5 1.0time (s)
Cur
rent
(pA)
What DNA sequence generated these samples?

Signal-level Analysis
11
●●●
●
●
●●
●●●
●
●●●
●
●●●
●●●
●●●
●
●
●●
●
●
●
●●
●
●●●●●●●●●
●
●●
●●●
●●●●●●
●
●
●●●
●●
●●●●
●●●
●●
●●
●●●●●●●●
●●
●
●
●
●
●
●●●●
●
●●●●●●●●●●
●
●
●●
●
●●●
●●●
●
●
●●
●
●●●●●●●●
●●●●●●●●●●
●
●●●
●
●●●
●
●●
●●●
●
●●●●
●
●●
●
●
●●●
●
●●
●●●●
●
●●
●
●
●●●
●
●
●●●●●
●●●●●●●
●●●●●●●●●●●●●
●●
●●●●●●●●●●●●●
●
●●●●
●
●●●●●●
●●
●
●
●●●
●
●●
●●●●
●
●●●
●
●
●
●●●●●
●●
●
●●●
●●●●●●●●●●●●●●●●●
●
●●
●●●●●●
●
●●
●●●
●●
●
●●●
●
●
●●●
●
●●●●●
●
●●●●●●
●●
●
●●●●●●●
●
●
●
●●
●●
●
●
●●
●●●●
●●
●●●
●●
●
●●●
●
●●
●
●
●
●
●
●
●●
●●●●●●●●●
●●
●●●●●●●●
●●●●
●●●●●
●●●●●●
●●●●
●
●
●
●
●●
●●
●●●●●
●●●
●
●●●●
●
●
●
●
●●●
●●
●●●
●●●●
●
●
●●●●●●●●●
●
●
●
●
●●●●●●●●●●
●
●
●●
●
●●
●●
●●●●
●
●
●
●●●
●
●●●
●●●●●●
●●●
●
●●●●
●
●●●●●
●
●
●●
●●●
●
●●
●●
●●●●●●●●
●●●●
●●
●●●●
●
●●
●
●
●●●●
●●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●●
●●
●●●●●●●
●
●
●●
●●●●●
●●
●
●
●●
●
●●
●
●●
●
●
●
●●●●●●●
●●
●
●
●
●
●
●
●
●●
●
●●●
●
●●●●
●
●●
●
●
●●
●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●●
●
●●●●●●
●
●
●●
●●
●●●
●
●
●●
●
●
●
●●●
●
●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●●
●●●
●●
●
●●
●
●●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●●●
●
●
●●
●●
●●
●
●
●
●
●●●
●
●
●●
●●
●●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●●●
●
●●
●
●
●
●●
●●
●
●
●●
●
●●
●●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●●●
●●
●
●●
●●
●
●●●
●
●●
●●●
●●
●
●●●●●●
●
●●
●●
●
●●●●●
●
●●●●●●●
●
●
●
●
●●●
●
●●
●
●●●
●●●
●
●●●●●●●
●
●
●
●●●●
●●●●●●
●
●
●
●●●
●
●
●●●
●●●
●●
●●
●●●●
●
●
●●
●
●●
●●
●
●
●
●
●
●●●●●
●●
●●
●●●●●●
●
●●●
●●
●●●
●
●●
●
●●
●
●
●●●●
●●●●●●
●
●
●●
●
●●
●
●●
●
●●●●●
●
●
●●●
●
●
●
●
●●●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●●●●●●
●
●
●●●
●
●●
●
●
●●
●●●●
●●
●●
●●●●●
●●
●
●
●
●
●●
●
●
●●●●
●
●
●●
●●
●●
●●●
●
●
●●●●●●●●
●
●
●●
●
●
●
●●
●
●●●●●●●●
●
●
●●●●●●
●
●
●●●
●
●
●●●
●
●●●
●●●
●●
●
●
●
●
●●
●
30
40
50
60
70
0.0 0.5 1.0time (s)
Cur
rent
(pA)
What DNA sequence generated these samples?
basecalling: predict sequence from the events

Signal-level Analysis
12
●●●
●
●
●●
●●●
●
●●●
●
●●●
●●●
●●●
●
●
●●
●
●
●
●●
●
●●●●●●●●●
●
●●
●●●
●●●●●●
●
●
●●●
●●
●●●●
●●●
●●
●●
●●●●●●●●
●●
●
●
●
●
●
●●●●
●
●●●●●●●●●●
●
●
●●
●
●●●
●●●
●
●
●●
●
●●●●●●●●
●●●●●●●●●●
●
●●●
●
●●●
●
●●
●●●
●
●●●●
●
●●
●
●
●●●
●
●●
●●●●
●
●●
●
●
●●●
●
●
●●●●●
●●●●●●●
●●●●●●●●●●●●●
●●
●●●●●●●●●●●●●
●
●●●●
●
●●●●●●
●●
●
●
●●●
●
●●
●●●●
●
●●●
●
●
●
●●●●●
●●
●
●●●
●●●●●●●●●●●●●●●●●
●
●●
●●●●●●
●
●●
●●●
●●
●
●●●
●
●
●●●
●
●●●●●
●
●●●●●●
●●
●
●●●●●●●
●
●
●
●●
●●
●
●
●●
●●●●
●●
●●●
●●
●
●●●
●
●●
●
●
●
●
●
●
●●
●●●●●●●●●
●●
●●●●●●●●
●●●●
●●●●●
●●●●●●
●●●●
●
●
●
●
●●
●●
●●●●●
●●●
●
●●●●
●
●
●
●
●●●
●●
●●●
●●●●
●
●
●●●●●●●●●
●
●
●
●
●●●●●●●●●●
●
●
●●
●
●●
●●
●●●●
●
●
●
●●●
●
●●●
●●●●●●
●●●
●
●●●●
●
●●●●●
●
●
●●
●●●
●
●●
●●
●●●●●●●●
●●●●
●●
●●●●
●
●●
●
●
●●●●
●●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●●
●●
●●●●●●●
●
●
●●
●●●●●
●●
●
●
●●
●
●●
●
●●
●
●
●
●●●●●●●
●●
●
●
●
●
●
●
●
●●
●
●●●
●
●●●●
●
●●
●
●
●●
●
●
●
●
●
●
●●●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●●●
●
●●●●●●
●
●
●●
●●
●●●
●
●
●●
●
●
●
●●●
●
●
●
●●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●
●
●
●
●
●
●●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●●
●
●●
●●
●●●
●●
●
●●
●
●●●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●●●
●
●
●●●
●
●
●●
●●
●●
●
●
●
●
●●●
●
●
●●
●●
●●
●
●●
●
●●
●●
●
●
●
●
●
●
●
●
●
●●
●
●
●●
●
●
●
●
●●●●
●
●●
●
●
●
●●
●●
●
●
●●
●
●●
●●
●●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●●
●●
●
●
●
●●●
●●
●
●●
●●
●
●●●
●
●●
●●●
●●
●
●●●●●●
●
●●
●●
●
●●●●●
●
●●●●●●●
●
●
●
●
●●●
●
●●
●
●●●
●●●
●
●●●●●●●
●
●
●
●●●●
●●●●●●
●
●
●
●●●
●
●
●●●
●●●
●●
●●
●●●●
●
●
●●
●
●●
●●
●
●
●
●
●
●●●●●
●●
●●
●●●●●●
●
●●●
●●
●●●
●
●●
●
●●
●
●
●●●●
●●●●●●
●
●
●●
●
●●
●
●●
●
●●●●●
●
●
●●●
●
●
●
●
●●●
●
●●
●
●
●●
●
●
●●
●
●
●
●
●●●●●●
●
●
●●●
●
●●
●
●
●●
●●●●
●●
●●
●●●●●
●●
●
●
●
●
●●
●
●
●●●●
●
●
●●
●●
●●
●●●
●
●
●●●●●●●●
●
●
●●
●
●
●
●●
●
●●●●●●●●
●
●
●●●●●●
●
●
●●●
●
●
●●●
●
●●●
●●●
●●
●
●
●
●
●●
●
30
40
50
60
70
0.0 0.5 1.0time (s)
Cur
rent
(pA)
What DNA sequence generated these samples?GCTAC
basecalling: predict sequence from the events
observed signal depends on multiple bases; events are labelled with 6-mers

Signal-level Analysis
13
First generation basecallers used hidden Markov models
Calculate best sequence of 6-mers using gaussian emission distributions
Latest basecallers using recurrent neural networks to capture longer range dependencies
Predict 6-mer label for each event using RNN, assemble 6-mers into basecalled reads
input output
Examples: R7 metrichor, nanocall
Examples: R9 metrichor, nanonet, deepnano

Nanopolish
• Toolkit for working with signal-level data• Originally designed for improving a consensus sequence using the
signals from multiple reads
• Extended to call SNPs for the mobile Ebola sequencing project
• A few new features in development that I’ll talk about later
14
P (D|S) …ACTACGATCGACTTA… …ACTACCATCGACTTA… …ACTACGATC-ACTTA… …ACTACCATC-ACTTA…
-176 -191 -168 -185
D1
D2
Dn
…

Human Sequencing Consortium
15
Group of MinION users put flowcells together to sequence a human genome. Data publicly available on github/AWS.
https://github.com/nanopore-wgs-consortium/NA12878

Flowcell Yield
16
Fresh Cell DNA
Rapid Library Kit
Birmingham East Anglia Nottingham British Columbia Santa Cruz
Credit: John Tyson
Fresh Cell DNA
Yield
2.3Gb

Average Read Length
17Credit: John Tyson
Birmingham East Anglia Nottingham British Columbia Santa Cruz
AverageRead
Length
Fresh Cell DNA
Rapid Library Kit
Fresh Cell DNA
6.6kb
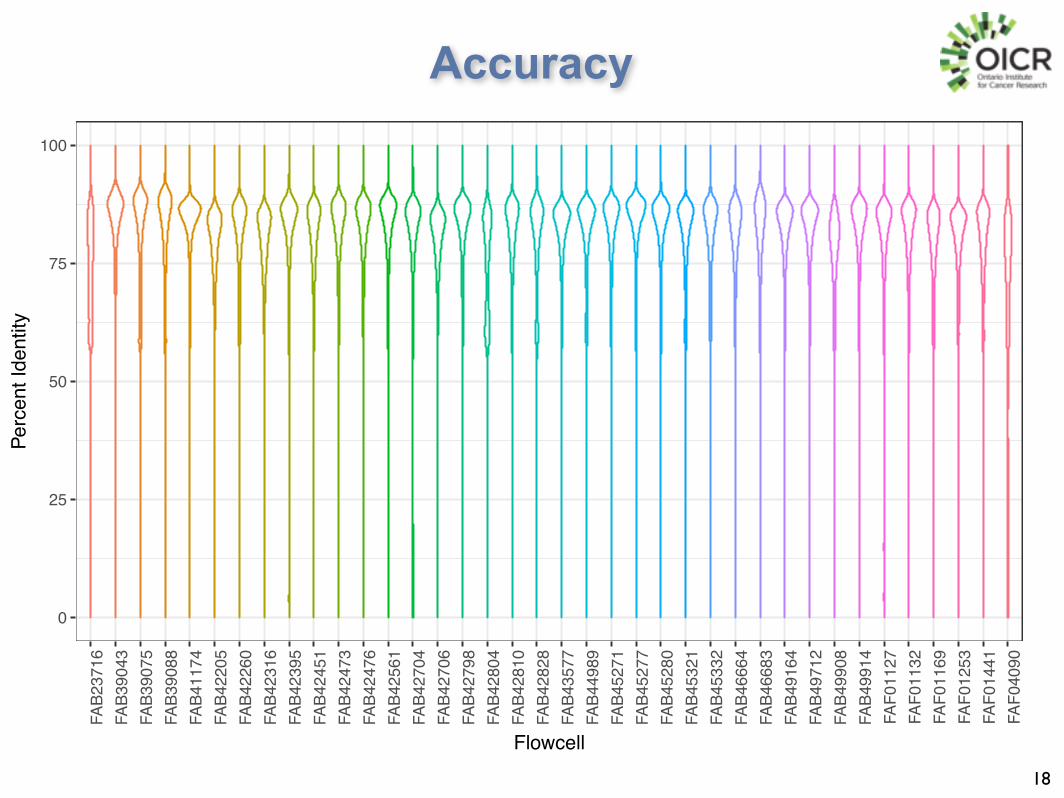
Accuracy
18
0
25
50
75
100
FAB2
3716
FAB3
9043
FAB3
9075
FAB3
9088
FAB4
1174
FAB4
2205
FAB4
2260
FAB4
2316
FAB4
2395
FAB4
2451
FAB4
2473
FAB4
2476
FAB4
2561
FAB4
2704
FAB4
2706
FAB4
2798
FAB4
2804
FAB4
2810
FAB4
2828
FAB4
3577
FAB4
4989
FAB4
5271
FAB4
5277
FAB4
5280
FAB4
5321
FAB4
5332
FAB4
6664
FAB4
6683
FAB4
9164
FAB4
9712
FAB4
9908
FAB4
9914
FAF0
1127
FAF0
1132
FAF0
1169
FAF0
1253
FAF0
1441
FAF0
4090
Flowcell
Perc
ent I
dent
ity
FAB23716
FAB39043
FAB39075
FAB39088
FAB41174
FAB42205
FAB42260
FAB42316
FAB42395
FAB42451
FAB42473
FAB42476
FAB42561
FAB42704
FAB42706
FAB42798
FAB42804
FAB42810
FAB42828
FAB43577
FAB44989
FAB45271
FAB45277
FAB45280
FAB45321
FAB45332
FAB46664
FAB46683
FAB49164
FAB49712
FAB49908
FAB49914
FAF01127
FAF01132
FAF01169
FAF01253
FAF01441
FAF04090

NG50 3.0Mbp
Canu Assembly Contiguity
Credit: Sergey Koren

NG50 45.8Mbp
Canu Assembly + HiC Scaffolding
Topological domains in mammalian genomes identified by analysis of chromatin interactions. Dixon et al. Nature Methods (2012) Scaffolding of long read assemblies using long range contact information. Ghurye et al. Biorxiv (2016) Credit: Sergey Koren

Human Assembly Consensus
21
- This is a work in progress- Polishing a single 6 Mbp chr20 contig- 30X data set is NA12878 consortium data only- 60X data set includes 30X PCR-amplified NA12878 provided by ONT- stats calculated from bwa mem alignments to GRCh38- differences that matched an NA12878 variant were not consider an error
Assembly Percent Identitycanu 94.8%canu+racon 96.5%canu+racon+nanopolish (30X) 99.1%canu+racon+nanopolish (60X) 99.4%canu+racon+nanopolish (60X) + pilon 99.6%

Human Assembly Consensus
22
Remaining errors: some homopolymers, microsatellites, large differences that are difficult to polish.
Assembly Percent Identitycanu 94.8%canu+racon 96.5%canu+racon+nanopolish (30X) 99.1%canu+racon+nanopolish (60X) 99.4%canu+racon+nanopolish (60X) + pilon 99.6%
- This is a work in progress

Data Improvements
• Homopolymers have been the main source of residual errors in ONT assemblies• Earlier basecallers would collapse homopolymers to a 6-mer
• Newest ONT basecaller (“scrappie”) estimates the homopolymer length
23

Scrappie basecalls
24
Sequence
Scrappie
Nanonet
[0 - 28]
[0 - 23]
[0 - 28]
Metrichor Coverage
Nanonet Coverage
Scrappie Coverage
Metrichor
23,389,180 bp 23,389,200 bp 23,389,220 bp 23,389,240 bp 23,389,260 bp 23,389,280 bp 23,389,300 bp
135 bp
chr20
Credit: Sergey Koren

Data Improvements
• “2D” reads use a hairpin adaptor to read both strands of DNA• 2D reads have higher accuracy but with high variance due to effect of base
pairing after the pore
• New method of reading both strands: 1D2
25Figure provided by ONT

1D2 Accuracy
26
- All runs are E. coli- R7.3-2D from Nick Loman- R9.2-2D from OICR- R9.4-1D2 provided by ONT
0.0
0.1
0.2
75 80 85 90 95 100accuracy
density version
R7.3−2DR9.2−2DR9.4−1D^2

Next step: Human Assembly v2
• Improvements to basecalling and read accuracy will help our assembly
• Using scrappie reads from chromosome 20 improves canu assembly from ~95% to 97.5%• Planning to polish this assembly
27

Detecting Base Modifications
28
Schreiber, et al. PNAS. (2013)Laszlo, et al. PNAS (2013)
Slide courtesy of Winston Timp

Training Methylation Models
29
Learn emissions for k-mers over expanded alphabet using synthetically methylated DNA (w/ M.SssI)

NA12878 Methylation
30

Haplotype-Phased Methylation
31
nanopolish has experimental support for phasing methylation patterns

Haplotype-Phased Methylation
32
nanopolish has experimental support for phasing methylation patterns
this haplotype is highly methylated

Haplotype-Phased Methylation
33
nanopolish has experimental support for phasing methylation patterns
this haplotype isn’t

Haplotype-Phased Methylation
34
Het A>G SNP creates a CpG site, called as methylated

Summary
• Improvements to ONT throughput and accuracy have allowed sequencing of large genomes
• Initial human assembly is highly contiguous• Further improvements to accuracy are needed, new “scrappie” basecaller is
promising
• 5-mC can be detected directly from signal-level data, concordant with bisulfite sequencing
35

Acknowledgements
OICR: Matei David, Phil Zuzarte, Jonathan Dursi, Lars Jorgensen
Birmingham: Nick Loman, Josh Quick
Johns Hopkins University: Winston Timp, Rachael Workman
NHGRI: Sergey Koren, Adam Phillippy
NA12878 Sequencing: Matt Loose, John Tyson, Miten Jain, Mark Akeson, Justin O’Grady and many others contributing analysis
Oxford Nanopore Technologies: Chris Wright, Clive Brown, Tim Massingham