1 cardinality estimation for large-scale rfid systems chen qian, hoilun ngan, and yunhao liu hong...
TRANSCRIPT

1
Cardinality Estimation for Large-scale RFID Systems
Chen Qian, Hoilun Ngan, and Yunhao LiuHong Kong University of Science and Technology

2
RFID: Hot Topic
• Both in industry and academic society
• RFID: independent sessions (three or more papers) in PerCom 2007, 2008
• 2009?

3
Research Issues(take our group as an example)
• Localization
• Object Tracking
• Security & Privacy
• Tag Counting & Estimation
To be expanded…

4
RFID: Hot Topic
• Some RFID papers in other top confs.M. S. Kodialam, T. Nandagopal, “Fast and reliable
estimation schemes in RFID systems”, MobiCom 2006J. Myung, W. Lee, “Adaptive splitting protocols for RFID tag collision arbitration”, MobiHoc 2006
Qunfeng Dong, et. al., “Load Balancing in Large-Scale RFID Systems”, Infocom 2007
Z. Zhou, et. al., "Slotted Scheduled Tag Access in Multi-Reader RFID Systems", ICNP 2007

5
RFID Sys. Model
RFID Readers– Carrying
antennas, collect info from nearby tags.
– Connected with servers
RFID Tags– Labeled with
unique serial #s– Simple structure– Large-deployed,
but can not communicate with each other
If multiple tags transmit to reader simultaneously, a collision happens, and reader cannot recognize these tags.

6
Real Problems
• RFID tags are used to label large-volume items.
• Hence, collecting the information of these items is the main goal of the RFID system.
• Two main kinds of information: – Identities Cardinality
Identification Counting

9
Tag counting:Some applications
• Hong Kong International Airport
Cargo transportations

10
Tag counting:Some applications
• Stadium RFID System
Security and traffic control

11
Identification:Limitation
• We can obtain the tag cardinality via identification.
But….
Extremely long latency– 1000 sec for 3000 tags
Not applicable for mobile objects
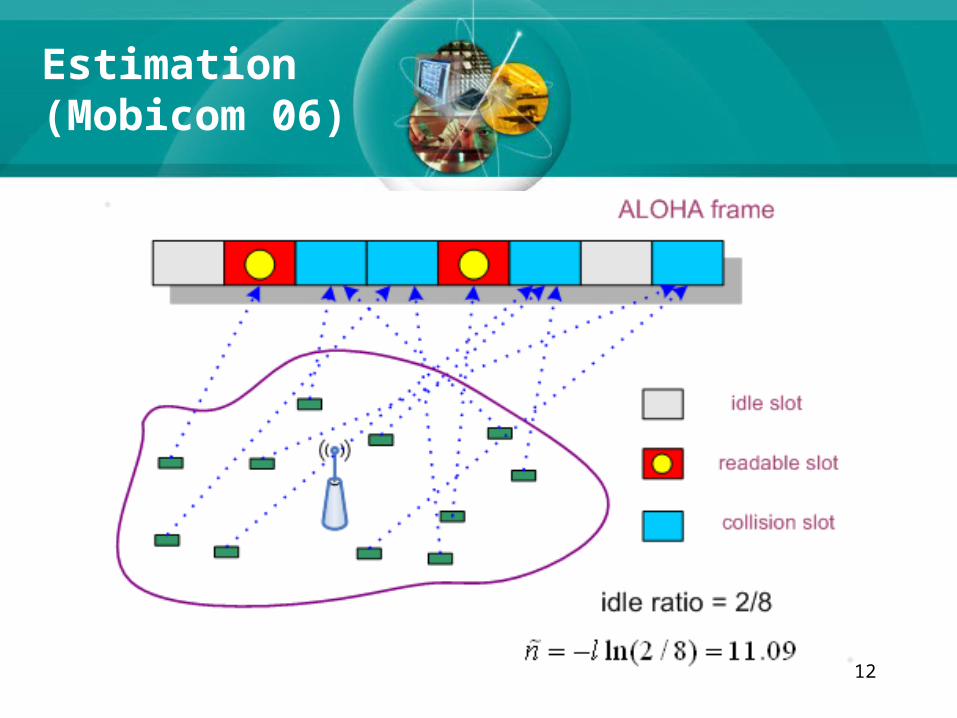
12
Estimation(Mobicom 06)
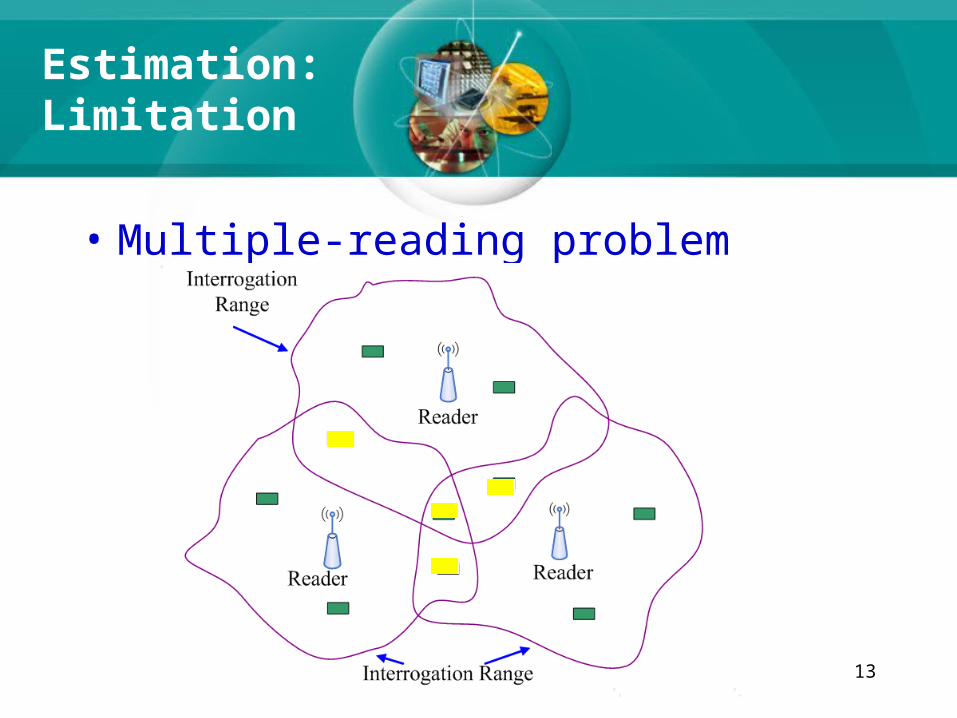
13
Estimation:Limitation
• Multiple-reading problem

14
Our Goal
• Design an estimation scheme that can– Eliminate replications from the sum of
reader results. – Achieve a short processing time,– And high accuracy.

15
LPE
• Linear Probabilistic Estimation (LPE)
Replication-insensitive

16
LPE:Limitation
• Processing time is still too long to be ideal
• One can never know in advance that how long the ALOHA frame should be set.

17
Can we design an estimation schemethat works well without pre-knowledge?
18
Galton Board
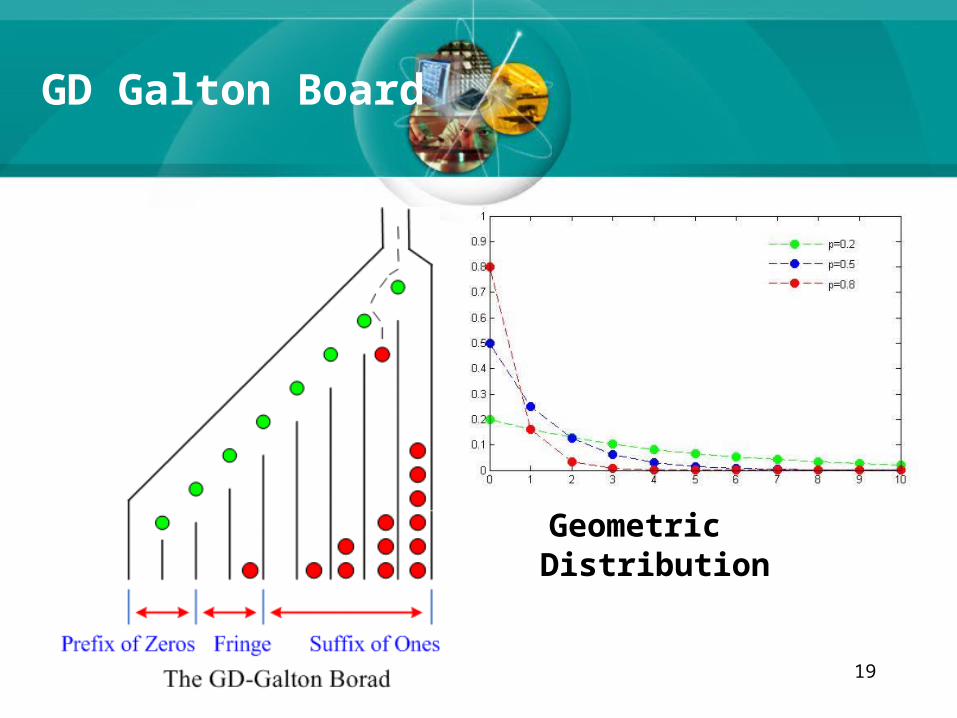
19
GD Galton Board
Geometric Distribution
20
LoF
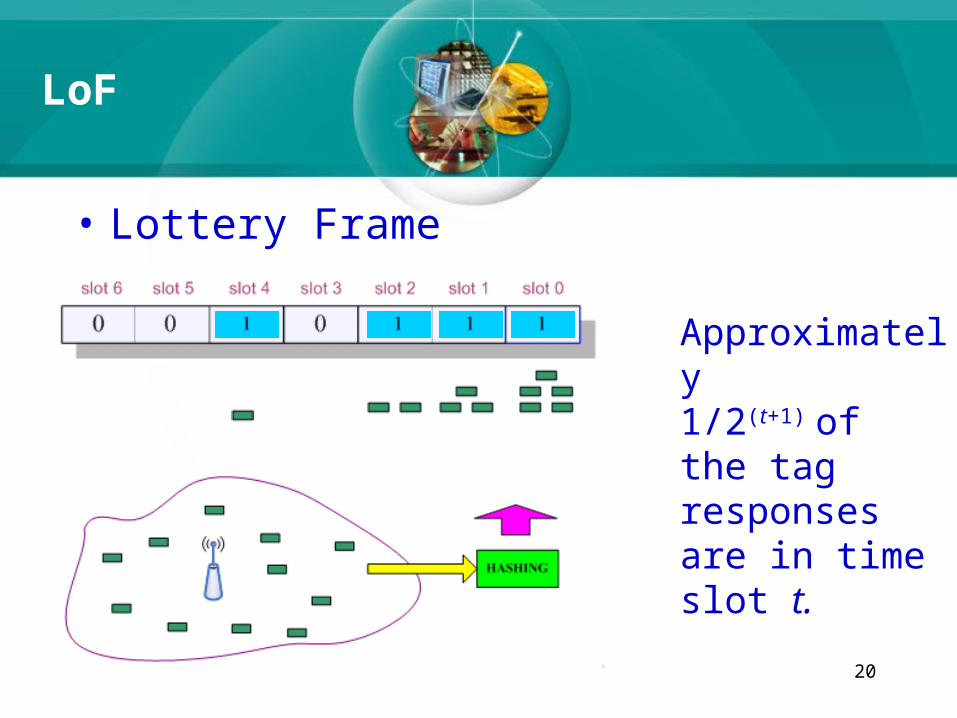
• Lottery Frame
Approximately1/2(t+1) of the tag responses are in time slot t.
21
LoF
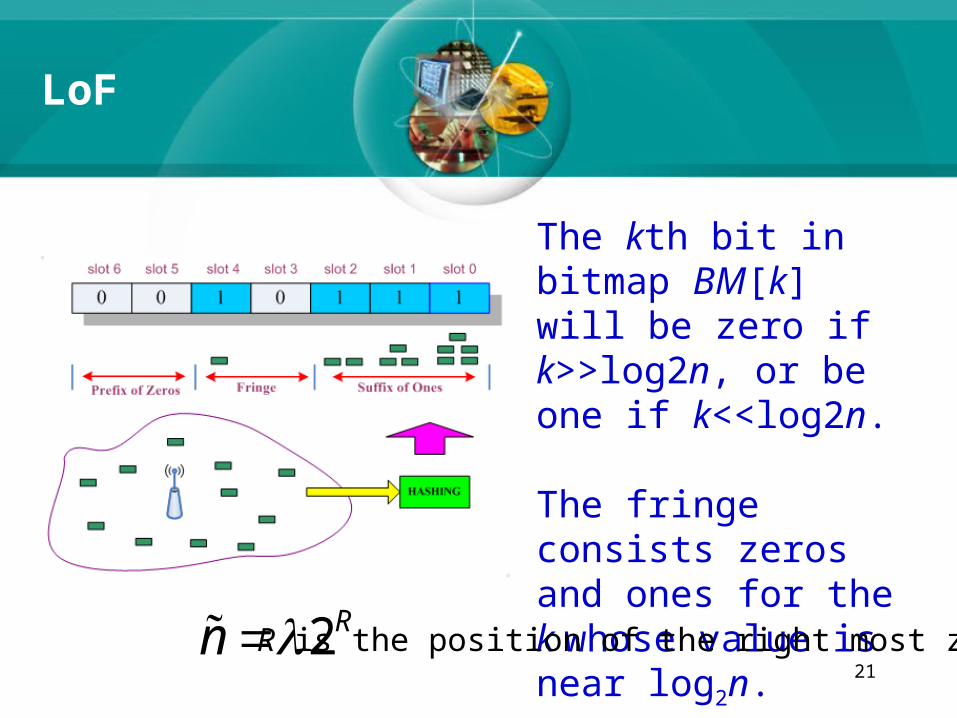
The kth bit in bitmap BM[k] will be zero if k>>log2n, or be one if k<<log2n.
The fringe consists zeros and ones for the k whose value is near log2n.
2Rn R is the position of the right most zero

22
LoF
P. Flajolet and G. N. Martin, "Probabilistic Counting Algorithms for Data Base Applications," Journal of Computer and System Science, vol. 31, 1985.
1.2897
1.2897 2Rn

23
LoF:accuracy
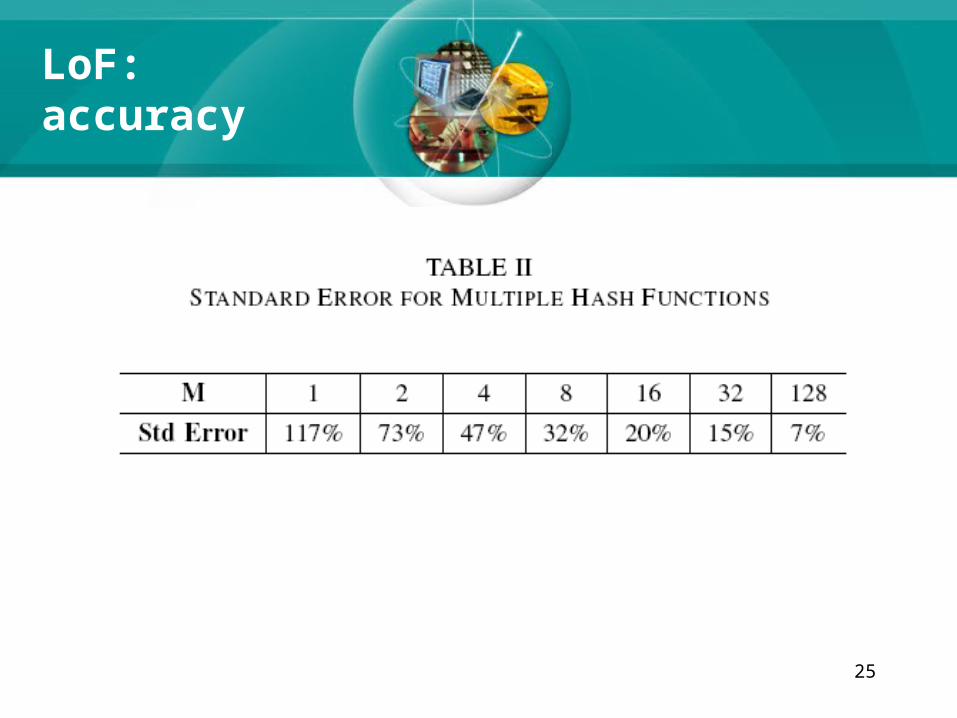
• LoF estimation may not be accurate enough for some applications.
• Luckily the right most zero R is an unbiased estimator of log2n, which meansIf we make several independent estimations
and compute the average result, the standard error will be reduced.

24
LoF:multiple hashes
1 2 ... mR R RR
m
R
Consider the average value
The variable has the expectation and standard deviation that satisfy
( ) /R m
Therefore, the improved estimator is /
1.2897 2 1.2897 2i
i
R mRn
25
LoF:accuracy

26
LoF:processing time
The number of time slots required for a frame is independent from the size of tag set.
A frame with 16 slots is enough toestimate up to 216 = 65536 tags.

27
Simulation:setup
Fixed 32-slot length for LoF estimation.
28
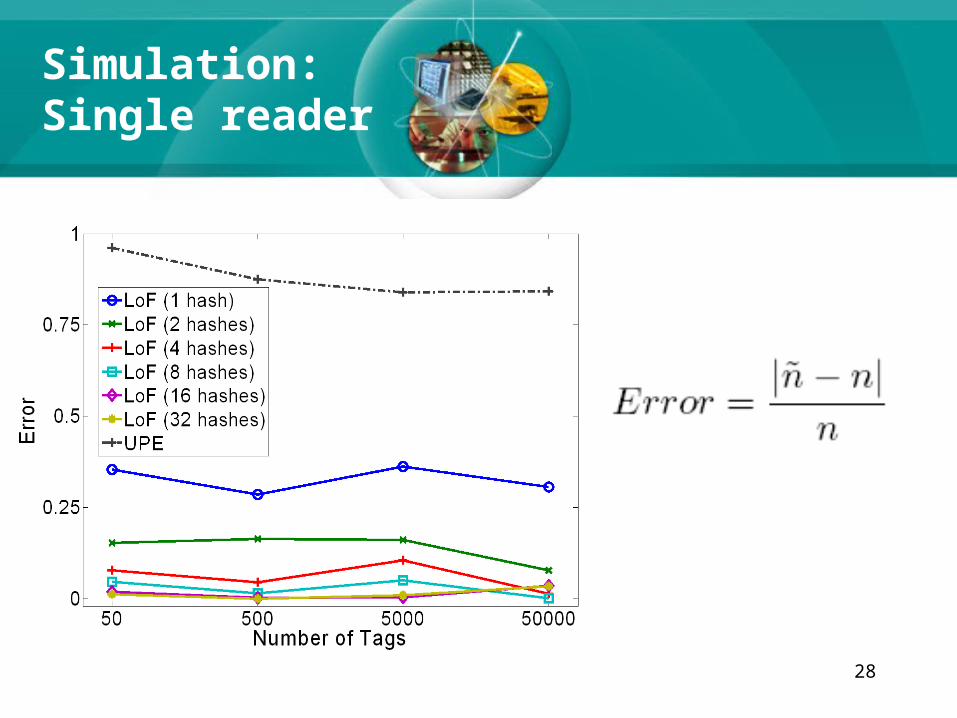
Simulation:Single reader
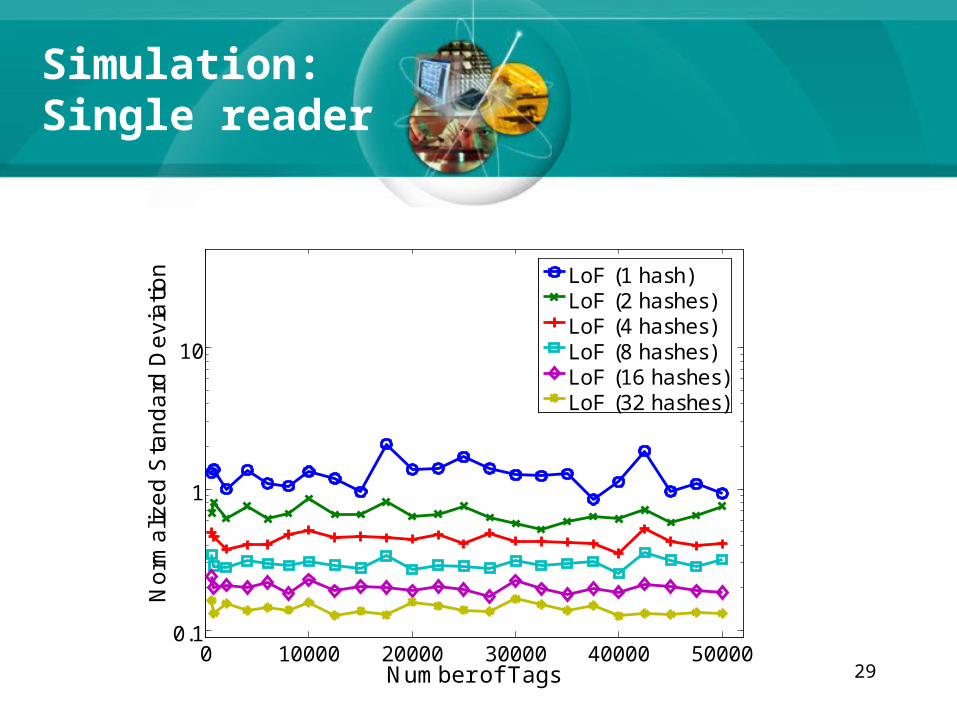
29
Simulation:Single reader
0 10000 20000 30000 40000 500000.1
1
10
Number of Tags
No
rma
lize
d S
tan
da
rd D
evi
atio
n LoF (1 hash)LoF (2 hashes)LoF (4 hashes)LoF (8 hashes)LoF (16 hashes)LoF (32 hashes)
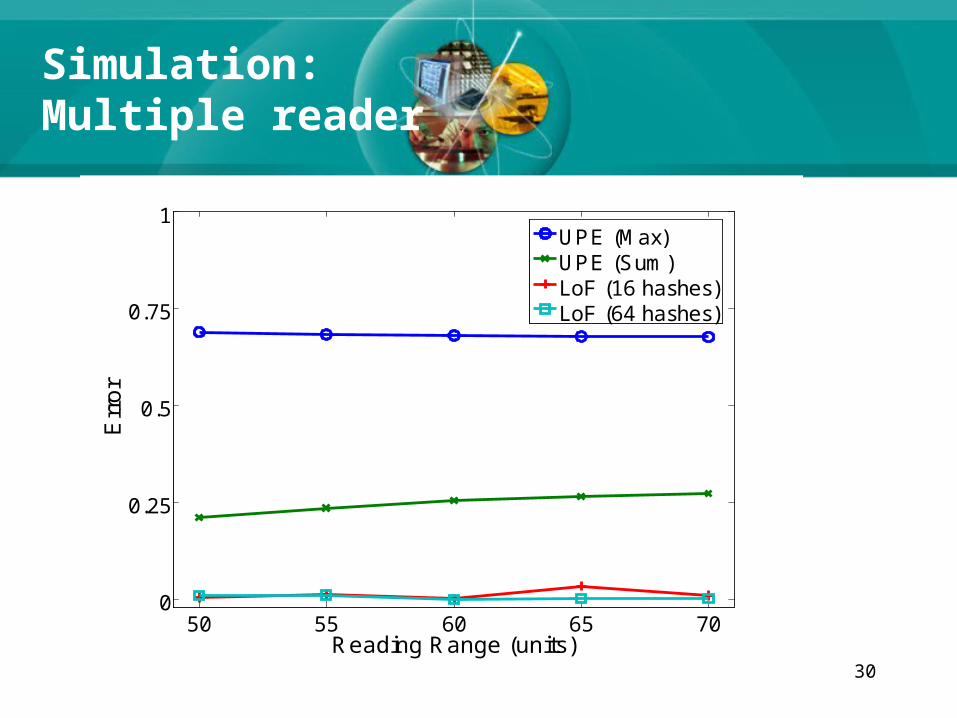
30
Simulation:Multiple reader
50 55 60 65 700
0.25
0.5
0.75
1
Reading Range (units)
Err
or
UPE (Max)UPE (Sum)LoF (16 hashes)LoF (64 hashes)
31
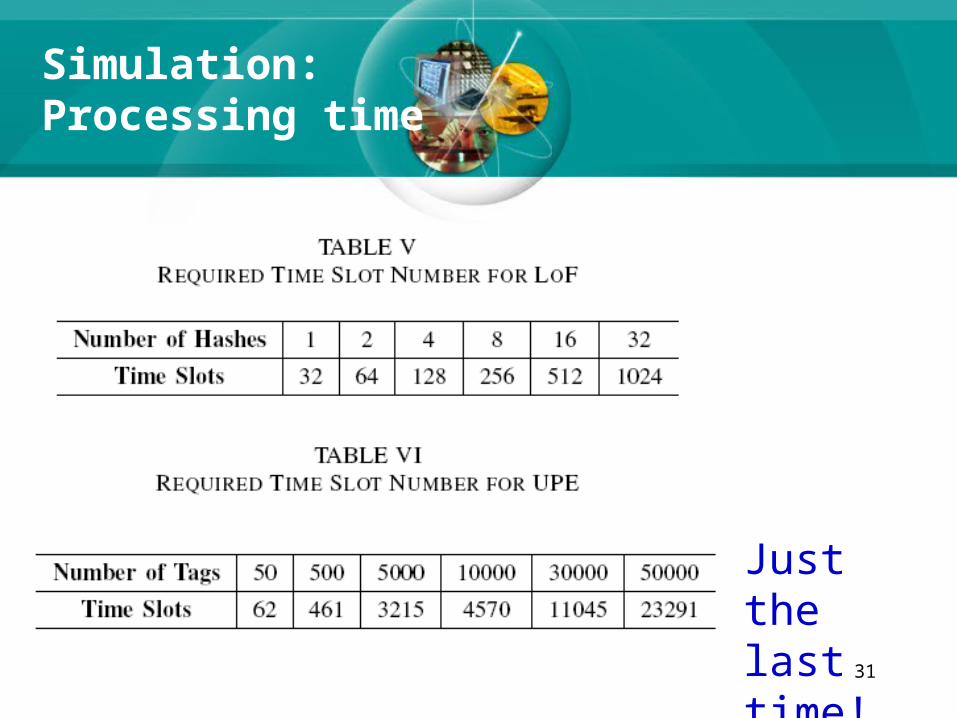
Simulation:Processing time
Just the last time!

32
Summary
• LoF is a replication-insensitive estimation, working well in multi-reader environments.
• LoF can obtain higher accuracy and lower latency, comparing with previous schemes.
• Trade-off in LoF: the storage for hash functions.
33
• Questions?
Thank you !