1 distributed dbmss - concepts and design transparencies
TRANSCRIPT

1
Distributed DBMSs - Concepts and Design
Transparencies

2
Concepts
Distributed DatabaseA logically interrelated collection of shared data (and a description of this data), physically distributed over a computer network.
Distributed DBMSSoftware system that permits the management of the distributed database and makes the distribution transparent to users.

3
Date’s Rules for a DDBMS
Fundamental Principle:To the user, a distributed system should look exactly like a non-distributed system.
1. Local Autonomy2. No Reliance on a Central Site3. Location Independence4. Fragmentation Independence5. Replication Independence6. Distributed Query Processing7. Distributed Transaction Processing

4
Concepts
Collection of logically-related shared data. Data split into fragments. Fragments may be replicated. Fragments/replicas allocated to sites. Sites linked by a communications network. Each DBMS participates in at least one global
application.
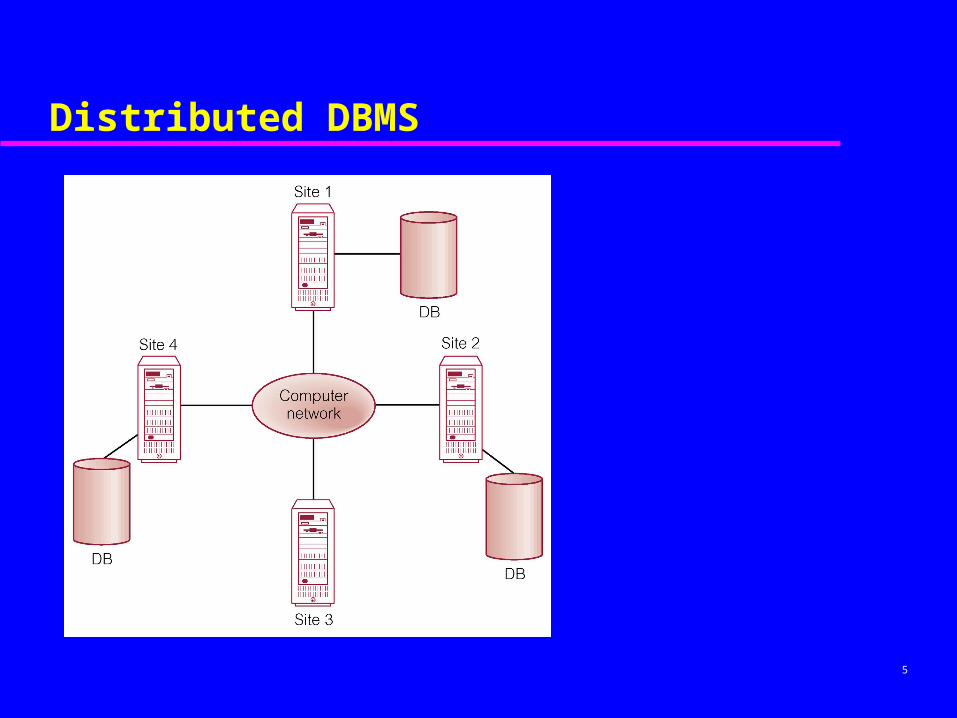
5
Distributed DBMS

6
Advantages of DDBMSs
Reflects organizational structure Improved shareability and local autonomy Improved availability Improved reliability Improved performance Economics

7
Disadvantages of DDBMSs
Complexity Cost Security Integrity control more difficult Database design more complex

8
Types of DDBMS
Homogeneous DDBMS Heterogeneous DDBMS
– Sites may run different DBMS products, with possibly different underlying data models.
– Occurs when sites have implemented their own databases and integration is considered later.

9
Functions of a DDBMS
DDBMS to have at least the functionality of a DBMS.
Also to have following functionality:– Distributed query processing.– Extended concurrency control.– Extended recovery services.

10
Distributed Database Design
Three key issues:Fragmentation
Relation may be divided into a number of sub-relations, which are then distributed.
Allocation
Each fragment is stored at site with "optimal" distribution (see principles of distribution design).
Replication
Copy of fragment may be maintained at several sites.

11
Fragmentation
Definition and allocation of fragments carried out strategically to achieve:– Locality of Reference– Improved Reliability and Availability– Improved Performance– Balanced Storage Capacities and Costs– Minimal Communication Costs.
Involves analyzing most important applications, based on quantitative/qualitative information.

12
Fragmentation
Quantitative information (replication) used for may include:– frequency with which an application is run;– site from which an application is run;– performance criteria for transactions and
applications.
Qualitative information (fragmentation) may include transactions that are executed by application: relations, attributes and tuples.

13
Data Allocation
Centralized: Consists of single database and DBMS stored at one site with users distributed across the network.
Partitioned: Database partitioned into fragments, each fragment assigned to one site.
Complete Replication: Consists of maintaining complete copy of database at each site.
Selective Replication: Combination of partitioning, replication, and centralization.
© Pearson Education Limited 1995, 2005
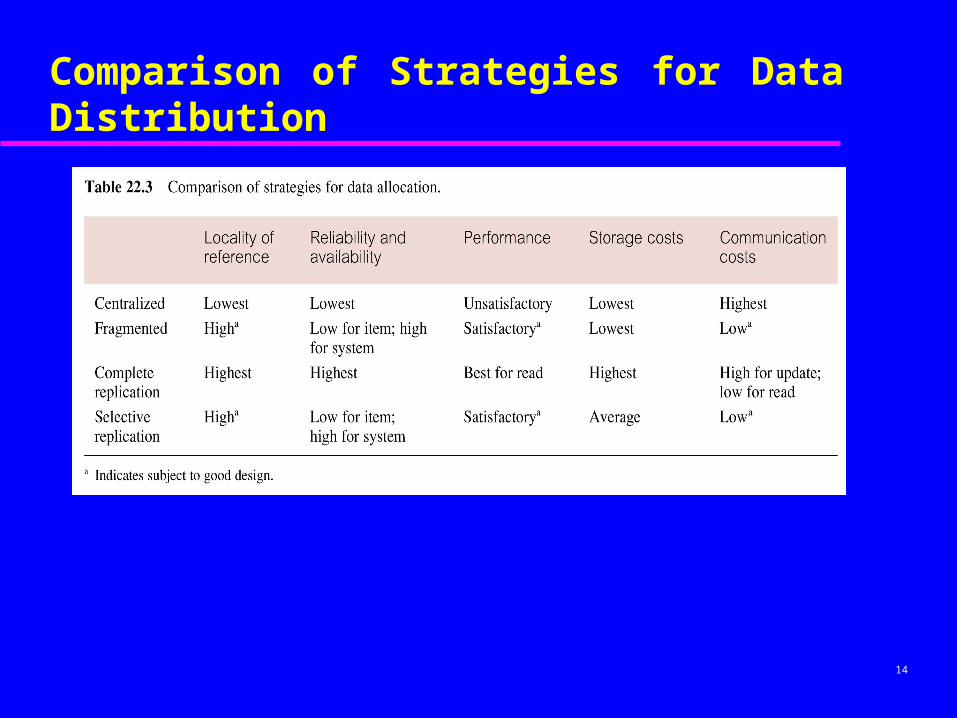
14
Comparison of Strategies for Data Distribution
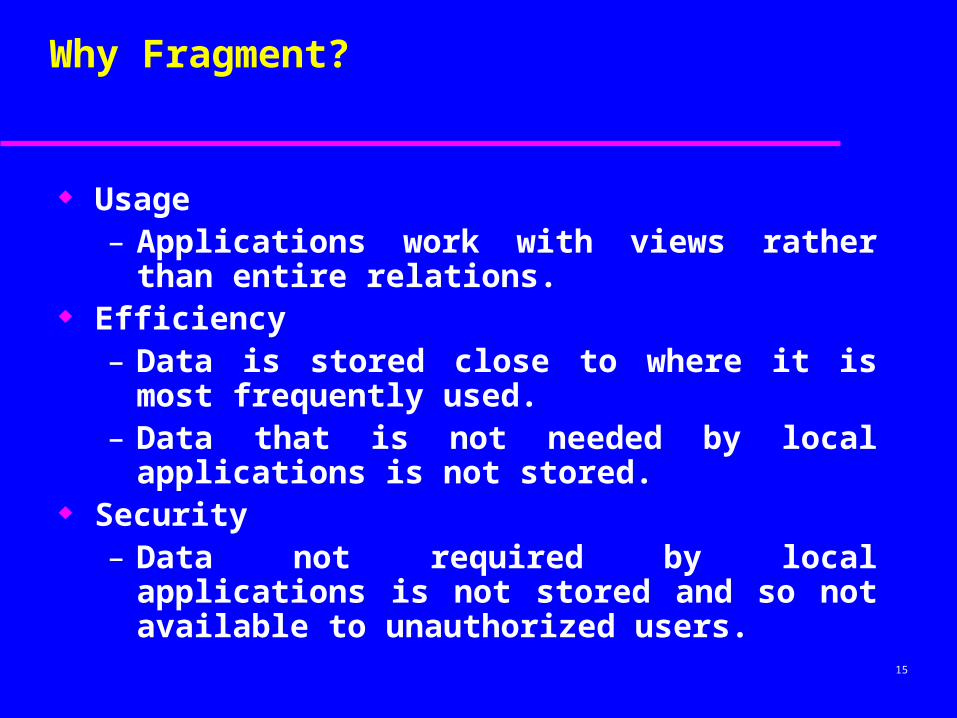
15
Why Fragment?
Usage– Applications work with views rather than entire
relations. Efficiency
– Data is stored close to where it is most frequently used.
– Data that is not needed by local applications is not stored.
Security– Data not required by local applications is not stored
and so not available to unauthorized users.

16
Correctness of Fragmentation
Three correctness rules:
CompletenessIf relation R is decomposed into fragments R1, R2, ... Rn, each data item that can be found in R must appear in at least one fragment.
Reconstruction Must be possible to define a relational operation that will reconstruct R
from the fragments. Reconstruction for horizontal fragmentation is Union operation and
Join for vertical .Disjointness If data item di appears in fragment Ri, then it should not appear in any
other fragment.; Exception: vertical fragmentation, where primary key attributes must be repeated to allow reconstruction.
For horizontal fragmentation, data item is a tuple For vertical fragmentation, data item is an attribute.

17
Types of Fragmentation
Four types of fragmentation:
– Horizontal
– Vertical
– Mixed

18
Horizontal and Vertical Fragmentation

19
Horizontal Fragmentation
Consists of a subset of the tuples of a relation. Defined using Selection operation of relational algebra:
p(R)
For example:
P1 = type='House'(PropertyForRent)
P2 = type='Flat' (PropertyForRent)
Result (PNo., St, City, postcode,type,room,rent,ownerno.,staffno., branchno.)
This strategy is determined by looking at predicates used by transactions.
Reconstruction involves using a union eg R = r1 U r2

20
Vertical Fragmentation
Consists of a subset of attributes of a relation. Defined using Projection operation of relational algebra:
a1, ... ,an(R)
For example:
S1 = staffNo, position, sex, DOB, salary(Staff)
S2 = staffNo, fName, lName, branchNo(Staff)
Determined by establishing affinity of one attribute to another.
For vertical fragements reconstruction involves the join operation; Each fragment is disjointed except for the primary key
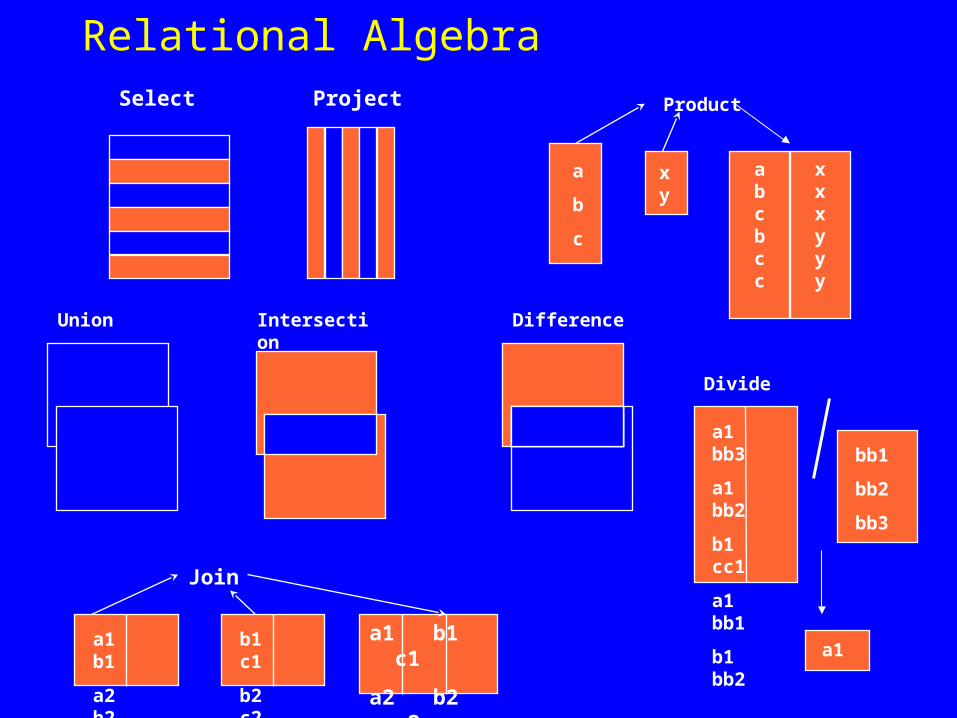
Relational Algebra
a
b
c
Select Project
abcbcc
x y
xxxyyy
Product
Union Intersection
a1 b1
a2 b2
b1 c1
b2 c2
a1 b1 c1
a2 b2 c2
Join
Difference
bb1
bb2
bb3
a1 bb3
a1 bb2
b1 cc1
a1 bb1
b1 bb2
Divide
a1
22
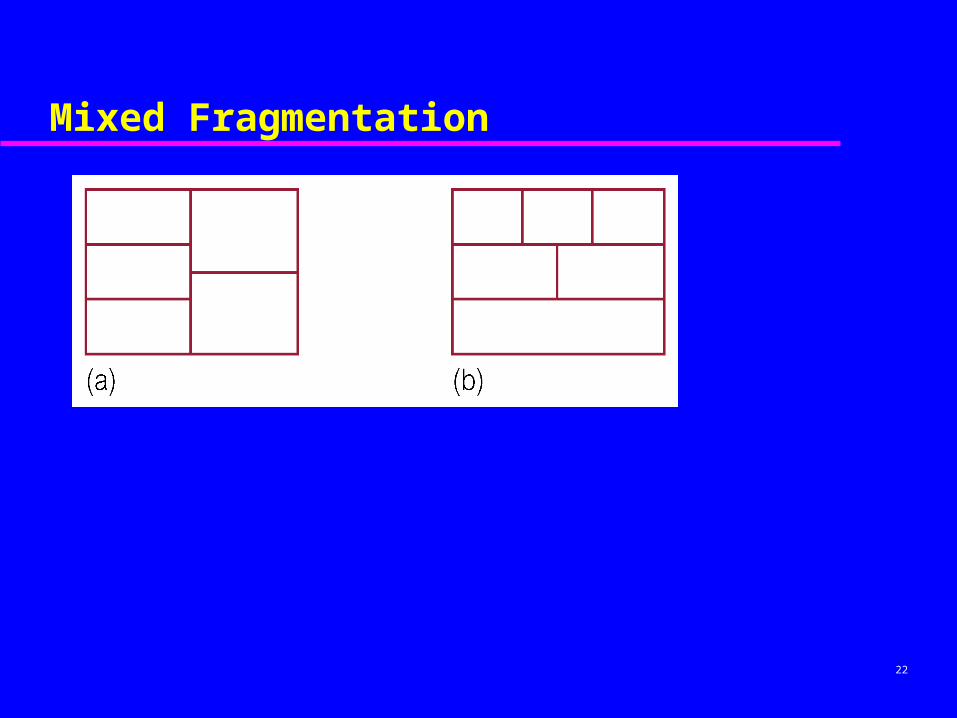
Mixed Fragmentation

23
Mixed Fragmentation
Consists of a horizontal fragment that is vertically fragmented, or a vertical fragment that is horizontally fragmented.
Defined using Selection and Projection operations of relational algebra:
p(a1, ... ,an(R)) or
a1, ... ,an(σp(R))

24
Example - Mixed Fragmentation
S1 = staffNo, position, sex, DOB, salary(Staff)
S2 = staffNo, fName, lName, branchNo(Staff)
S21 = branchNo='B003'(S2)
S22 = branchNo='B005'(S2)
S23 = branchNo='B007'(S2)
Explain and Illustrate the result of the above example

25
Transparencies in a DDBMS
Distribution Transparency
– Fragmentation Transparency– Location Transparency– Replication Transparency
Transaction Transparency
– Concurrency Transparency– Failure Transparency
Performance Transparency
– DBMS Transparency

26
Distribution Transparency
Distribution transparency allows user to perceive database as single, logical entity.
If DDBMS exhibits distribution transparency, user does not need to know:– data is fragmented (fragmentation transparency),
– location of data items (location transparency),
– otherwise call this local mapping transparency.
With replication transparency, user is unaware of replication of fragments .

27
Transaction Transparency
Ensures that all distributed transactions maintain distributed database’s integrity and consistency.
Distributed transaction accesses data stored at more than one location.
Each transaction is divided into number of subtransactions, one for each site that has to be accessed.
DDBMS must ensure the indivisibility of both the global transaction and each subtransactions.

28
Concurrency Transparency
All transactions must execute independently and be logically consistent with results obtained if transactions executed one at a time, in some arbitrary serial order.
Same fundamental principles as for centralized DBMS.
DDBMS must ensure both global and local transactions do not interfere with each other.
Similarly, DDBMS must ensure consistency of all subtransactions of global transaction.
29
Concurrency Transparency (Replication)
Replication makes concurrency more complex. If a copy of a replicated data item is updated,
update must be propagated to all copies. However, if one site holding copy is not
reachable, then transaction is delayed until site is reachable.

30
Failure Transparency
DDBMS must ensure atomicity and durability of global transaction.
Means ensuring that subtransactions of global transaction either all commit or all abort.
Thus, DDBMS must synchronize global transaction to ensure that all subtransactions have completed successfully before recording a final COMMIT for global transaction.
Must do this in the presence of site and network failures.

31
Performance Transparency
DDBMS must perform as if it were a centralized DBMS. – DDBMS should not suffer any performance
degradation due to distributed architecture.– DDBMS should determine most cost-effective
strategy to execute a request. i.e. query optimisation (the order of selects and projects) applied to a distributed database

32
Performance Transparency
Must consider fragmentation, replication, and allocation schemas.
DQP has to decide e.g. :– which fragment to access;– which copy of a fragment to use;– which location to use.

33
Performance Transparency
DQP produces execution strategy optimized with respect to some cost function.
Typically, costs associated with a distributed request include:
– I/O cost;– Communication cost.
34
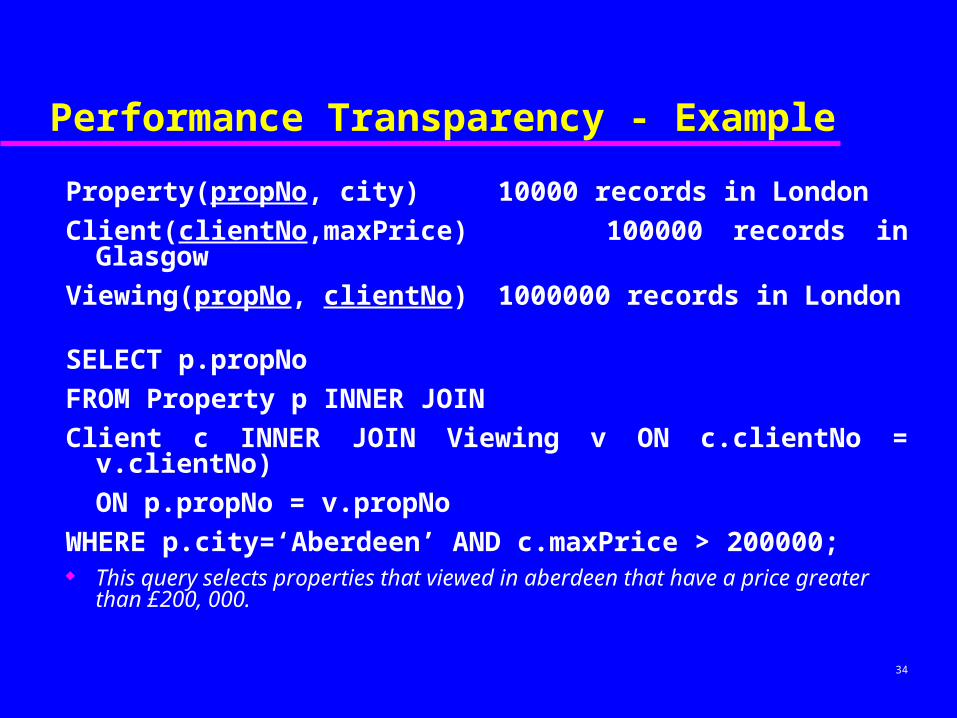
Performance Transparency - Example
Property(propNo, city) 10000 records in London
Client(clientNo,maxPrice) 100000 records in Glasgow
Viewing(propNo, clientNo) 1000000 records in London
SELECT p.propNo
FROM Property p INNER JOIN
Client c INNER JOIN Viewing v ON c.clientNo = v.clientNo)
ON p.propNo = v.propNo
WHERE p.city=‘Aberdeen’ AND c.maxPrice > 200000; This query selects properties that viewed in aberdeen that have a price
greater than £200, 000.

35
Performance Transparency - Example
Assume: Each tuple in each relation is 100 characters long. 10 renters with maximum price greater than £200,000. 100 000 viewings for properties in Aberdeen.
In addition the data transmission rate is 10,000 characters per sec and there is a 1 sec access delay to send a message.

36
Performance Transparency - Example
Derive the following :

37
Distributed system architecture and parallel Data management.
DT211

38
• A distributed system is a collection of computers that communicate by means of some networked media. There are a number of key issues which must be considered when discussing distributed system architectures:
1. The principle of locality. This means that parts of a system which are associated with each other should be in close proximity. For example, programs which exchange large amounts of data should, ideally, be on the same computer or, less ideally, the same local area network.
2. The principle of sharing. This means that ideally resources (memory, file space, processor power) should be carefully shared in order to minimise the load on some of the elements of a distributed system.
3. The parallelism principle. This means that maximum use should be made of the main rationale behind distributed systems: the fact that a heavy degree of scaling up can be achieved by means of the careful deployment of servers sharing processing load.

39
• Principle of locality: This is the principle that entities which comprise a distributed system should be located close together, ideally on the same server or client. These entities can be files, programs, objects or hardware.– (1)Keeping data together:
• Probably the best known example of the locality principle is that data that is related to each other should be grouped together. One example of this where two tables which are related by virtue of the fact that they are often accessed together are moved onto the same server.
– (2)Keeping code together• The idea behind this is that if two programs communicate
with each other in a distributed system then, ideally, they should be located on the same computer or, at worst, they should be located on the same local area network. The worst case is where programs communicate by passing data over the slow communication media used in wide area networks.

40
• (3)Bringing users and data close together. There are two popular ways of implementing this principle. The first is the use
of replicated data and the second is caching. – Replicated data is data that is duplicated at various locations in
a distributed system. The rationale for replicating a file, database, part of a file or part of a database is simple. By replicating data which is stored on a wide area network and placing it on a local area network major improvements in performance can be obtained as local area technology can be orders of magnitude faster than wide area technology in delivering data. However, replicating and synchronisation of the data can be counter productive
• (4)Keeping programs and data together – A good precept to be used when designing a distributed system
is that programs and the data that they operate on should be as close together as possible.

41
• The principle of sharing • This principle is concerned with the sharing of resources - memory,
software and processor.
– (1)Sharing amongst servers : A major decision to be made about the design of a distributed system is how the servers in a system are going to have the work performed by the system partitioned among them. The main rationale for sharing work amongst servers is to avoid bottlenecks where servers are overloaded with work which could be reallocated to other servers.
– (2)Sharing data: A distributed system will have, as a given, the fact that data should be shared between users. The two main decisions are where to situate the tables that make up a relational application and what locking strategy to adopt.

42
• Locking:Most of the decisions about locking will be made with respect to the database management system that is used. In general such systems allow locking at one or more sizes: page locks, table locks, database locks and row lock.
• Although many locking decisions are straightforward, some locking issues are much more subtle. For instance, the relationship between deadlock occurrence, the locking strategy adopted and performance can be a subtle one, where trade-offs have to be considered. For example, locking at the row level will enable more concurrency to take place at the cost of increased deadlocking where resources have to be expended in order to monitor and release deadlocks; conversely locking at the table level can lead to a major reduction in deadlock occurrence, but at the expense of efficient concurrent operations

43
• The parallelism principle• A key idea behind the parallel principle is
that of load balancing:• For example, one decision that the
designer of a distributed system has to make is what to do about very large programs which could theoretically execute on the same processor. Should this program be split up into different threads which execute in parallel, either on a single server or on a number of distributed servers?

44
• Another ideal which designers try and aim for is to partition a database into tables and files in order that the transactions are evenly spread around the file storage devices that are found on a distributed system.
• Finally another area where parallelism can increase the performance of a distributed system is I/O parallelism. Usually design decisions which are made in this category involve the use of special software or hardware, for example the use of RAID devices or parallel database packages.
• In conclusion employing Distributed design principles is always a compromise; a solution which is optimal for a particular system workload will often be not as efficient for another workload.

45
Parallel Data Management• A topic that’s closely linked to Data Warehousing
is that of Parallel Data Management.
• The argument goes:– if your main problem is that your queries run too slowly, use
more than one machine at a time to make them run faster (Parallel Processing).
– Oracle uses this strategy in its warehousing products.
• There are two types of parallel processing - Symmetric Multiprocessing (SMP), and Massively Parallel Processing (MPP)

46
• SMP – All the processors share the same memory and the O.S. runs and schedules tasks on more than one processor without distinction.– in other words, all processors are treated equally
in an effort to get the list of jobs done.– However, SMP can suffer from bottleneck
problems when all the CPUs attempt to access the same memory at once.
• MPP - more varied in its design, but essentially consists of multiple processors, each running their own program on their own memory i.e. memory is not shared between processors.– the problem with MPP is to harness all these
processors to solve a single problem.– But they do not suffer from bottleneck problems

47
• Regardless of the architecture used, there are still alternatives regarding the use of the parallel processing capabilities.
• There are two possible solutions dividing up the data: Static and Dynamic Partitioning.
– In Static Partitioning you break up the data into a number of sections. Each section is placed on a different processor with its own data storage and memory. The query is then run on each of the processors, and the results combined at the end to give the entire picture. This is like joining a queue in a supermarket. You stay with it until you reach the check-out.
– The main problem with Static Partitioning is that you can’t tell how much processing the various sections need. If most of the relevant data is processed by one processor you could end up waiting almost as long as if you didn’t use parallel processing at all.
– In Dynamic Partitioning the data is stored in one place, and the data server takes care of splitting the query into multiple tasks, which are allocated to processors as they become available. This is like the single queue in a bank. As a counter position becomes free the person at the head of the queue takes that position
– With Dynamic Partitioning the performance improvement can be dramatic, but the partitioning is out of the users hands.

48
Sample type question• Fragmentation, replication and allocation
are the three important characteristics discuss their importance in relation to distributed databases.
• Discuss the major principles of distributed systems design and how they can be utilised in geographically distributed database.