통계분석가이드라인 - kao.or.kr · 2013-06-22 7 9. ancova (공분산분석) 9-1...
TRANSCRIPT

2013-06-22
1
통계 분석 가이드 라인
전남대학교 치의학전문대학원
임회정1 2
통계(Statisitcs)란 ?Second Language in Science
모집단(Population)과 표본(Sample)
3
모집단(모수) 표본(통계량)
Sampling
추정
4
통계분석 단계
1. 귀무가설 수립
2. 검정통계량 계산
(어떤 검정을 실시할 것인가를 결정)
3. 귀무가설을 기각? 채택?
(p값으로 결정- 유의수준 0.05 기준)
5
관측척도(Scale of measurement) [I]
• 연속변수(Continuous variable)
(예) Height, Weight, Overjet in mm,
Mandibular plane angle,
Shear bond force in megapascals.
6
관측척도(Scale of measurement) [II]
• 범주형변수(Categorical variable)
명목척도(Nominal scale) – 특성만
(예) race, sex, Angle’s classification of malocclusion(Class I, II, III)
결혼상태(기혼, 이혼, 별거, 사별, 미혼)
순서척도(Ordinal scale) – 특성+순서
(예) 교육정도(중졸, 고졸, 대졸)
아픈 정도(Mild/Moderate/Severe)
2013-06-22
2
7
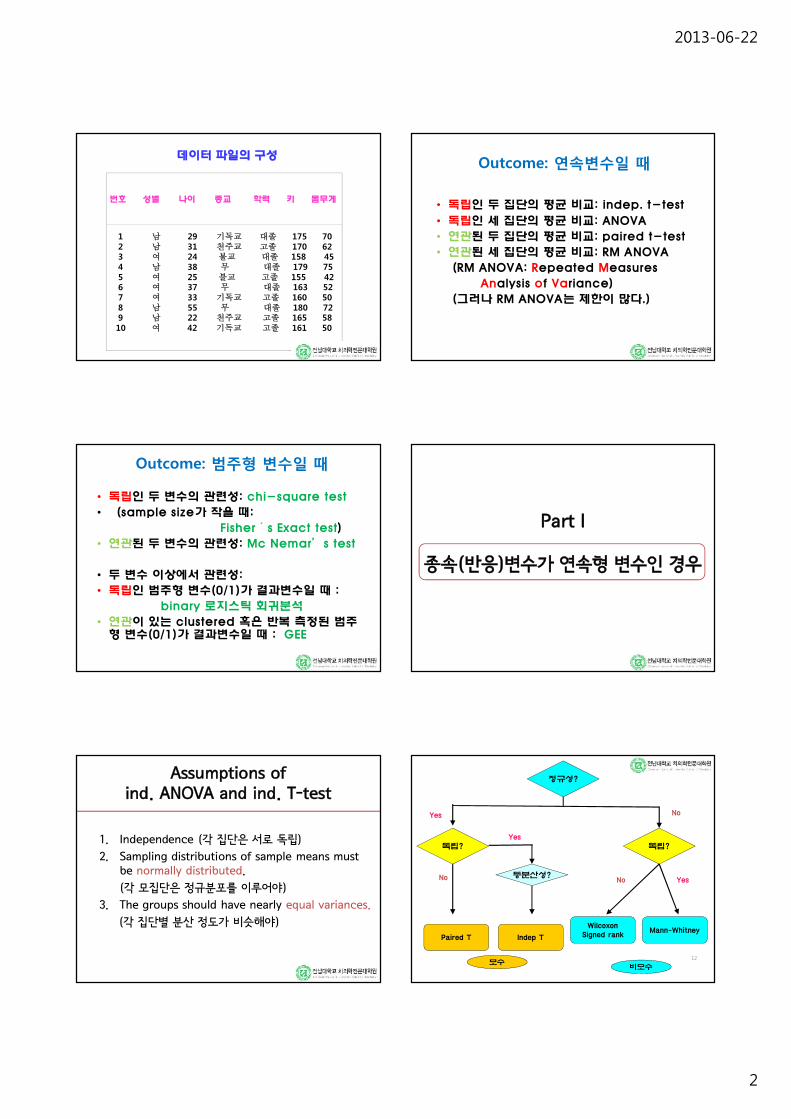
데이터 파일의 구성
번호 성별 나이 종교 학력 키 몸무게
1 남 29 기독교 대졸 175 702 남 31 천주교 고졸 170 623 여 24 불교 대졸 158 454 남 38 무 대졸 179 755 여 25 불교 고졸 155 426 여 37 무 대졸 163 527 여 33 기독교 고졸 160 508 남 55 무 대졸 180 729 남 22 천주교 고졸 165 5810 여 42 기독교 고졸 161 50
8
Outcome: 연속변수일 때
• 독립인 두 집단의 평균 비교: indep. t-test
• 독립인 세 집단의 평균 비교: ANOVA
• 연관된 두 집단의 평균 비교: paired t-test
• 연관된 세 집단의 평균 비교: RM ANOVA
(RM ANOVA: Repeated Measures
Analysis of Variance)
(그러나 RM ANOVA는 제한이 많다.)
9
Outcome: 범주형 변수일 때
• 독립인 두 변수의 관련성: chi-square test
• (sample size가 작을 때:
Fisher´s Exact test)
• 연관된 두 변수의 관련성: Mc Nemar’s test
• 두 변수 이상에서 관련성:
• 독립인 범주형 변수(0/1)가 결과변수일 때 :
binary 로지스틱 회귀분석
• 연관이 있는 clustered 혹은 반복 측정된 범주형 변수(0/1)가 결과변수일 때 : GEE
Part I
종속(반응)변수가 연속형 변수인 경우
Assumptions of ind. ANOVA and ind. T-test
1. Independence (각 집단은 서로 독립)
2. Sampling distributions of sample means must be normally distributed.
(각 모집단은 정규분포를 이루어야)
3. The groups should have nearly equal variances.
(각 집단별 분산 정도가 비슷해야)
11
12
정규성?
독립?
No
Paired T
등분산성?
Indep T
Yes독립?
NoYes
WilcoxonSigned rank
Mann-Whitney
YesNo
모수비모수

2013-06-22
3
종속변수가 연속형인 경우
1. 집단의 수 파악2. 집단의 수는 몇 개인가?
집단이 2개? Treatmt group vs. Control group집단이 3개? A group vs. B group vs. C group집단이 6(3x2)개?
1) 집단이 2개이면 3번으로 가시오.2) 집단이 3개 이상이면 6번으로 가시오.
3. 집단간 독립인가?1) 독립이면 4번으로 가시오.2) 독립이 아니면 5번으로 가시오.
13
코팅A 코팅B
스크류A
스크류B
스크류C
독립인 두 집단의 평균 비교
4. 두 그룹이 독립이면4-1. 각 그룹 별 정규성 검정시행1) 정규성을 만족하면 Independent t-test 시행2) 정규성을 만족하지 않으면 비모수 검정인
Mann-Whitney U test 시행4-2. 등분산 검정에 따른 p-value 선택하여 검정
14
Type
(구강교육)치태지수
A 0.46 1.33 0.74 0.26 0.55 0.26 0.55
B 0.66 0.69 0.90 0.70 1.14 0.51 0.83
15
치태지수
Levene의등분산 검정
평균의 동일성에 대한 t-검정
F 유의확률
t 자유도 유의확률(양쪽)
평균차차이의표준오
차
차이의 95% 신뢰구간
하한 상한
등분산이 가정됨 .294 .591 -1.001 38 .323 -.08039 .08039 -.24321 .08225
등분산이 가정되지않음
-.999 37.210 .324 -.08048 .08056 -.24368 .08273
1. 두 집단이 독립이 아니면,
2. 두 집단의 차이값(x-y)에 대한 정규성 검정 시행
1) 정규성을 만족하면 Paired t-test 시행.2) 정규성을 만족하지 않면 비모수 검정인
Wilcoxon Singed Rank test 시행.
독립이 아닌 두 집단의 평균 비교
16
사용
(전동칫솔)치태지수
전 0.46 1.33 0.74 0.26 0.55 0.26 0.55
후 0.26 0.73 0.43 0.15 0.59 0.18 0.39
17
연구 목적: 이갈이 환자와 정상 집단 모두에서 occlusal splint의 사용이 긴장을 풀고 있는 동안, 이를 악 물고 있는 동안, 씹는 것 같은 운동을 하고있는 동안의 타액흐름속도를 증가시킨다는 가설을 검정하려.
# 논문의 data analysis 표현 방법
(Miyawaki S et al. Salivary flow rates during relaxing, clenching, and chewing-like movement with maxillary occusal splints. AJODO 2004;126:367-70.)
(연구목적)이갈이 환자와 정상 집단 모두에서 occlusalsplint의 사용이 타액 흐름속도를 증가시킨다는가설을 검정하고자 한다.
· 대조군과 이갈이군의 비교를 위하여데이터 분포에 따라 unpaired t-test(independent T)와 Mann-Whitney U test를 시행하였다.
· 동일인에 대하여 스프린트를사용했을 때와 사용하지 않았을 때의타액흐름속도의 평균비교를 위하여데이터 분포에 따라 paired t-test와Wilcoxon signed-rank test를 시행하였다.

2013-06-22
4
19
대조군과 이갈이군의 비교를 위하여 데이터 분포에 따라정규분포를 따르면 (모수/비모수적) 방법으로, 정규분포를따르지 않으면 (모수/비모수적) 방법으로…( ) test와 ( ) test를 시행하였다.
또한 동일인에 대하여 스프린트를 사용했을 때와 스프린트를 사용하지 않았을 때를 구분하여 군을 나누어 타액흐름속도(Salivary flow rate)의 평균 비교를 위하여 데이터 분포에 따라 ( ) test와( ) test를 사용하였다.
(예제)Independent t-test/paired t-test/Mann-Whitney U test/Wilcoxon signed rank test
Ind t Mann-Whitney U
Paired tWilcoxon signed rank
20
결과
대조군과 이갈이군에서 타액흐름속도에서 유의한 차이가없었다는 결과와스프린트를 사용한 군과 사용하지 않은 군 사이에서는 유의한 차이가 있었다는 결과를 표현
21
비모수 방법은 언제 하나?
1. Transformation으로 해결이 안될 때2. 표본수가 너무 적어(6이하) 분포를
알 수 없는 경우3. 집단들의 표본수가 서로 크게 다를 경우4. 변수가 명칭 혹은 순서 척도일 때5. 중앙값의 비교가 목적일 때6. 최소한의 가정. 즉 등분산성, 정규분포 등의
가정을 만족 못할 때
22
모수 : 비모수Independent t-test : Mann-Whitney test
Paired t-test : Wilcoxon signed
rank test
1-way ANOVA : Kruskal-Walis test(# 비모수의 사후검정 : Mann-Whitney test with
Bonferroni correction)
1-way RM ANOVA : Friedman test(#비모수의 사후검정 : Wilcoxon signed rank test with
Bonferroni correction
(more than 4 pairs))
23
등분산성 구형성
. . . . .
. . . . .
. . . . .
. . . . .
. . . . .
. . . . .
. . . . .
. . . . .
분산 1 = 분산 2 = 분산 3diff diff
차이의 분산1= 차이의 분산2
등분산성이란?H0: The variances in different samples are equal.
구형성이란?H0: The variances of the differences between all possible
pairs of groups are equal.
세 집단 이상의 평균 비교
1. 요인의 수를 파악
스크류
A
B
C
D
One-way ANOVA
6-1로 가시오
처리(독립)
스크류 처리 A 처리 B
A
B
C
D
Two-way ANOVA
8번으로 가시오
처리(독립 X)
스크류 사전 사후
A
B
C
D
ANCOVA
9번으로 가시오
반복측정(동일한 개체)
스크류 1주 2주 3주 4주
A
B
C
D
RM ANOVA
7번으로 가시오

2013-06-22
5
6-1. 그룹 간 독립인가?1) 각 그룹이 독립이라면 6-2로 가시오.2) 각 그룹이 독립이 아닐 경우 2번으로 가시오.
(ex) 토끼 한 마리의 다리에 여러 종류의 임플란트 식립
6-2. One-way ANOVA (일원배치 분산분석)
7. 1-way Repeated-Measures(RM) ANOVA (반복측정 분산분석)ex) 시간의 흐름에 대한 반복측정일 경우
시간, dose등: 반복요인그룹: 처리요인 → 요인이 2개이므로 2-Way RM ANOVA
7-1. 차이에 대한 정규성 검정 (x-y, y-z)1) 정규성을 만족하면 7-2로 가시오.2) 정규성을 만족하지 못하면 7-5으로 가시오.
7-2. 구형성 검정1) 구형성을 만족하면 7-3으로 가시오.2) 구형성을 만족하지 않으면 7-4로 가시오.
7-3. P-value를 확인하고 유의하면 사후검정7-4. ε<0.75이면Greenhouse-Geisser, ε>0.75 이면
Huynh-Feldt의 p-value를 확인하고 유의하면 사후검정7-5. Friedman test를 시행하고 p-value가 유의하면
사후분석으로 Wilcoxon Signed Rank test를 하고유의 수준 0.05를 사용하여 사후검정
27
Mauchly’s test indicated that the assumption of sphericity had been violated ( =0.903, p=0.011),
therefore degrees of freedom were corrected using Greenhouse-Geisser estimates of sphericity (ε=0.53).
The results show that the evaluator’s ratings of three profiles differed significantly, F(1.06,5.28)=10.22, p=0.022.
Post hoc tests revealed that extraction group was rated significantly different from either of the other groups.
2
How to write RM ANOVA in your article... Repeated-measures(RM) ANOVA는 아래의 가정이만족할 경우에 사용되어진다.
(1) 각 그룹의 결과 변수간의 차이가 등분산일 때,(2) Balanced data일 때,(3) 같은 ID에 대하여 반복 측정된 time interval이 같을 때.(4) 반복 측정된 관찰치들 간의 correlation이 같을 때
그러나 결과변수가 연속변수이고 반복 측정되어지더라도이러한 가정들을 만족하지 못하는 경우
을 사용한다.
(: Generalization of RM ANOVA)Mixed effect Model
8. Two-way ANOVA (이원배치분산분석) # 논문의 data analysis 표현 방법
(Cacciafesta V.et al. Effects of blood contamination on the shear bond strengths of conventional and hydrophilic primers. Am J Ortjpd Demofacial Orthop 2004;126:207-212)
(연구목적)Conventional primer와 hydrophilic Primer에 대해서 shear bond strength를가지고 blood contamination의 효과를 평가하고자 한다.
· two-way anova를 적용하여사후검정으로 Scheffe 검정을 하였다.
· ARI 점수의 그룹간의 차이를 알아보기위하여chi-square test를 사용하였다.

2013-06-22
6
31
(연구목적)치과의사와 일반인에 의해 평가된한국 사람들의 발치 혹은 비 발치치료 후 측모 심미의 변화를 측정하기 위해 수행 되었다.
· Repeated-Measures ANOVA가main effects(treatment/panel)와interaction effect (treatment*panel)를 검정하는데사용되어졌다.
(Lim HJ et al. Esthetic impact of premolar extaction and nonextraction treatments on Korea borderline patients. Am J Orthod Dentofacial Orthop 2008;133(4): 524-531)
# 분산분석 시 자주 범하는 오류
전체적인 분석을 하지 않고One-Way ANOVA + Independent t-test or Paired t-test
+ Mann-Whitney U test or Wilcoxon Singed Rank test
+ One-Way ANOVA 등 혼합하여 사용하는 경우Type I error가 증가한다.
이러한 경우에는 각 상황에 적합한 전체적인 분석을 해야 한다.
34
Ex)한 치과병원에서 칫솔질 방법과 시간에 따른 치태지수를
분석한 결과에 대한 연구에서, 각각의 칫솔질 방법과 시간에따른 치태지수에 차이가 없는지 검정하고자 한다.
방법(a)시간(b)
30초 1분 3분 5분
A 0.99 0.92 0.73 0.74
B 0.81 0.84 0.59 0.55
C 0.63 0.72 0.47 0.26
35
이원배치 분산분석
유의수준 0.05에서 기각역에 속하므로 칫솔질 방법과시간에 따른 치태지수의 차이가 있다고 할 수 있다.
( : 칫솔질 방법에 따른 치태지수는 차이가 없다.: 칫솔질 시간에 따른 치태지수는 차이가 없다.)
0H
0H
36
Method에 대한 일원배치 분산분석
유의수준 0.05에서 기각역에 속하지 못하므로칫솔질 방법에 따른 치태지수의 차이가 없다고 할 수 있다.
( : 칫솔질 방법에 따른 치태지수는 차이가 없다.) 0H
0H
Time에 대한 일원배치 분산분석
( : 칫솔질 시간에 따른 치태지수는 차이가 없다.)
유의수준 0.05에서 기각역에 속하지 못하므로칫솔질 시간에 따른 치태지수의 차이가 없다고 할 수 있다.

2013-06-22
7
9. ANCOVA (공분산분석)
9-1 정규분포와 등분산 가정도 검토한다.
9-2. 가정: 종속변수와 공변량은 선형성을 만족한다.공변량의 유의성을 확인 (p<0.05)
1) 공변량이 유의하면 4-3로 가시오.2) 공변량이 유의하지 않으면 ANCOVA를 할 수 없다.
(다른 방법 모색, RM ANOVA등)
9-3. 집단간 기울기 동질성 (Homogeneity of Regression Slopes) 가정 검정확인 방법: 종속변수와 공변량이 집단에 따라 같은지 통계적으로 검정.즉, 공변량과 집단간의 교호작용을 검정하여 유의하지 않으면(p>0.05) 동질한 것임.
1) 기울기가 동일하면 4-4으로 가시오.2) 기울기가 동일하지 않으면 4-5로 가시오.
9-4. 교호작용을 제거하고 주 효과의 유의성 확인 유의하면 사후검정
9-5. 각 집단에 따라 종속변수와 공변량의 관련성을 각각 추정해야 함. 각 집단의 기울기에 따라 조정된 종속변수로 집단 간 평균차이 검정
공분산 분석
분산분석과 마찬가지로집단간 차이를 검증하는 것이나
직접 통제하기 어려운 교란변인의 효과를제거 한 후 실시하는 분석방법
Ex)아래의 데이터는 20마리의 쥐를4마리씩 4개의 그룹으로 나눈 다음, 그룹에 따라 4개의 다이어트 프로그램을 시행하여시행 전과 시행 후의 몸무게를 측정한 것이다.
이 데이터에 대하여 시행 전 수치를 공변량으로 하고시행 후의 수치를 반응변수로 하여 공변량 분석을 시행하라.
시행 전의 몸무게는 차이가 났으나시행 후의 몸무게는 차이가 없었다.
등분산임을 입증 !
집단 간 기울기동질함을 입증!

2013-06-22
8
공변량(전)을 보정했을 때그룹에 따라 몸무게에 차이를 보인다.
만약, 공변량을 보정하지 않는다면그룹에 따라 몸무게의 차이가 보이지 않는다는
결론이 나온다.
사후분석 결과1그룹, 2그룹, 3그룹간에는 유의한 차이가 없었으나1vs4, 2vs4, 3vs4 그룹간에는 유의한 차이가 보였다.
회귀분석( Regression Analysis )
독립변수와 종속변수 사이의 인과관계에 따른수학적 모델인 선형적 관계식을 구하여
어떤 독립변수가 주어졌을 때,
이에 따른 종속변수를 예측하는 분석 방법
1) 종속변수와 독립변수의 산점도를 그려본다.※ 선형성을 보이지 않으면 변수변환 또는 비선형 회귀분석※ 이상치, 영양치 진단 및 다중공선성 체크
2) 오차 가정: 독립성, 정규성, 등분산성(1) 오차의 정규성: PP 도표와 QQ 도표 등으로 판단한다.
※ 정규성을 만족하지 않을 경우 변수변환 하여 분석
(2) 등분산성: 잔차와 예측치의 산점도가 이상이 없는지 확인※ 이상이 있다면 변수변환을 하거나 비선형 회귀 또는
새로운 설명변수를 추가하여 분석
3) 종속변수와 독립변수의 상관분석을 하여 종속변수에유의한 독립변수를 선택한다.

2013-06-22
9
4) 상관분석을 통해 얻은 독립변수들을 가지고 변수 선택법 을이용하여 최종모형을 선택한다.※ 독립변수가 범주형이면 더미변수를 이용
# 변수 선택법① 전진선택법 : 절편항만을 포함한 모형에서 시작하여 그 효과가 가장
유의 하다고 판단되는 설명변수를 하나씩 차례로 추가하는 방법② 후진제거법 : 모든 설명변수를 포함한 모형에서 시작하여 그 효과가 가장
유의하지 않다고 판단되는 설명변수부터 하나씩 차례로 제거하는 방법③ 단계적선택법 : 모형에 유의한 설명변수를 하나씩 추가하면서 남아있는 설명변수들
중에서 추가되는 설명변수로 인하여 필요 없게 되는 설명변수를제거하는 방법
5) 회귀계수에 대한 유의성을 확인하고 종속변수에 대한 영향력을비교한다.※ 독립변수끼리 비교는 표준화된 회귀계수를 이용
6) 결정계수를 확인하여 모형의 설명력을 확인한다.
상관분석(Correlation Analysis)
1) Pearson 상관분석두 변수가 연속형 일 경우 사용※ 데이터의 분포가 이상치의 영향을 많이 받을 경우에는
이상치를 제거하여 분석하거나 Spearman 상관분석을
하는 것이 바람직하다.
2) Spearman 상관분석둘 중 한의 변수라도 순위변수이거나 비모수인 경우 사용
51
Ex)연구자가 DEET(치의학전문대학원 입학시험)와 TEPS(영어
능력 검증시험)의 관계를 연구하고자 한다. IQ가 이들의 관련성에 어떻게 영향을 미치는지 알아보고자 편상관 계수를구해보기로 결정하였다.
상관계수 편상관계수
Part II
종속(반응)변수가 범주형 변수인 경우
test( 카이제곱 검정)2
•범주형 자료로 구성된 분할표에서변수간의 연관성을 검정할 때 사용
•cell의 20%에 기대빈도가 5이하인 셀이 있을 경우→ Fisher’s Exact test 시행 (2*2 에서만 가능)→ Freeman-halton extension of the Fisher’s
exact test (2*3 이상인 경우)
• Trend 카이제곱 검정 : 범주가 순서형일 경우에 사용
성공 실패
남자
여자
2X2 분할표
54
Odds Ratio (OR)
a b
c d
Disease
Yes No
Exposure Yes
No
Odds Ratio = bc
ad
db
caOR
/
/
OR : 위험요인을 가진 그룹이
위험요인을 가지지 않은 그룹에 비해
질병에 걸릴 위험이 OR(=2:예) 배만큼 존재한다.

2013-06-22
10
Logistic Regression Analysis
종속변수는 범주형 (이분형, 순서형, 명목형) 일 때,
독립변수는 연속형, 범주형일 경우 사용 가능하다.
1) 각각의 독립변수와 종속변수 간에 Logistic Regression을해보고 p <0.25*인 변수를 선택한다. (* Am J Epidemiology)
2) 1)에서 선택된 독립변수를 변수선택법으로Logistic Regression Analysis를 다시 돌려 최종 모형을 구축한다.
3) Hosmer-Lamshow test로 최종모형의 적합성을 검정한다.(p>0.05 인 경우 모형 적합)
4) 오즈비(Odds Ratio)를 해석한다. (유의한 변수에 한하여)
GEE(Generalized Estimating Equations)
임플란트 성공/실패에 대해어떤 요인이 유의한 영향을 주는지 알아보기 위해한 사람에게 임플란트를 한 개씩 식립 하였을경우에는 독립성이 위배되지 않아 Logistic regression이 가능하지만,
그렇지 않은 경우에는 독립성이 위배되므로한 개체에 여러 개의 임플란트를 식립하여 얻어진clustered data에 대하여 GEE를 사용해야 한다.
(분석법: 문헌참고)
57 58
59
참고문헌
1. 강동완, 서윤암, 오남식, 임회정. 대한치과보철학회지에서 볼 수 있는 통계적 오류의 고찰(2006-2010). 대한치과보철학회지 2012;50(4):258-270.
2. 임회정. SPSS를 이용한 치의학 통계입문 및 자료분석 I.나래출판사.

2013-06-22
11
Further statistical methods
• Survival data analysis (Cox PH model)
for implant study
• Mixed effect model for repeated measures
• GEE for clustered binary outcomes
• Systematic review and Meta analysis
for combining results from different studies
• 3-dimensional data (x,y,z) analysis
61
Thank you for your attention !
62