1 presenter: chien-chih chen proceedings of the 2002 workshop on memory system performance
Post on 22-Dec-2015
214 views
TRANSCRIPT

1
Presenter: Chien-Chih Chen
National Sun Yat-sen University Embedded System Laboratory
A Proposal for a New Hardware Cache Monitoring
Architecture
Proceedings of the 2002 workshop on Memory system performance

The analysis of the memory access behavior of applications, an essential step for a successful cache optimization, is a complex task. It needs to be supported with appropriate tools and monitoring facilities. Currently, however, users can only rely on either simulation based approaches, which deliver a large degree of detail but are restricted in their applicability, or on hardware counters embedded into processors, which allow to keep track of very few, mostly global events and hence only provide limited data.
Abstract
2

In this work a proposal for novel hardware monitoring facility is presented which exhibits both the details of traditional simulations and the low-overhead of hardware counters. Like the latter approach, it is also targeted towards an implementation within the processor for a direct and non-
intrusive access to caches and memory busses. Unlike traditional counters, however, it delivers a detailed picture of the complete memory access behavior of applications. This is achieved by generating so-called memory access histograms, which show access frequencies in relation to the applications address space. Such spatial memory access information can then be used for efficient program optimization by focusing on the code and data segments which were found to exhibit a poor cache behavior.
Abstract (cont.)
3

Existing analysis of the memory access behavior of application approaches can roughly divided into two classes which include simulation and hardware counters.
Tracing large application can significantly slow down simulation due to the huge amount of memory operation.
The counter approaches are restricted very few individual counters in each processor.
What’s Problem
4
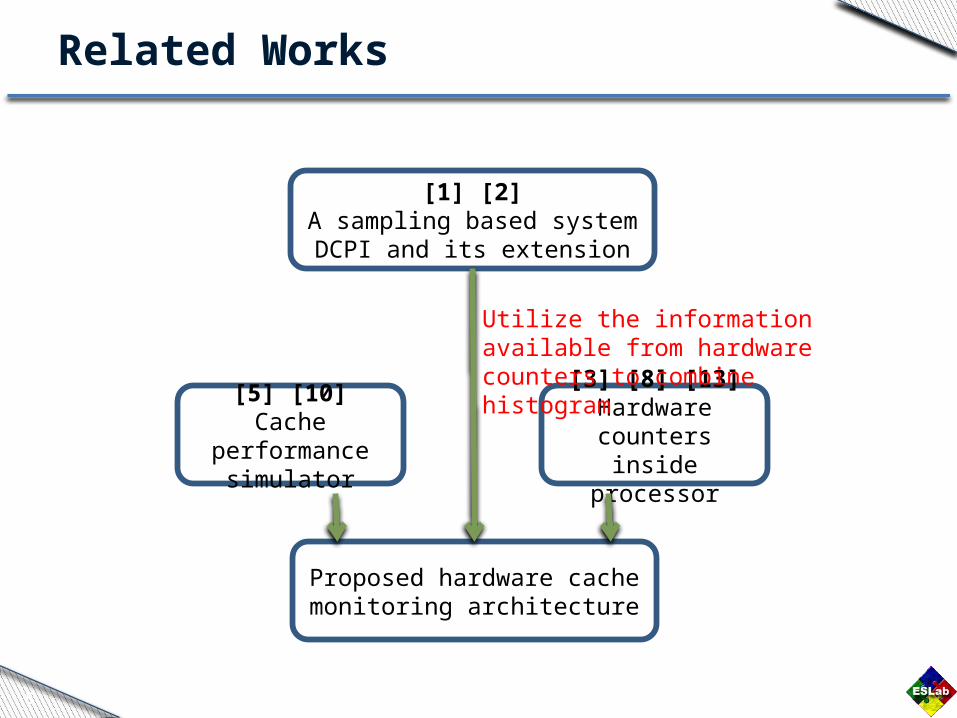
Related Works
5
[5] [10]Cache performance
simulator
[3] [8] [13]Hardware counters
inside processor
[1] [2]A sampling based system DCPI
and its extension
Utilize the information available from hardware counters to combine histogram
Proposed hardware cache monitoring architecture

Cache Monitoring Architecture
6
Cache-like Counter Organization
User-definable Granularity
Multilevel Monitoring
Adding Temporal Information
Integration Aspects
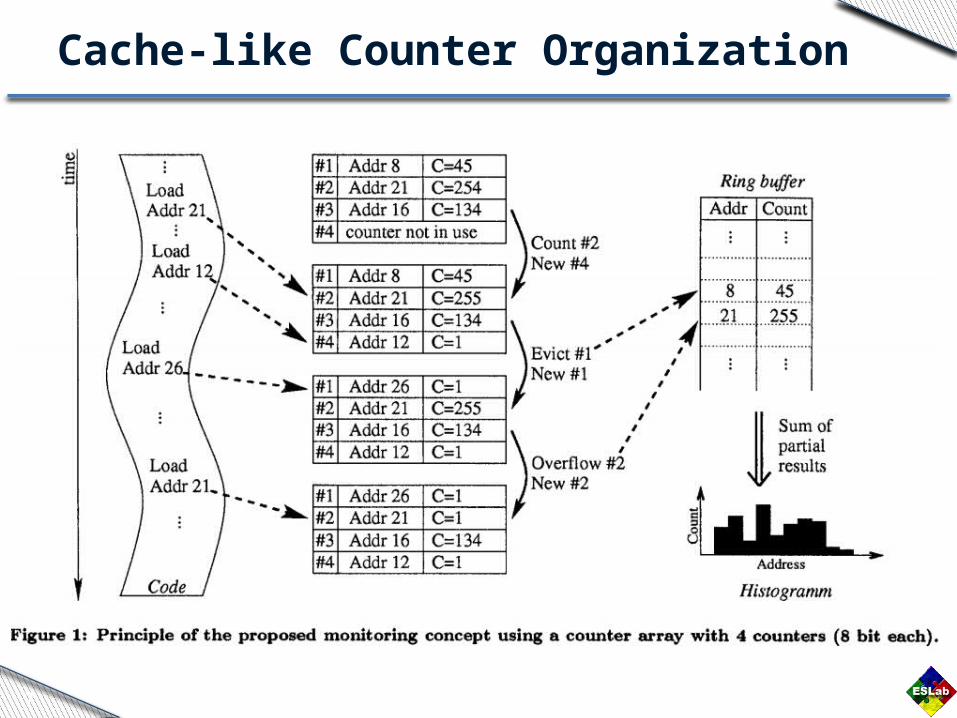
Cache-like Counter Organization
7

User-definable Granularity
8
Filter each event using an address range of interest
Mask all monitored events allowing to delete unimportant lower bits from any address
Aggregation of neighboring events during the monitoring process
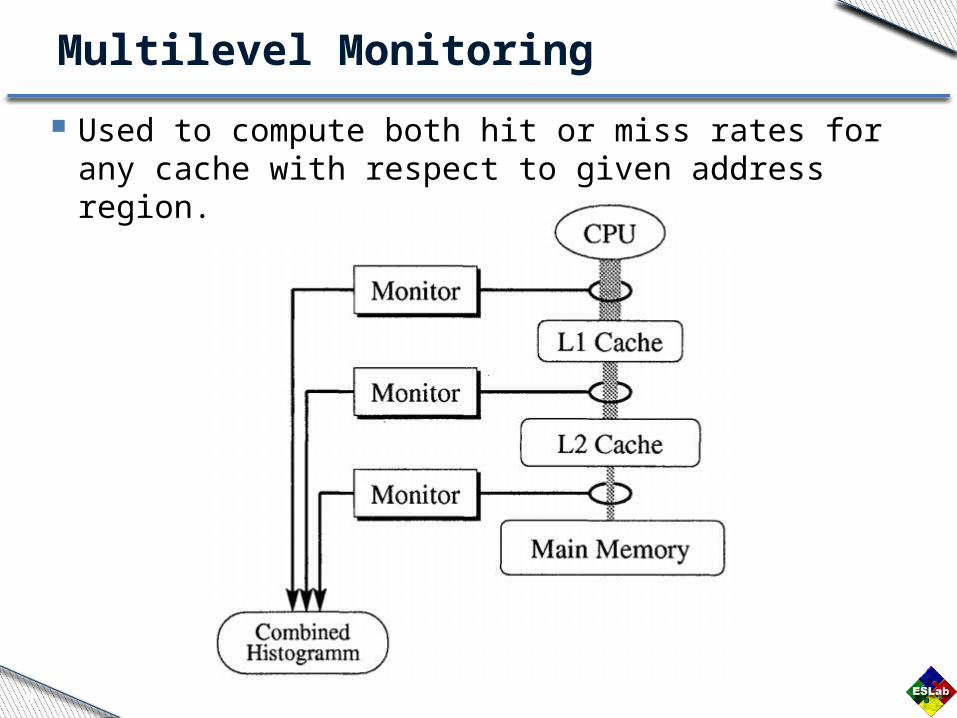
Multilevel Monitoring
9
Used to compute both hit or miss rates for any cache with respect to given address region.

Adding Temporal Information
10
The main drawback of this approach does not provide any temporal information of memory access behavior, however, only contain the aggregated memory behavior of the whole monitoring period.
Monitor barriers which trigger a complete swap out of all partial results.

Integration Aspects
11
How to swap out counter value into the ring buffer without influencing the own measurements.
Masking these access through appropriate filter mechanisms or by establishing separate store pipelines.
The monitor will observe physical address, which need to be transferred into virtual address space for an evaluation at application by using correct page table.

Experimental Setup using SIMT
12
A general tool designed for evaluation of NUMA shared memory machines and includes simulation of complete memory hierarchy.
Non-Uniform Memory Access (NUMA) is a computer memory design used in multiprocessors, where the memory access time depends on the memory location relative to a processor.
Single CPU with two-level memory hierarchy with 8 KB direct mapped L1 and 256 KB L2 two-way associative cache, each with 32 bytes cache lines.
LU decomposition, RADIX sort and WATER.

Histograms of RADIX
13
Show cache and memory access behaviors.
Show cache miss rates by multilevel memory hierarchy.

Histograms of various LU phases
14
Show partial memory access behaviors.
Phase 3, 5 show high locality on very few memory blocks.
Phase 4, 5 show large range of blocks access.

Hardware Complexity & Runtime Overhead
15
All histograms shown without any filtering and at highest possible accuracy by assuming cache line granularity.
Lead to runtime overhead due to the on-line delivery of memory access histograms.
The reduction in granularity and increased number of counters are two options in order to compensate overhead and keep minimum influence of monitor.
The reduction in granularity will lead to reduction in accuracy.
Increased number of counters will increase hardware complexity.
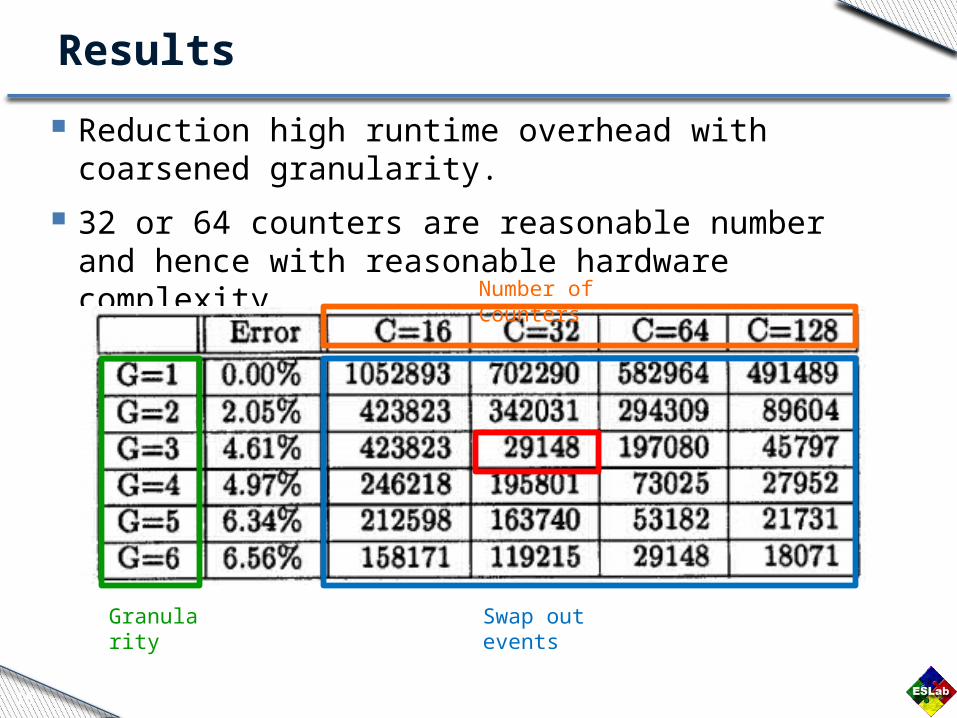
Results
16
Reduction high runtime overhead with coarsened granularity.
32 or 64 counters are reasonable number and hence with reasonable hardware complexity.
Granularity
Number of Counters
Swap out events

Conclusions
17
Novel architecture without major overhead of hardware complexity.
experimental shown that the precision of these access histograms is close to a full simulation.
This monitoring system is capable of observing any kind of event that can be related to an address.

Comments
18
Multilevel memory monitoring architecture.
partial and temporal cache behavior aggregation technique.
Counter array and ring buffer technique.